
我們現在所建立的 AI 工具,基本上就只是呼叫 LLM 模型,然後請他回答問題,他事實上就大約是 2 ~ 3 年前 chat-gpt 剛出來的那樣,但是還有加上一些 Workflow。
接下來你會發現有很多事情它都不知道,例如最常見到的例子就是問天氣之類的,如果你問他台北天氣現在是什麼,他那時應該是會說不知道。
而這個就是我們今天有講的主題Function Calling。
大約在 2023 年時 OpenAI 提出了 Function Calling,最初的目的就是為了 :
讓 LLM 可以與外部介接,並且可以拿到外部的資料。
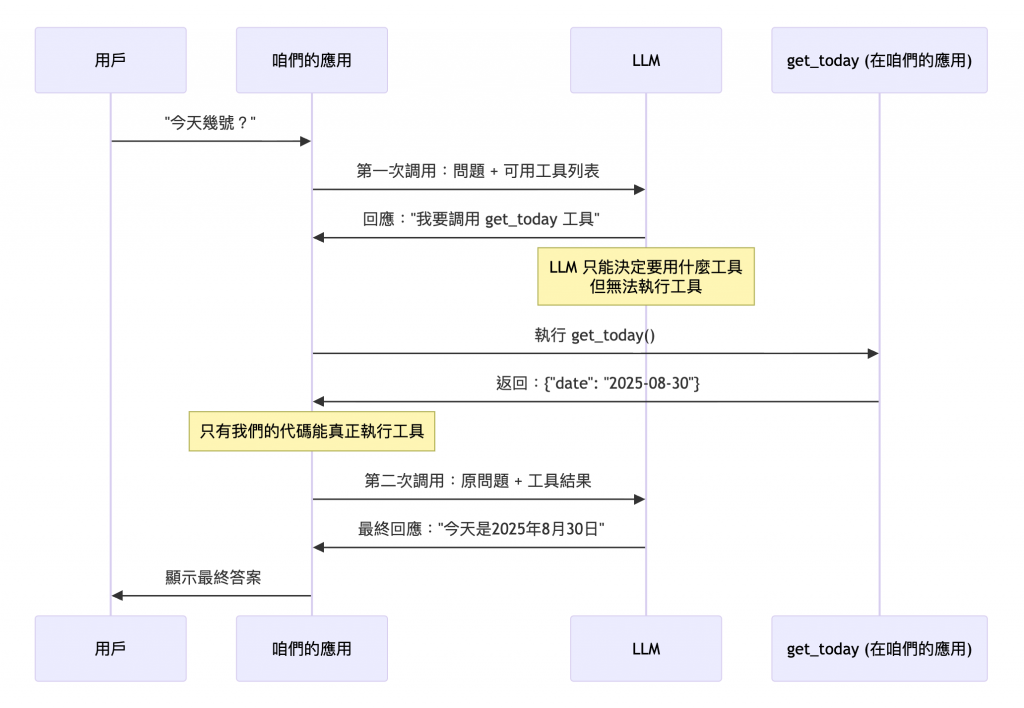
下圖是以我們要取得現在時間來當做它的範例,來說明他的流程。順到說一下這個功能真的有用,你有時後直接問 AI,他都會回奇怪的時間給你,像如果你用 gpt-4o-mini 每一次都給你很奇怪的時間,但 gpt-5 後就看起來都是正確的,反正這個只是範例。
然後還有幾個重點 :
- LLM 不會幫你執行 Function,而是只和你說用那個 Function
- 有沒有 Function Calling 的功能要看 LLM 有沒有提供
🤔 奇怪 ? 為什麼我用 LangChain 和 OpenAI SDK 這些可以直接回時間給我 ?
