前面談了那麼多 AI Application 開發相關的東西,最後我們就來談談要如何選擇 AI Model 呢 ?
主要就是考慮以下幾點 :
🤔 雲端服務平台是否有支援
會需要考慮這個主要的原因在於,如果我們使用的雲端服務商,例如 GCP 如果他本身就有 AI Model 那這個時後你在這個平台上的很多 AI 功能,都會有很好的整合程度,例如 Vertex AI。
像如果在 GCP 上用 Gemini 就能直接透過 Vertex AI 進行使用、觀測、成本,整合度會遠高於在 GCP 上使用 OpenAI API。
🤔 有沒有折扣 ?
應該有在業界工作的人都知道,我們有時後都會和雲端供應商或是一些模型在台灣的合作代理商進行合作,然後他們的使用模型價格就會低於其它的不少。
這裡事實上和第 1 個考慮點有點相關,因為要先確保,你想用的模型在你們公司用的 AI Framework 或 AI Platform 有沒有支援,以我們公司來看是使用 LangChain 與 Langfuse,所以想當然後我們也先知道兩個東西支援那些模型。
像以 LangChain 來說根據以下的文件,它是支援這些 AI Model 供應商 :
https://docs.langchain.com/oss/javascript/langchain/models#openai
所以像如果你要用 deepseek 或啥的可能就要想一下了,但事實上也沒到完全不能用,只是叫要多寫不少程式碼,就是他最特別,不過如果你們軟體架構做的好,那應該影響不大,就當參考。
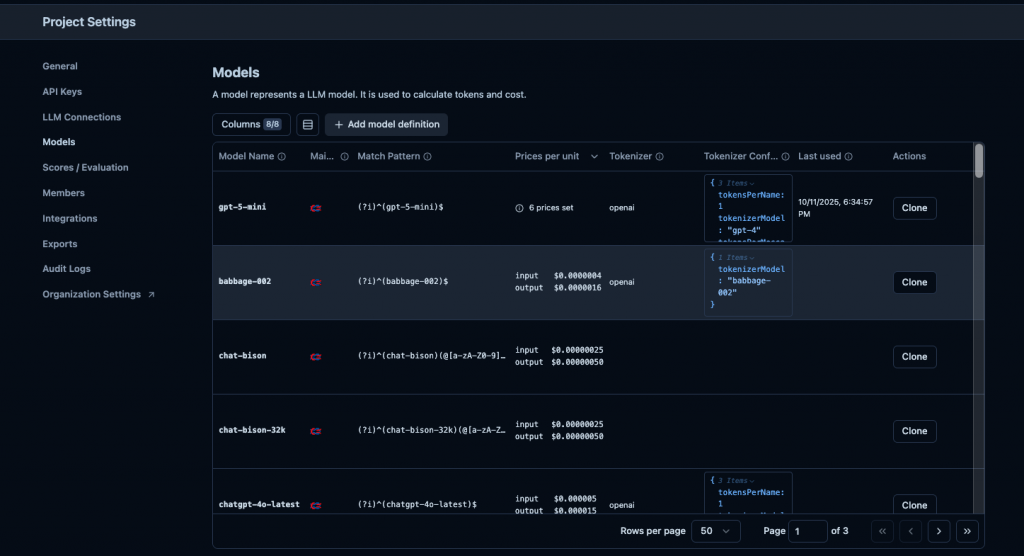
然後是 Langfuse 我後來發現會影響到這個Model Usage & Cost Tracking,也就是說只有某些 model 才能會幫你計算成本,不然的話你要自已手填。
https://langfuse.com/docs/observability/features/token-and-cost-tracking
然後 Langfuse 就只支援這三個 AI Model 供應商 :
其它的話你就要用以下的手法來進行處理,例如到後台自已加上。
- 就智慧與價格的比,不要看到很便宜就直接選
- 但也不代表 CP 值的就要選,因為要想想你們使用場境是否需要那麼聰明
🤔 那要去那裡查 CP 值呢 ?
目前我大部份都是從這個網站上看的。
https://artificialanalysis.ai/
這個網站幾乎已經是整個 AI 領域的分析之王,它包含了我們這些開發與使用 ai model 的人所以想知道相關的比較資料,而且也有圖表,個人覺得非常的棒棒。
🤔 要如何看呢 ?
