
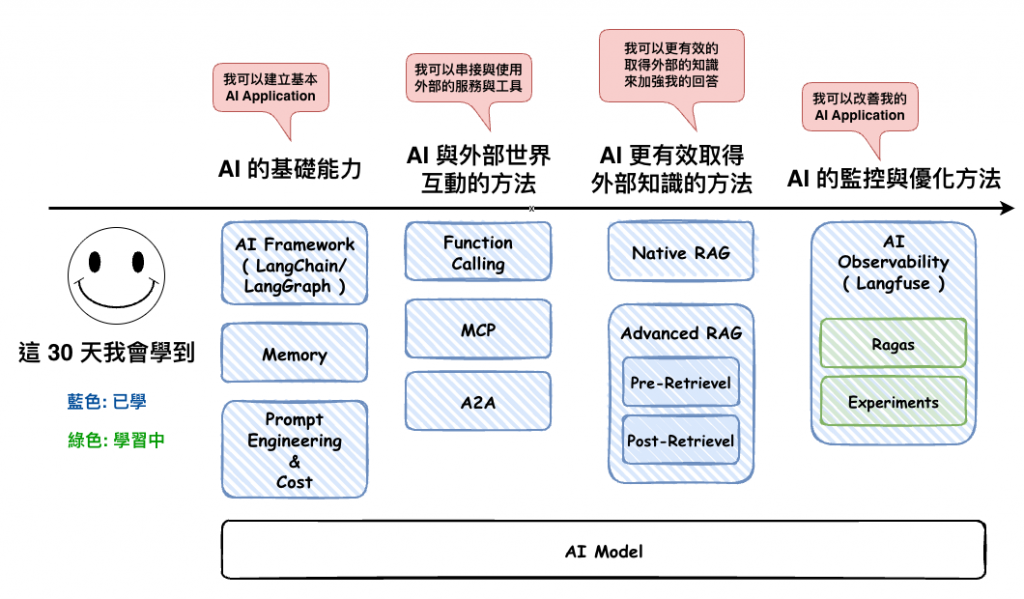
上一篇文章我們談論完 Evaluation 中的評估方式以後,接下來我們將要談論 :
評估指標
然後還記得我們前一篇文章在建立 Evaluator 時看到的這些有點難理解的英文單字嗎 ? 他就是我們今天要討論的主題。
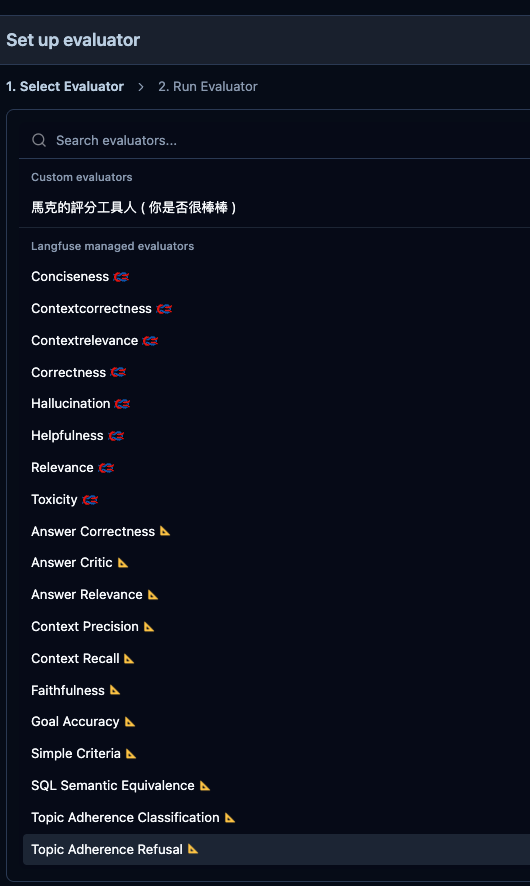
先說一下,我們這裡是根據上面 Langfuse 所提到的 Evaluator 來進行說明,然後每個 Evaluator 都有相對應的指標含義,所以我們才會這兩個一起說,不然很多文章是單獨說明指標。
接下在 Langfuse 會分兩個體系 :
然後我們今天的主題會是以Ragas為主,就是以下這一些。
Ragas 是一個開源用來評估 RAG 的工具,它提到了一系列標準化的指標來評估 RAG。
然後它裡面有很多 metrics,然後我們這裡很多東西就提在說明它的 metrics,如下連結。
https://docs.ragas.io/en/latest/concepts/metrics/available_metrics/
然後在 Langfuse 中的 Evaluator 有很多是由 Ragas 來維護的,然後它就是用這些指標來實現的,所以接下來我們就要來理解理解它。
然後順到說一下,這篇文章是以 Langfuse 中有提到的 Ragas 指標為主,但不是全部,以下是所有 Ragas 現有的指標,這裡會標注這篇有說的部份。
Retrieval Augmented Generation
Nvidia Metrics
Agents or Tool use cases
Natural Language Comparison
SQL
General purpose
📌 可以從以下的 Github 位置看到以上 Ragas 所實作這些指標的 Prompt
不過他是 python 檔,然後 prompt 寫在裡面,所以可能還是要懂一些 python 才能看的懂。
https://github.com/explodinggradients/ragas/tree/main/src/ragas/metrics
🤔 有點奇怪,最新版本的 avaiable metrics 是沒有它的,但是還是找的到連結。然後看了一下,現在應該是 Factual_Correctness 與 Answer_Accuracy 比較是接近它的概念
https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/
衡量你的 AI 服務產的回答( answer )與標準答案( ground truth )在語義與事實上有多一致,越接近 1 就越一致。
它適用於有標準答案的任務,例如 FAQ、知識問答。但它不太適合那種開發性問答,你如說你覺得馬克有多棒棒之類的。
然後它的計算邏輯是,將你的答案,與標準答案分類成以下三個之類之一 :
然後再透過這三個來計算F1 Score公式如下,我只知道越高代表越符合。
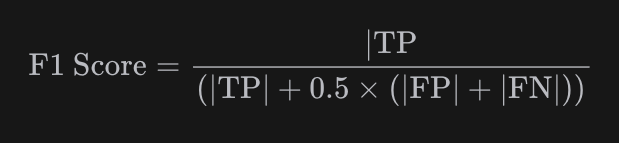
不過我實際用看了一下 Langfuse 官方提供的這個指標 prompt,有點不確定它有沒有計算 F1 Score,但我用以下兩個範例來測,的確有給出 1 或 0。
Query: 愛因斯坦是在幾年出生與地點?
GroundTruth: 愛因斯坦是在1879出生於德國。
實驗1:
Answer: 愛因斯坦在 1879 年德國出生。
Score: 1
實驗2:
Answer: 愛因斯坦在 1879 年台灣出生。
Score: 0
然後以下為 Langfuse 的 Prompt 可參考。
