
工程是科學,在我們對架構做出任何重大改動之前,必須先有客觀的數據作為決策依據。
在上一篇,我們實作了一個簡單但可靠的資料庫方案來處理搶票邏輯。
現在我們必須回答一個關鍵問題:這個簡單的方案,到底能撐住多大的流量?
今天,我們的目標只有一個:用一個簡單、可重複的方法,來量化上一篇解決方案的真實性能。
這份數據,將是我們判斷是否需要進入第二階段(引入 Redis)的唯一依據,也是我們後續所有優化的基準線。
在開始測試前,先明確我們要測量什麼。這能避免我們迷失在無關的數字裡。
| 指標 | 定義 | 為什麼重要 |
|---|---|---|
| 成功率 (Success Rate) | 請求成功的比例。區分 HTTP 200 (扣減成功) 和 409 (售罄,業務成功) | 確認業務邏輯正確,非系統失敗 |
| 延遲 (Latency) | 回應時間。關注 P50, P95, P99 | 顯示平均和極端負載下的用戶體驗 |
| 吞吐量 (Throughput) | RPS (Requests Per Second) | 系統處理能力的上限 |
| 錯誤率 (Error Rate) | HTTP 5xx、超時、連線失敗比例 | 識別真實的系統穩定性問題 |
你可能會好奇,為什麼我們要關注 P50, P95, P99,而不是簡單的「平均回應時間」?
讓我們用一個 100 人賽跑的比喻來解釋。這 100 人代表 100 次 API 請求,他們的完賽時間就是 API 的「延遲」。
P50 (中位數延遲): 第 50 名跑者的完賽時間。這代表了你一半用戶所感受到的速度,反映了系統的典型表現。
P95 (第 95 百分位延遲): 第 95 名跑者的時間。代表 95% 的用戶請求會比這個時間快。它反映了絕大多數用戶能體驗到的最差情況,是衡量服務穩定性的關鍵。
P99 (第 99 百分位延遲): 第 99 名跑者的時間。代表 99% 的用戶請求會比這個時間快。它暴露了系統中那些最倒楣的「極端個案」,通常被稱為長尾延遲 (Tail Latency),能幫你發現例如 GC 暫停、網路抖動等偶發性嚴重問題。
為什麼不用平均值? 因為平均值極易被極端值誤導。
假設 99 次請求耗時 10ms,但有 1 次耗時 1000ms,平均值會是 19.9ms,看起來很棒,卻完全掩蓋了那個 1 秒鐘的災難。而 P99 會誠實地告訴你,那個最差體驗是 1000ms。
| 指標 | 代表意義 | 回答的問題 |
|---|---|---|
| P50 | 典型體驗 (Median) | 「我的用戶通常感覺到的速度是多快?」 |
| P95 | 絕大多數用戶的底線體驗 | 「我的服務對大部分人來說,最差有多慢?」 |
| P99 | 最差情況下的體驗 (Tail Latency) | 「那些最倒楣的用戶會遇到多嚴重的延遲?」 |
關注百分位數,才能對系統性能有全面、立體的理解,而不是被一個美化的「平均值」所欺騙。
從簡單起步:用 hey 快速基準,用 k6 升級為可腳本化測試。
# macOS 用戶
brew install hey k6
# 其他系統用戶請參考 hey 和 k6 的官方文件進行安裝
我們的 API 是 POST /tickets/{id}/purchase-atomic,成功時返回 200 或 409。
執行:100 併發,總計 10,000 請求。
hey -m POST -c 100 -n 10000 http://localhost:8080/tickets/1/purchase-atomic
關注報告:


