我們做過的專案中,有一個是基於 CDP 中的 Spark 2,存取 Hadoop 中的大量資料交易資料,運算、整理成防洗錢系統 (AMLS) 所需的交易紀錄。
這樣的情境涉及相當大量的資料,資料筆數都是在千萬級以上。也因此,Spark 執行時也需要相當大量的資源,並耗用相當長的時間。
在這個過程中,維運人員不可能盯著 Spark 的程式在執行,而執行時,Spark 也不會傳回細部的作業日誌。很偶爾的時候,會發現怎麼這個 job 跑了很久,最後默默地死掉了。
因此,本篇來說明,在 CDP 中,該怎樣來調查 Spark 的問題。
原本預期約一個小時可以執行完的 Spark job,卻執行了兩、三個小時之久,最後竟然還自己失敗了。
而在啟動 job 的主機上,常常只看到最後的 stack trace,或甚至是什麼也沒有就結束,因此常常無法進一步了解事情發生的地方。
由於 Spark 在使用 cluster mode 執行時,會將自己完全交由 CDP 的 YARN 來配置資源。YARN 會選擇一個 worker node 作為 driver,此外則依設定的數量,選取其它的 worker node 作為 executor。因此,Spark 一旦失敗了,在執行的主機上可能只能看到最後的 stack trace,而無法進一步追蹤 Spark 執行了什麼步驟。
在 CDP 上,我們有兩個方式可以取得 Spark 執行過程的日誌,第一是 Spark 的 History Server,可以用在已經結束的 Spark job 的日誌調查。Spark History Server 怎樣進去呢?
從 CM 上,點進 Spark,然後在右上角點出它的 Web UI - Spark History Server
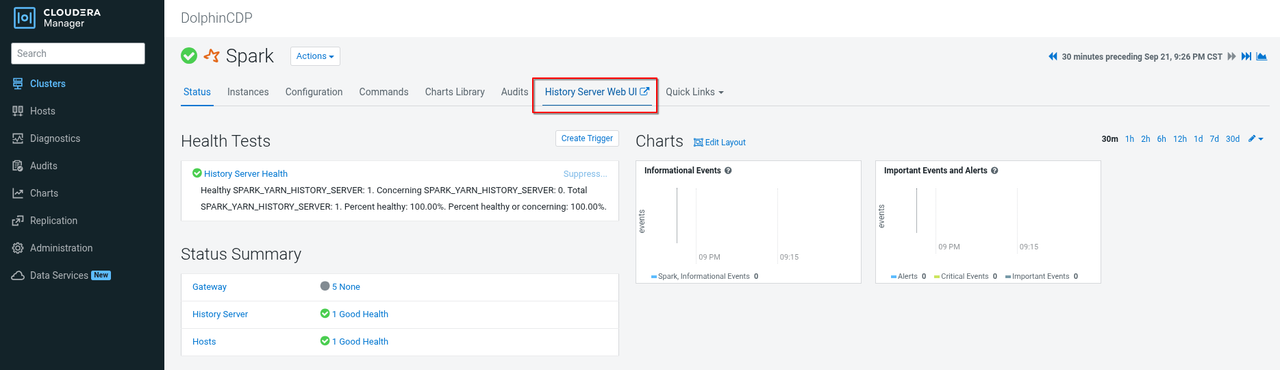
進去後,依 job 的時間點,或者找到在開發時,createSparkSession() 當下給的 appName 就能找到自己的 job。

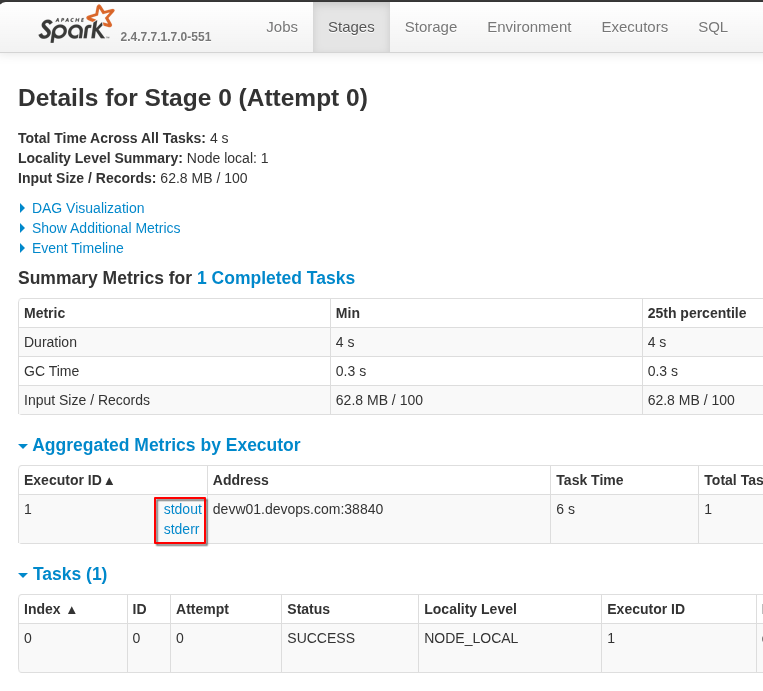
進入這個 job 之後,可以點選任一 stage,並且點開它的動作步驟後,可以發現 stdout 與 stderr 這兩種 log,通常 Spark 執行時主要的 log 都會在 stderr,因此點開 stderr 後,就可以看見完整的 log 內容。
