
在上一篇,我們的壓力測試在 1500 RPS 時撞牆了。
根本原因是資料庫為了保證資料的正確性,在單一熱點資料上產生了鎖競爭。
今天,我們來深入探討這堵牆的本質。
它不是資料庫的「錯」,而是它恪守其最重要承諾所付出的物理代價。
這是電腦科學中關於權衡 (Trade-offs) 的工程學科。
資料庫之所以慢,不是因為它「笨」,而是因為它對你做出了一個神聖的承諾:ACID 中的 D - Durability (耐久性)。
這個承諾意味著,一旦資料庫告訴你「交易成功」,那麼即使下一毫秒機房斷電、伺服器爆炸,資料也必須完好無損地存在於磁碟上。
為了兌現這個承諾,它必須執行這個世界上最慢的操作之一:將資料同步寫入磁碟 (fsync)。
所有性能問題的根源,都來自於下面這個簡單的事實:
在 CPU L1 快取中操作: ~1 奈秒
從主記憶體 (RAM) 讀寫: ~100 奈秒
將 4KB 資料同步寫入 NVMe SSD: ~15,000 - 50,000 奈秒 (15-50 微秒)
從記憶體到磁碟,有數百倍的鴻溝。
每一次 UPDATE,資料庫都必須跨越這條鴻溝,把交易日誌(WAL/Redo Log)刷到磁碟上。
而資料庫,為了保證你的交易在斷電後依然存在 (ACID 中的 D),它必須把交易日誌 (WAL/Redo Log) 寫入磁碟。
每一次 UPDATE,無論多小,都至少觸發一次昂貴的「出門開車」操作。
我們看到的 207ms P95 延遲,本質上就是成千上萬個請求,排隊等待跨越這條鴻溝的成本總和。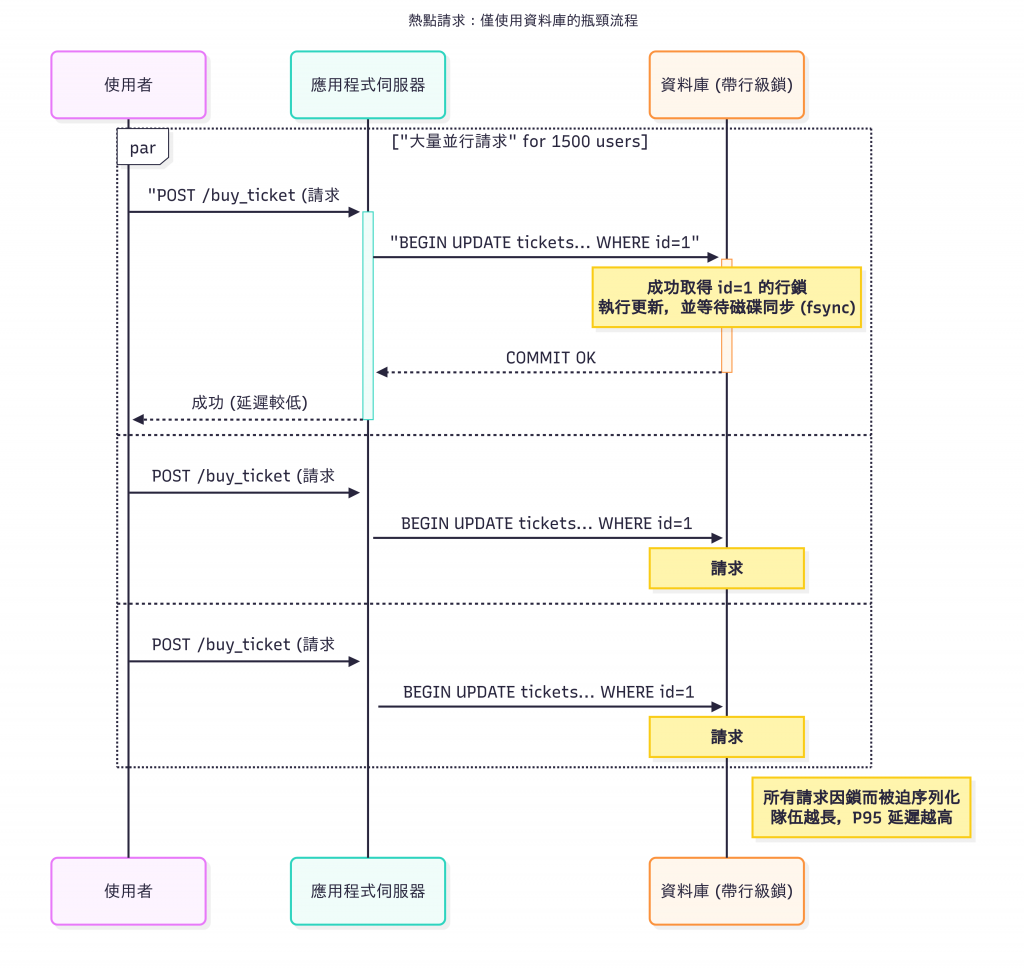
我們的搶票請求,有 99.99% 的時間都在做同一件事:
UPDATE tickets SET quantity = quantity - 1 WHERE id = 1;
成千上萬的請求,都在毆打同一筆資料(讀寫同一筆資料),這筆資料被稱為熱點 (Hotspot)。
為了保證庫存不會被超賣(I - Isolation 和 C - Consistency),資料庫必須上一個行級鎖 (Row-level Lock)。
上鎖是唯一正確的事情。
但它的副作用是災難性的:強制序列化 (Serialization)。
你發起了 1500 個並行請求,但在資料庫的熱點資料面前,它們被迫排成一條長隊,一個一個來。並行的優勢在這裡蕩然無存。
