很多甲方的單位,對系統環境的使用者操作紀錄都會有規範,要求其稽核日誌應該存放到一定的年限。在 CDP 裡面,也有個服務用來紀錄使用者的操作稽核軌跡。我們會使用它的日誌來進一步分析資料倉儲的使用情況,還有使用者的使用方式。
但怎麼分析呢?能分析到多久前的資料呢?
客戶的叢集維運單位希望調查 Hive 中,哪些資料表已經久久沒有人使用,以及平常使用者都會使用哪些資料表,以及大致上的使用情況。
然而,在Ranger Admin UI 上面,針對 audit log 能查詢的資料很有限,希望能夠查詢更深入的內容。
由於 Ranger 的 audit log 是以 JSON 格式儲存,要查詢其內容,CDP 透過 Solr 這個全文檢索服務,對 90 天內的 audit log 建索引 (CM 預設值)。
而客戶單位先前碰到 Solr index 資料量爆增,導致 Ranger 失效的問題後,便縮短了 Solr 的索引天數,也影響了在 Ranger Admin UI 上所能查詢到的天數。
為了處理這樣的查詢,首先我們需要有一個高效的查詢引擎,我會建議使用 DuckDB,然而 DuckDB 雖然沒有帶入任何相依性,但它還是會相依較高版本的作業系統底層套件,執行時需注意。
由於 DuckDB 無法直接伸手進 HDFS 裡執行查詢,因此需要把 audit log 從 HDFS 裡抓出來到外部的主機上。這部份就需要準備足夠的空間才能放置。
由於 Ranger audit log 的位置放在 HDFS 的 /ranger 這個目錄下,我們可以用 -du 這個指令來看目錄大小:
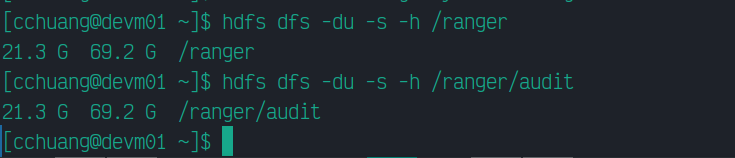
在 /ranger 目錄下,通常只會有一個 /audit 目錄,audit log 會依 Ranger 上各個權限控管的模組放在這裡。因此,/ranger/audit 這個目錄會比較精準,我們也會需要從這個目錄中查詢。
接著我們需要在 /ranger/audit 目錄下,找到 Hive 的 audit log,它會放在 /ranger/audit/hive 之下,分別有 hiveMetastore 與 hiveServer2:

這兩者的差別在於,hiveMetastore 紀錄了 CDP 叢集上,每個向 Hive Metastore 查詢資料表結構的操作,不管是 Hive REPL 下的查詢,還是透過 Spark 進行查詢。因此,在 hiveMetastore 所紀錄的,是比較簡要的操作項目,如只標記出 SELECT、INSERT 之類的操作。
而 hiveServer2 則紀錄了使用 Hive REPL 或者是在 Hue 上透過 Hive 查詢引擎來執行查詢的細部動作,因此在此會紀錄完整的查詢動作,包含使用者下了什麼 SQL。
可依實際要查的細節程度,來決定要抓哪些 log 回來,畢竟紀錄得多,log 量也大,端看準備的空間有多少。
我們在此針對 hiveMetastore 來調查,因此我們再往下看一層,會發現就是依日期分別放置的 log 內容:
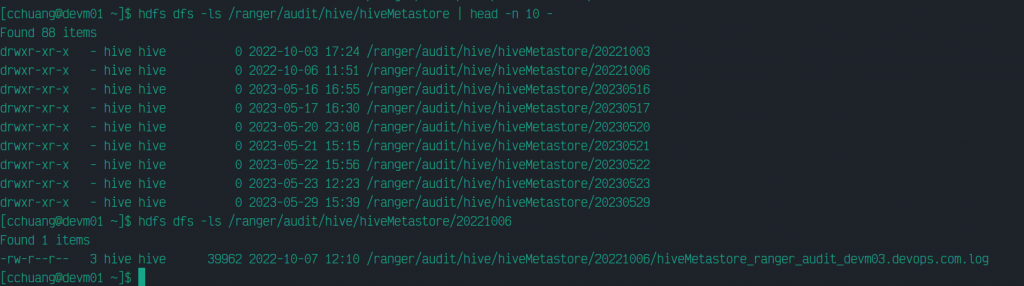
於是我們可以依要查詢的日期範圍,逐一把日期的目錄抓回某台主機上分析。
但 Ranger audit log 如何分析?
Ranger 的 log 格式可以參這份 文件 的說明,我們簡要地來對照事件調查時,所需的人事時地物等資訊:
| 項目 | 欄位 | 說明 |
|---|---|---|
| 人 | reqUser | 發出操作請求的使用者 |
| 事 | access | READ/WRITE/SELECT 之類的操作類型 |
| reqData | 在 hiveServer2 中,特指 SQL 的內容 | |
| action | 依各個模組的定義所設定的操作類型 | |
| policy | 使用者的操作觸發了哪一項管控政策的 ID | |
| result | Ranger 權限控管的結果,1 是通過,0 是拒絕 |
|
| enforcer | 這項管控是透過哪一個模組執行的 | |
| 時 | evtTime | 事件時間 |
| 地 | cliIP | 從哪個位置登入操作的 |
| 物 | resource | 使用者操作的對象,例如 HDFS 裡的路徑、Hive 裡的資料庫等 |
| resType | 資源的類型,如資料庫 (@database) |
理解欄位的意涵後,我們可以透過 DuckDB,將這些 *.log 檔案當作 JSON 檔查詢。DuckDB 查詢 JSON 的作法在此就不贅述囉!