Given a ground truth and an answer statements, analyze each statement and classify them in one of the following categories: TP (true positive): statements that are present in answer that are also directly supported by the one or more statements in ground truth, FP (false positive): statements present in the answer but not directly supported by any statement in ground truth, FN (false negative): statements found in the ground truth but not present in answer. Each statement can only belong to one of the categories. Provide a reason for each classification.
ground truth: {{ground_truth}}
answer: {{answer}}
衡量你的 AI 服務回答,是否有什麼問題 ( 這個問題由你自已定義 ),就只會回是與否
它整個衡量邏輯很簡單,就是請 LLM 判斷多次,然後投票,就是如此的簡單。
然後它的適用情境事實上很廣,例如下面這些都可以:
以下為 Langfuse 的 prompt,還蠻簡單的,不過好像沒要求做多次。
Evaluate the Input based on the criteria defined. Use only 'Yes' (1) and 'No' (0) as verdict.
Criteria Definition: {{criteria_definition}}
Input: {{input}}.
https://docs.ragas.io/en/v0.1.21/concepts/metrics/answer_relevance.html
https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/answer_relevance/
Answer Relevance 這個只出現在 0.1 的版本,然後現在 stable 版本是叫 Response Relevancy
用來判斷產生的回答,與題目的相關度
它特別適合那種沒有標準答案的題目 ( 沒有 ground truth ),然後想知道有沒有回答到重點的這種。
它的計算方式很像我們之前有學到的 Hypothetical Document Embeddings ( HyDE ),也就是根據問題請 LLM 產生答案,再反去查向量資料庫的概念,而這裡也是流程如下 :
以下為 Langfuse 的 prompt,到好像沒看到有計算餘弦相似度之類的。
Generate a question for the given answer and Identify if answer is noncommittal. Give noncommittal as 1 if the answer is noncommittal and 0 if the answer is committal. A noncommittal answer is one that is evasive, vague, or ambiguous. For example, 'I don't know' or 'I'm not sure' are noncommittal answers.
answer: {{answer}}
noncommittal: {{noncommittal}}
https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/context_precision/
評估 Context 與回答的相關程度
正式的公式如下圖,有點複雜

但在 Langfuse 這裡好像只用下面那個 prompt 就解決了一切,而且這個 prompt 是 Ragas 維護的。
Given question, answer and context verify if the context was useful in arriving at the given answer.
