!pip install -q sentence-transformers
from sentence_transformers import SentenceTransformer
#英文模型
model_en = SentenceTransformer("all-MiniLM-L6-v2")
#中文 / 多語模型
model_zh = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
3. 產生句子向量
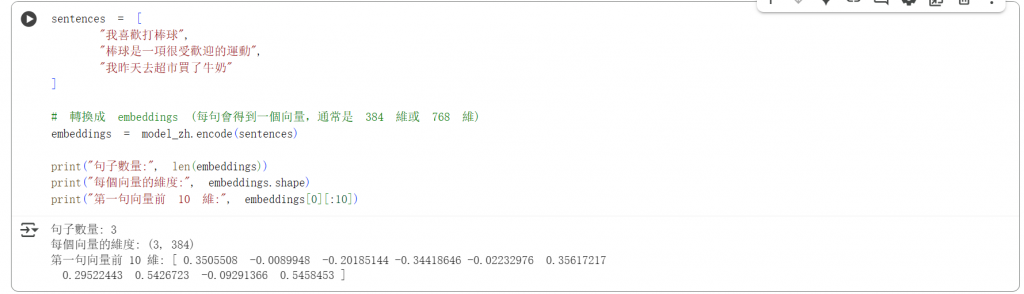
sentences = [
"我喜歡打棒球",
"棒球是一項很受歡迎的運動",
"我昨天去超市買了牛奶"
]
#轉換成 embeddings (每句會得到一個向量,通常是 384 維或 768 維)
embeddings = model_zh.encode(sentences)
print("句子數量:", len(embeddings))
print("每個向量的維度:", embeddings.shape)
print("第一句向量前 10 維:", embeddings[0][:10])
4. 計算相似度
from sentence_transformers.util import cos_sim
sim_matrix = cos_sim(embeddings, embeddings)
print("相似度矩陣:")
print(sim_matrix)

5. 印出比較結果
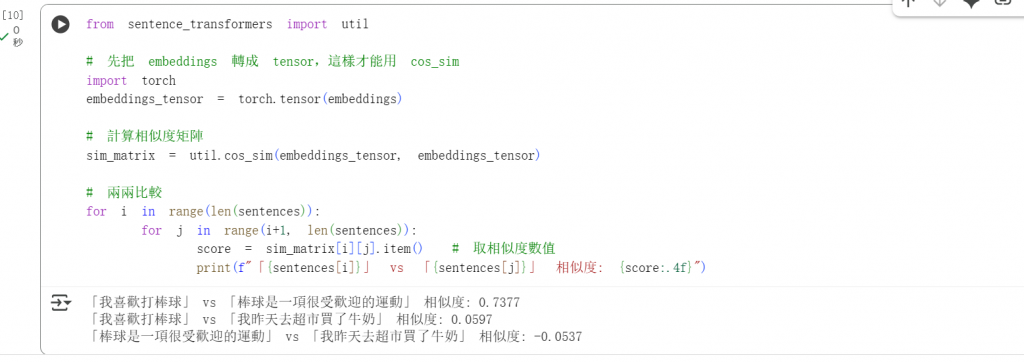
from sentence_transformers import util
#先把 embeddings 轉成 tensor,這樣才能用 cos_sim
import torch
embeddings_tensor = torch.tensor(embeddings)
#計算相似度矩陣
sim_matrix = util.cos_sim(embeddings_tensor, embeddings_tensor)
#兩兩比較
for i in range(len(sentences)):
for j in range(i+1, len(sentences)):
score = sim_matrix[i][j].item() # 取相似度數值
print(f"「{sentences[i]}」 vs 「{sentences[j]}」 相似度: {score:.4f}")


 iThome鐵人賽
iThome鐵人賽