因為你用的是 Agent 或是 SDK 有自已實作,所以如果你只是單純的如下程式碼這樣 :
import OpenAI from "openai";
const client = new OpenAI();
const getWeather = async (city: string): Promise<string> => {
return `The weather in ${city} is sunny!`;
};
const tools: OpenAI.Chat.Completions.ChatCompletionTool[] = [
{
type: "function",
function: {
name: "get_weather",
description: "Get the weather for a given city. ex. Q:what is the weather in taipei? A:The weather in taipei is sunny!",
parameters: {
type: "object",
properties: {
city: {
type: "string",
description: "The city to get weather for"
}
},
required: ["city"]
}
}
}
];
const response = await client.chat.completions.create({
model: "gpt-5-nano",
messages: [
{ role: "user", content: "what is the weather in taipei" }
],
tools: tools,
tool_choice: "auto"
});
console.log("Initial response:", response.choices[0].message.tool_calls);
然後我們的 console log 的結果就會如下,他就只會和你說要呼叫那個工具 :
Initial response: [
{
id: 'call_TSt3nZvE8lCmJ6tCoLaGhc82',
type: 'function',
function: { name: 'get_weather', arguments: '{"city":"taipei"}' }
}
]
所以這裡幾點重點在於 :
像如果你在 LangChain 用 createAgent 產生,那他會自動幫你呼叫,而用 Gemini SDK Python 版本的它也會幫你自動呼叫,例如下面的連結。
https://ai.google.dev/gemini-api/docs/function-calling?hl=zh-tw&example=meeting#javascript_2
以下為 LangChain 的程式碼範例,由於 LangChain 的 createAgent 本身產出的 React Agent,所以他會自動的呼叫 tool 來執行。
https://docs.langchain.com/oss/javascript/langchain/agents
import { createAgent, tool } from "langchain";
const getCurrentTime = tool(
async () => {
return new Date().toISOString();
},
{
name: "get_current_time",
description: "Get the current time.",
}
);
const agent = createAgent({
model: "openai:gpt-5-nano",
tools: [getCurrentTime],
});
const result = await agent.invoke({
messages: [{ role: "user", content: "今天幾號" }],
});
console.log(result);
執行的結果,可以看出他整個流程是 :
{
messages: [
HumanMessage {
"id": "9b7518d0-f8e1-451a-ad66-669cd481e567",
"content": "今天幾號",
"additional_kwargs": {},
"response_metadata": {}
},
AIMessage {
"id": "chatcmpl-CKJWCOelT9iEGqtTK8U30IpH1ZFjC",
"content": "",
"name": "model",
"additional_kwargs": {
"tool_calls": [
{
"id": "call_ry3Rc1pvI9XidWFgKm6Pfilh",
"type": "function",
"function": "[Object]"
}
]
},
"response_metadata": {
"tokenUsage": {
"promptTokens": 128,
"completionTokens": 600,
"totalTokens": 728
},
"finish_reason": "tool_calls",
"model_provider": "openai",
"model_name": "gpt-5-nano-2025-08-07"
},
"tool_calls": [
{
"name": "get_current_time",
"args": {
"input": ""
},
"type": "tool_call",
"id": "call_ry3Rc1pvI9XidWFgKm6Pfilh"
}
],
"invalid_tool_calls": [],
"usage_metadata": {
"output_tokens": 600,
"input_tokens": 128,
"total_tokens": 728,
"input_token_details": {
"audio": 0,
"cache_read": 0
},
"output_token_details": {
"audio": 0,
"reasoning": 576
}
}
},
ToolMessage {
"id": "23c36162-247f-4dec-9863-75e6881ab0ea",
"content": "2025-09-27T07:20:26.774Z",
"name": "get_current_time",
"additional_kwargs": {},
"response_metadata": {},
"tool_call_id": "call_ry3Rc1pvI9XidWFgKm6Pfilh"
},
AIMessage {
"id": "chatcmpl-CKJWH4F0ZighUiqP0CyFpiOtj4dtp",
"content": "今天是 2025 年 9 月 27 日。若以你所在的時區,時間可能會有差異。需要我幫你換算成你的時區嗎?",
"name": "model",
"additional_kwargs": {},
"response_metadata": {
"tokenUsage": {
"promptTokens": 174,
"completionTokens": 498,
"totalTokens": 672
},
"finish_reason": "stop",
"model_provider": "openai",
"model_name": "gpt-5-nano-2025-08-07"
},
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"output_tokens": 498,
"input_tokens": 174,
"total_tokens": 672,
"input_token_details": {
"audio": 0,
"cache_read": 0
},
"output_token_details": {
"audio": 0,
"reasoning": 448
}
}
}
]
}
下面這些 Best Practice 是我自已融合 OpenAI 與 Google Gemini 產生的,可以參考看看,但不一定要服用。
最小驚訝原則 PLA,簡單的說就是你的 function 的命名與介面儘量直覺點,不要讓維護者看到你寫的 function 在想這個要衝啥小。❗關於 Temperature 的備註:
但是在 GPT-5 以後好像就不在提到 Temperature 的調整了,主要是為了穩定。
🤔 不要讓同一個 Agent 塞那麼多 tool,那要如何處理呢 ?