P95=0.1582s 表示有 95% 的請求在 158.2ms 以內完成,剩下 5% 更慢。這些數字不是平均(mean),用 P50/P95/P99 才能看出典型體驗與長尾表現。
k6 讓測試腳本化、可重複且可設定目標。
先讓本地資料庫放多一點的票卷張數,來觀察數據。
[{"id":1,"eventName":"演唱會A","quantity":1000000000}]
load.js
import http from 'k6/http';
import { check } from 'k6';
export const options = {
vus: 100, // 虛擬用戶數 (Virtual Users),相當於併發數
duration: '60s', // 測試持續時間
thresholds: {
// 定義測試通過的標準
'http_req_failed': ['rate<0.01'], // 系統錯誤率必須小於 1%
'http_req_duration': ['p(95)<200'], // 95% 的請求必須在 200ms 內完成
},
};
export default function () {
const url = 'http://localhost:8080/tickets/1/purchase-atomic';
const res = http.post(url, null, { headers: { 'Content-Type': 'application/json' } });
// 檢查業務是否成功 (HTTP 200 或 409 都算成功)
check(res, {
'is success (200 or 409)': (r) => r.status === 200 || r.status === 409,
});
}
執行測試:
k6 run load.js
跑完結果報告會明確告訴你 thresholds 和 check 是否通過。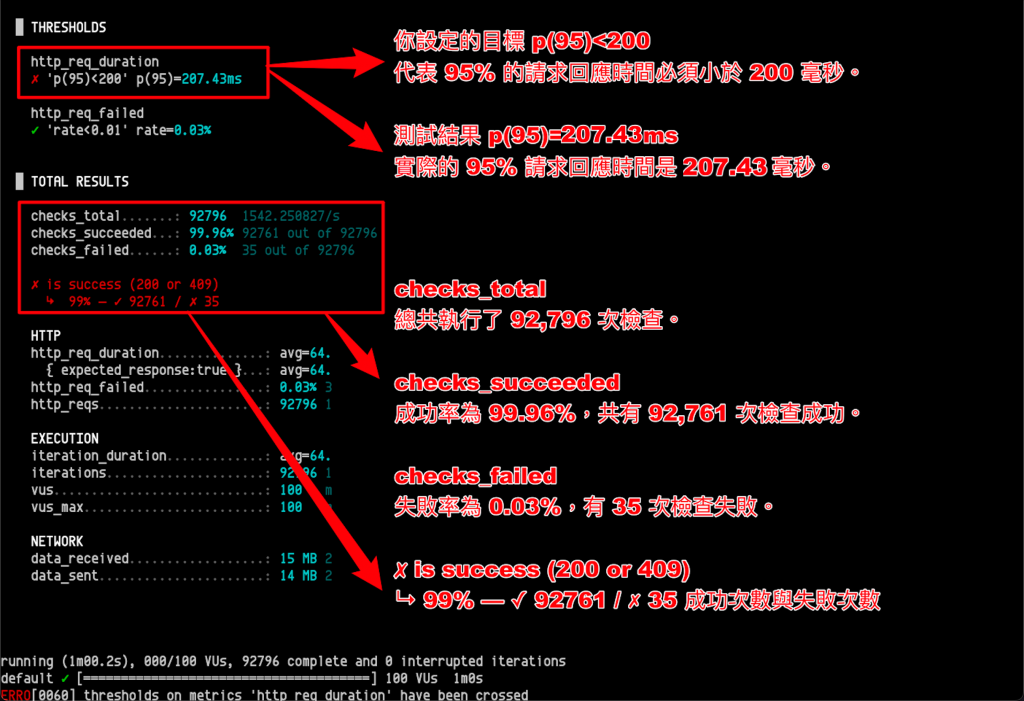
這個結果顯示,在 100 個虛擬用戶的壓力下,你的服務有極高的成功率,只有少數請求沒有返回預期的 200 或 409 狀態碼。
控制單一變量:一次只改一項設定(例如,只增加併發數,或只修改連線池大小)。
系統預熱:先讓測試運行 30 秒到 1 分鐘,讓系統(JIT 編譯、快取等)進入穩定狀態後,再開始採計數據。
數據一致性:測試前,確保資料庫庫存足夠(例如設為 10 億),避免因提前售罄導致測試中斷。
監控伺服器:測試期間,請務必同時監控被測伺服器的 CPU 和記憶體使用率,以判斷瓶頸所在。
記錄環境:完整記錄測試時的硬體規格、作業系統、資料庫版本、Go 版本、連線池設定,以及對應的 Git commit hash。
[ ] 測試腳本 (hey 命令或 k6 load.js) 已提交到 Git。
[ ] 第一次的基準測試報告已截圖或以 JSON 格式 (hey -o json) 保存。
[ ] 測試環境的完整記錄已保存。
[ ] 確認已將 HTTP 409 視為業務成功,而非錯誤。
[ ] 確認測試時遵循了「單一變量」和「系統預熱」等原則。
[ ] 已監控並記錄伺服器的 CPU、記憶體、網路和磁碟 I/O 使用率。
hey 和 k6 讓測試從混亂變科學。壓力測試已經完成,現在我們手中有了一份可靠的數據。
這些數據告訴了我們什麼?
我們的資料庫方案在什麼樣的 QPS 下開始出現瓶頸?
在下一篇我們將根據今天得到的數據,進行分析瓶頸是出現在 CPU、I/O 還是鎖競爭,並用數據來決定是否需要引入 Redis 這樣的快取層。