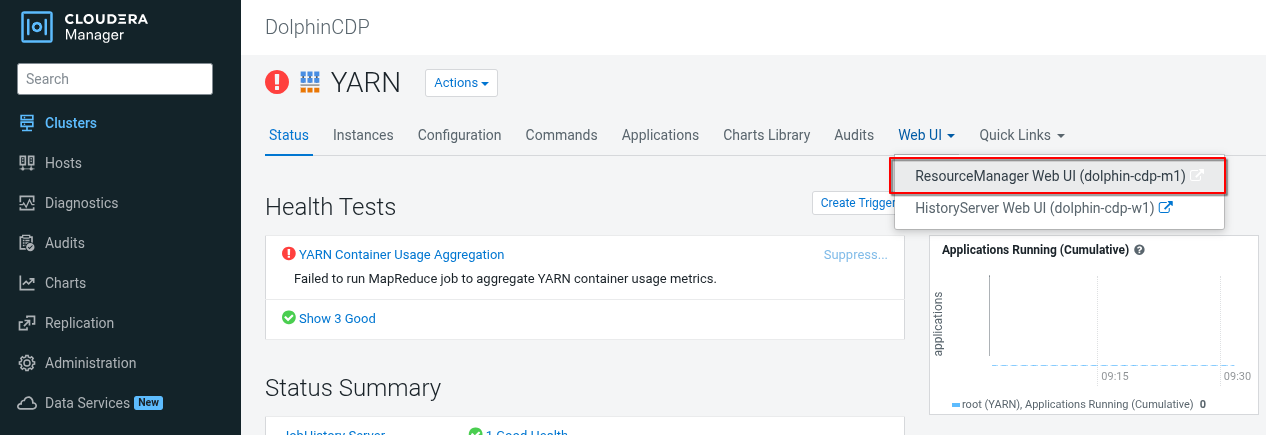
第二個方法,是更高層次的 YARN Resource Manager 畫面,同樣在 CM 中,點進 YARN,並在右上點開 Resource Manager 的 Web UI。
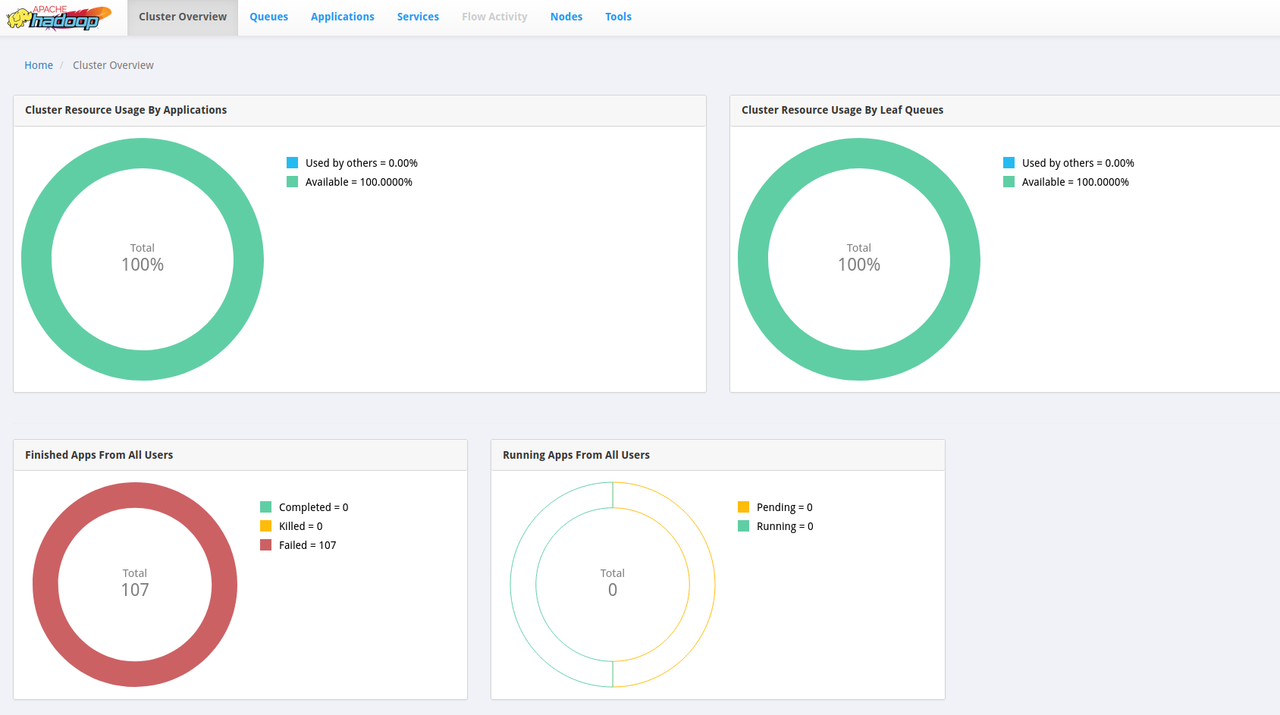
開起來畫面應該會是這樣:
但如果 CDP 有把 Kerberos 認證開好開滿,這個連結點開常常會是 HTTP 401 的錯誤:

如果為了便於錯誤調查,這些頁面的 Kerberos 認證可以先關掉:
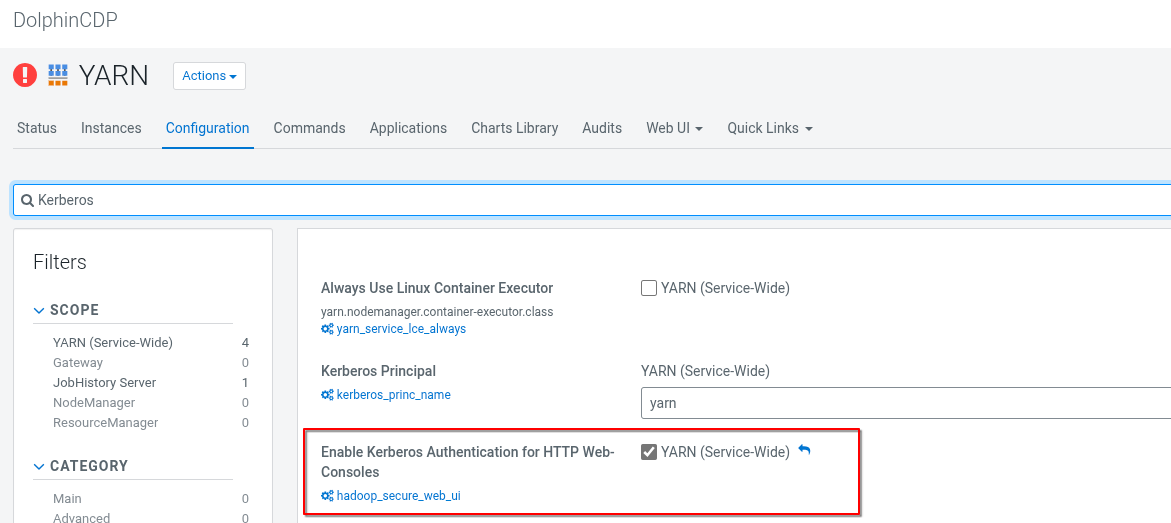
如果無法關閉,則需取得 Kerberos 的 ticket,並設定瀏覽器可使用 Kerberos 認證的機制。
在這個畫面,除了可以看到已經執行結束的 job,也能看到正在執行的 job,而且不只是 Spark 的 job,連 Hive、HDFS Replication 等類型的 job 都能查看。