事實上這題我們之前就有解過,只是他不是為了解 tool 這題,我們用的手法就是 :
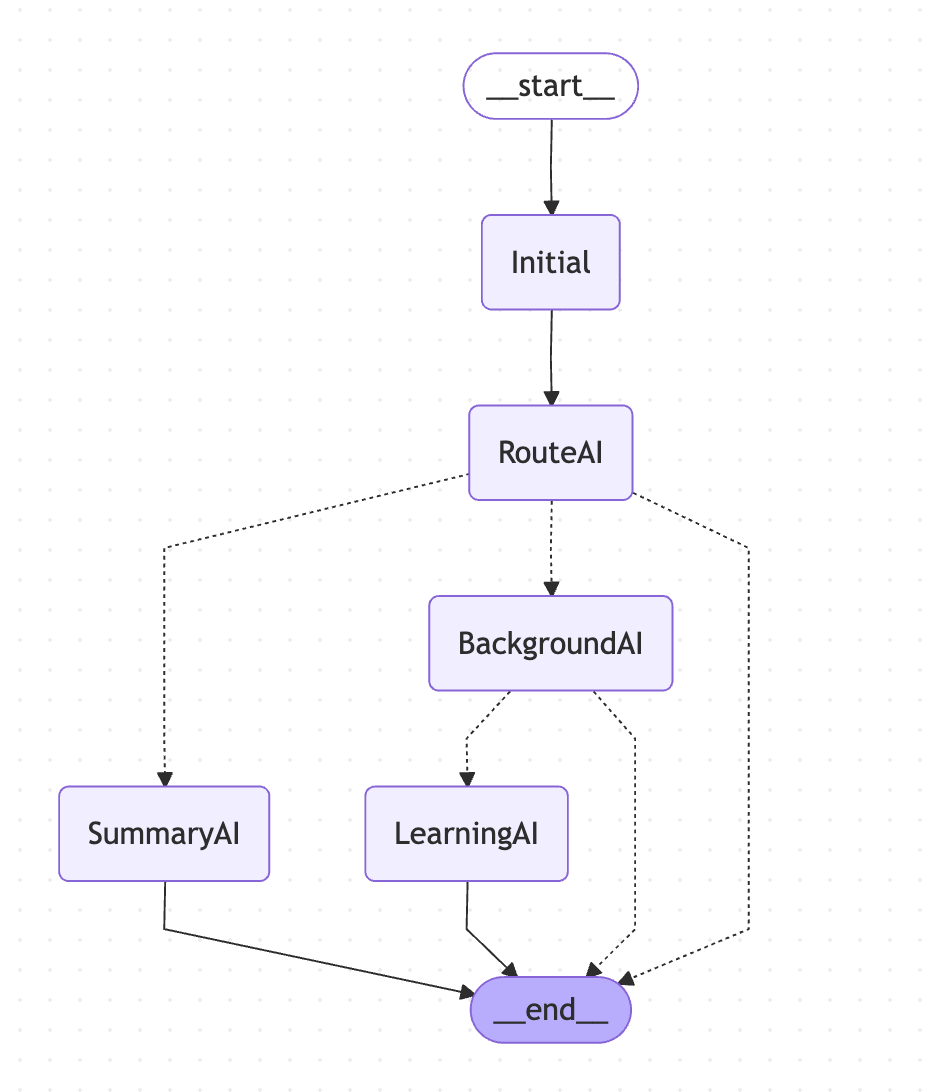
每個 Agent 都有各自的職責,然後前面有一個 Route Agent
如下圖,我們是不是可以將這些 tool 放在各自職責的 Agent 中呢 ? 對吧,可以省 Token、又可以讓 LLM 要使用更精確。
🤔 Function 內可以用 Cache 來優化效率與成本
都說是 function 了,實際上就我和我們常寫的 function 是相同的,所以當然如果你這個 function 是有處理一些很耗效能的東西,並且情況允許的話,當然可以使用。
有關 Cache 的一些問題可以看很久以前的這幾篇文章。
🤔 Function 的一些特殊設計重點
要有寡等性喔,這個應該很基本,就是不要,LLM 呼叫 2 次,最終狀態就有問題,例如使用者重複結帳相同商品的情況啊。要有 retry喔,如果是非 LLM Function Calling 我覺得就看用戶好不好 retry 與團隊政策,但在 LLM Function Calling 情境下,因為從 LLM 開始重試要花 token 所以在這種情況下,建議統一都有 retry 機制。這篇文章我們學習到了以下幾個重點 :
它的概念事實上蠻簡單的,只是要注意一些小事情,接下來我們用它來為我們的 AI 工具人增加一些新功能。

 iThome鐵人賽
iThome鐵人賽