隊伍越長,排在後面的人等待的時間就越久。這就是為什麼 P95 延遲會失控。
我們面臨的困境是:
我們需要原子性來保證庫存正確。
資料庫透過鎖 + 磁碟 I/O 來提供最強的原子性和持久性保證。
這套機制的物理極限,在我們的熱點場景下就是 1500 RPS。
結論不是「資料庫是垃圾」,而是 「我們不能在要求強持久性的戰場上,進行一場需要極高吞吐量的閃電戰」。
我們需要一個不同的模型,這個模型必須誠實地做出權衡:我們願意犧牲一部分持久性的保證,來換取數量級的效能提升。
這才是我們引入 Redis 的真正原因:
基於記憶體: 徹底擺脫了磁碟 I/O 的枷鎖。
單執行緒模型: 從根本上避免了複雜的鎖競爭問題,所有命令天生就是序列化的。
原子指令: 提供了像 DECRBY 這樣專為計數器場景設計的、極度高效的原子操作。
我們不是用 Redis 取代 資料庫。
我們是把它當作一個承受衝擊的高速前置處理器 (High-Throughput Pre-processor)。
資料庫 依然是 「記錄系統」 (System of Record),是資料的最終真理。
Redis 則是 「交戰系統」 (System of Engagement),處理所有高併發的即時請求。
但這個新架構帶來了新的、必須回答的問題:
如果 Redis 掛了怎麼辦? 放在記憶體裡的資料會瞬間消失。我們必須啟用 Redis 的持久化機制,AOF 配置為 everysec。意思是:「我們可以接受在災難發生時,遺失最多一秒鐘的資料」。
資料如何同步回資料庫? 在 Redis 中 DECRBY 成功後,必須有一個可靠的機制去更新資料庫。
一個常見的做法是,應用程式在操作 Redis 後,將一個「更新庫存」的任務放入一個持久化的訊息佇列 (Message Queue) 中,由一個後台消費者慢慢地、批量地更新資料庫。
如何保證資料最終一致? 需要有對帳 (Reconciliation) 程序。
在搶票結束後,需要有一個工作來核對 Redis 的最終庫存和資料庫中的記錄,確保沒有偏差。
這是一個需要改變架構和接受權衡的工程問題。
把熱點庫存計數從資料庫移到 Redis,是因為可以用記憶體的效能,並有能力處理隨之而來的持久化和一致性挑戰。
下一章,我們就來正式認識這位,Redis。