Question: {{question}}
Answer: {{answer}}
Context: {{context}}
然後我看 Ragas 的 source code 看起來也是差不多,項多就是多了 example,只是它有多增加一個計算分數的流程,大概如下,詳細的可以去 source code :
class ContextPrecisionPrompt(PydanticPrompt[QAC, Verification]):
name: str = "context_precision"
instruction: str = 'Given question, answer and context verify if the context was useful in arriving at the given answer. Give verdict as "1" if useful and "0" if not with json output.'
input_model = QAC
output_model = Verification
examples = [
(
QAC(
question="What can you tell me about Albert Einstein?",
context="Albert Einstein (14 March 1879 – 18 April 1955) was a German-born theoretical physicist, widely held to be one of the greatest and most influential scientists of all time. Best known for developing the theory of ",
answer="Albert Einstein, born on 14 March 1879, was a German-born theoretical physicist, widely held to be one of the greatest and most influential scientists of all time. He received the 1921 Nobel Prize in Physics for his services to theoretical physics.",
),
Verification(
reason="The provided context was indeed useful in arriving at the given answer. The context includes key information about Albert Einstein's life and contributions, which are reflected in the answer.",
verdict=1,
),
),
https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/context_recall/
評估是否所有重要的 Context 都有被抓取出。重點在於不要遺漏重要的 Context
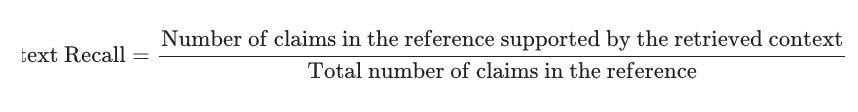
我看到這個時腦袋在想和 precision 的差別,後來查了一下,我覺得這個比愈很好懂 :
然後以下為 Langfuse 上的 prompt,這個麻好像有點簡單,然後如果它值很低或零,就代表它的 answer 不是透過 context 得來的答案,這也代表這個 context 是廢物。
Given a context, and an answer, analyze each sentence in the answer and classify if the sentence can be attributed to the given context or not.
Context: {{context}}
Answer: {{answer}}
https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/faithfulness/
評估回答是否與 Context 保持一致
然後下面是 Langfuse 的 prompt,我自已是覺得有點問題。除了缺了 context 外,他也只是 break down 回答的每個句字,確保他們不要有`pronouns (代名詞)在句字中,在猜應該是想將主觀判斷移除,但就是有點搞不太懂實際上的想法。
Given a question and an answer, analyze the complexity of each sentence in the answer. Break down each sentence into one or more fully understandable statements. Ensure that no pronouns are used in any statement.
Question: {{question}}
Answer: {{answer}}
然後如果看 Ragas 中的說明會比較清楚它實際上的計算方式。

https://docs.ragas.io/en/latest/concepts/metrics/available_metrics/agents/#agent-goal-accuracy
用來衡量與 AI Application 進行一段互動或流程中,是否真正達成使用者的最終目標
這個適用於一系統任務處理這種類型,有點比較是用來判斷 AI Agent 或是 Agentic AI 這種類型的服務。
Given user goal, desired outcome and achieved outcome compare them and identify if they are the same (1) or different(0).
User Goal: {{user_goal}}
Desired Outcome: {{desired_outcome}}
Achieved Outcome: {{acheived_outcome}}
衡量兩段 SQL 查詢在語義上是否等價
不過我目前以 AI Application 的情況下,我是不太會讓 AI 自已產 SQL,再去抓資料庫,因為一不小心我們的 Database 就會沒辦法用了,所以 SQL 還是建議過 Code Review 比較好。
Explain and compare two SQL queries (Q1 and Q2) based on the provided database schema. First, explain each query, then determine if they have significant logical differences.
Database Schema: {{database_schema}}
Q1: {{question_one}}
Q2: {{question_two}}
給定一個主題以及一組參考主題,判斷該主題是否屬於任一參考主題。
Given a topic and a set of reference topics classify if the topic falls into any of the given reference topics.
Topic: {{topic}}
Reference Topics: {{reference_topics}}
給定一個主題,判斷 AI 是否拒絕回答關於此主題的問題。
這個就是有點用在驗證你們的 AI 服務的主題守門員,例如我們家是學習網站,但可以回答 18 禁的東西,那就有問題吧 ? 這個就是用來評分這一塊。
Given a topic, classify if the AI refused to answer the question about the topic.
Topic: {{topic}}
今天說的這些都是屬於 LLM-as-a-Judge 的 Evaluator,也就是說會透過 LLM 來產生這些指標來評分,但不代表這些指標只能透過 LLM 來產,你事實上也可以用我們昨天提到的『 透過 API/SDK 完全自訂的評分 』來自已幹一個。
然後看了一下,我發現現在 Langfuse 上提供的 Ragas 指標不確定是不是名稱還沒改什麼,和現行 Ragas stable 版本的有點差,之後在來研究看看沒有沒辦法升級這東東。
不過仔細想想也對,現在 Ragas 的版本也才 0.3.6,所以不定要和 LagnChain 一樣等 1.0 版本後才會比較穩定。
https://github.com/explodinggradients/ragas