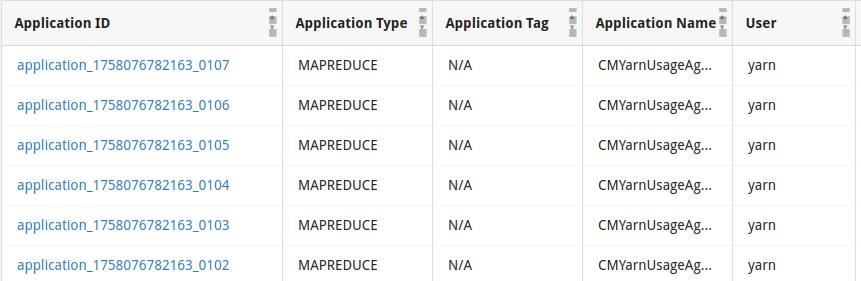
點進要檢查的 Spark job 之後,可以進一步點進 Logs 這個分頁,左側的 attempts 是指 YARN 跑了幾次這個 job,預設會執行兩次,兩次都失敗就是真的失敗了。
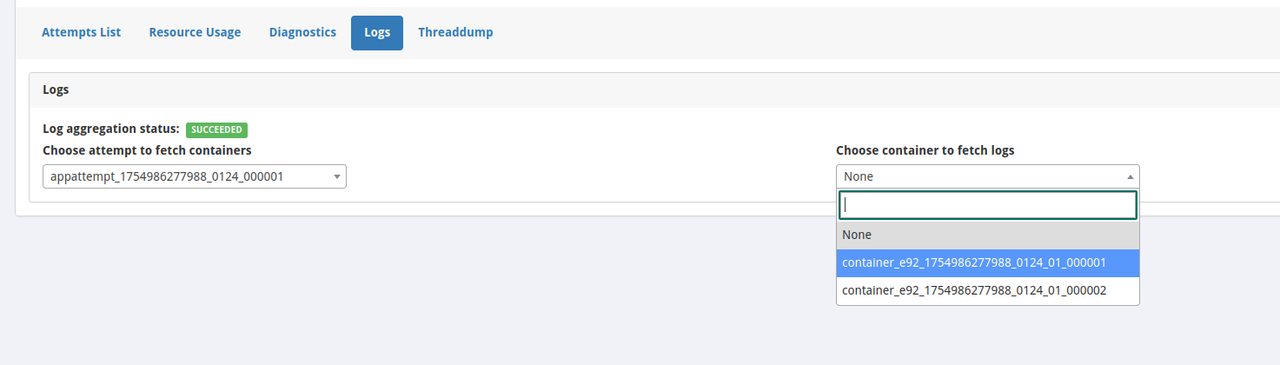
右側的 containers 不是 Docker container 的意思,而是在 YARN 來看,用來執行 job 的基本單位,其實一個 container 也就是一台 worker node,如果在 container 裡看到三個,那意味著其中一個 (通常是第一個) 是 driver,其它的是 executors,像這例子,一個是 driver,一個是 executor:
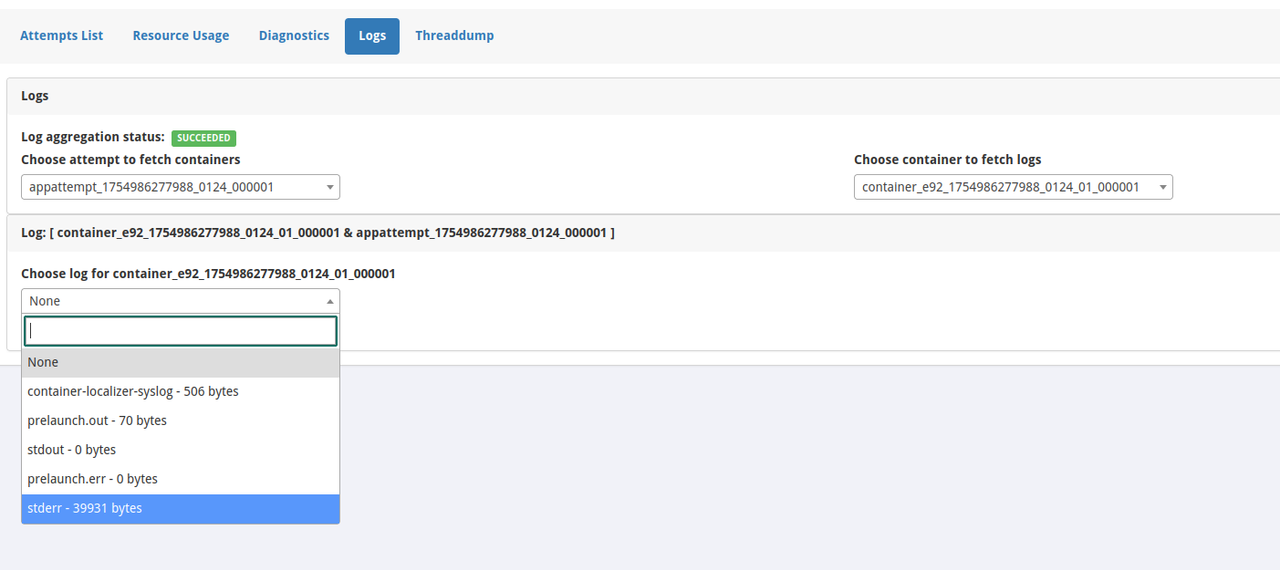
選擇 container 之後,就能在下方看到有各種 log 的選項,同上述的方式,選擇 stderr 的 log,就能看見 Spark 在執行過程中的所有紀錄了!


 iThome鐵人賽
iThome鐵人賽