▋前言
在 Day 4–Day 8,我們逐一介紹了四大核心模組。今天要將這些模組整合起來,展示完整的 系統架構與資料管線,並透過流程圖呈現「從輸入到產出」的全貌。
▋內容
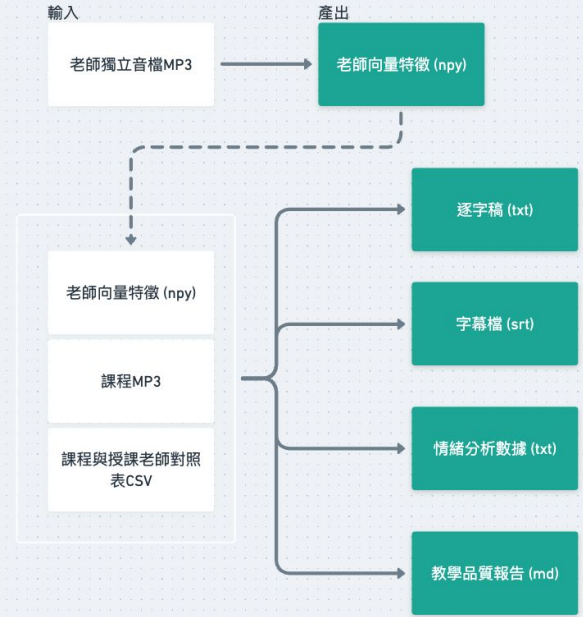
整個 Pipeline 的核心設計,是將不同的模組串接成自動化流程,讓原始音訊經過逐步處理後,轉換為結構化的數據與報告。(由於競賽時間限制,在報告的呈現方式上,我們直接運用Markdown輸出成果報告,讀者亦可以依照各自使用情境延伸發展出適合的展示方法。)
流程概述:
老師獨立音檔 (MP3)
課程錄音 (MP3)
課程與授課老師對照表 (CSV)
語音識別 (Whisper):將課程錄音轉成逐字稿。
語者分離 (NeMo):切分出不同講話片段。
語者識別 (pyannote + X-vector):比對老師與學生的聲紋特徵,標記發言角色。
情緒辨識 (Wav2Vec + SpeechBrain):分析學生語音情緒,輸出情緒曲線。
逐字稿 (txt)
字幕檔 (srt)
情緒分析數據 (txt)
教學品質報告 (md)
這樣的資料管線能夠實現:
從原始音訊到結構化數據的 全自動轉換。
產出可直接應用於教學檢視、學生複習與平台評估的報告。
系統在設計上模組化,方便後續替換與升級。
▋下回預告
下一篇將分享我們在開發過程中,如何優化系統並解決實務挑戰,例如重疊語音與情緒誤判問題。
▋參考資料
Whisper 語音模型
Whisper GitHub
NVIDIA NeMo
Speaker Diarization Using OpenAI Whisper
Robust Speech Recognition via Large-Scale Weak Supervision
NVIDIA NeMo speaker_diarization
A review on speaker diarization systems and approaches
pyannote.audio
X-VECTORS: ROBUST DNN EMBEDDINGS FOR SPEAKER RECOGNITION
X-Vectors: Robust DNN Embeddings for Speaker Recognition
SpeechBrain
Emotion Recognition from Speech Using Wav2vec 2.0 Embeddings
圖片源自競賽成果簡報