我自已是都看這個圖。
https://artificialanalysis.ai/#intelligence-vs-price-log-scale
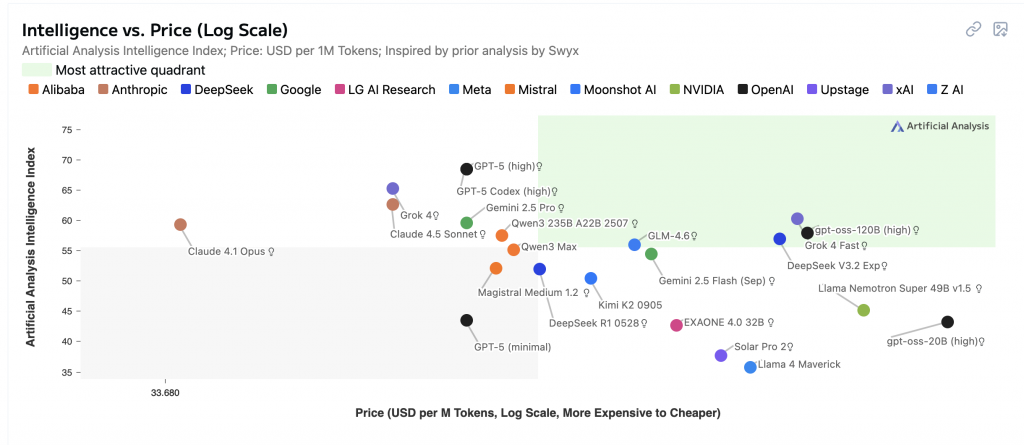
然後我們這裡解釋一下他的兩個軸代表的意思 :
所以用這張圖來看,越右上角綠色的部份 ( Most attractive quadrant ) 就是 CP 值越高的,然後以現在這個時間點 2025.10.13 來看應該是 Grok4-Fast 與 gpt-oss-120b(high) 是最好 ? 但有點奇怪 gpt-oss 不是應該是開源免費的嗎 ? 我自已是猜有些平台有串它們,然後再收比較低的費用,例如 cloudflare 所以還是有算在裡面。
備註: Artificial Analysis Intelligence Index 是啥 ?
它是一個結合很多評測項目的綜合指標,是目前最簡單的方式來比較各 Model 的智慧程度。
目前已經是第 3.0 版 ( 2025.09 發佈 ),測試項目如下 :
https://artificialanalysis.ai/methodology/intelligence-benchmarking
| 評測項目 | 領域 (Field) | 補充說明(給非技術讀者) |
|---|---|---|
| MMLU-Pro | 推理與知識 (Reasoning & Knowledge) | 考大範圍的一般知識與理解力,像綜合學科測驗,看模型懂不懂各種主題。 |
| HLE(Humanity’s Last Exam) | 推理與知識 (Reasoning & Knowledge) | 高難度的綜合題,測試模型在嚴苛情境下是否能給出正確、清楚的答案。 |
| AA-LCR(Long Context Reasoning) | 長上下文推理 (Long Context) | 看模型能否在「非常長的文件」中抓到重點並回答正確。 |
| GPQA Diamond | 科學推理 (Scientific Reasoning) | 進階科學題(物理/化學/生物),評估模型的科學理解與判斷。 |
| AIME 2025 | 競賽數學 (Competition Math) | 以數學競賽風格題目檢測純數學推理與計算正確性。 |
| IFBench | 指令遵循 (Instruction Following) | 測模型能不能「照著指令做」,例如格式、步驟與要求是否精準。 |
| SciCode | 程式生成(科研計算)(Code Generation) | 要求用 Python 解科學/工程的小任務,驗證能否寫出可運行的程式。 |
| LiveCodeBench | 程式生成(競程)(Code Generation) | 競賽型程式題,測試是否能快速、正確地寫出能通過測試的程式。 |
| Terminal-Bench Hard | 代理任務/終端操作 (Agentic Workflows) | 模擬在命令列執行實際任務,檢驗「會不會動手做事」而不只會回答。 |
| 𝜏²-Bench Telecom | 代理任務/電信情境 (Agentic Workflows) | 在電信客服等流程中規劃步驟、使用工具、解決問題的能力。 |
| Global MMLU Lite | 多語推理與知識 (Multilingual Reasoning) | 用多種語言出題(含中/英/日等),看模型跨語言的理解力。 |
| MGSM | 多語數學 (Multilingual Math) | 用多語言考數學題,測試模型在不同語言下是否仍能算對。 |
| MMMU Pro | 視覺推理 (Visual Reasoning) | 看圖答題的能力,評估模型理解圖片內容並作答的表現。 |
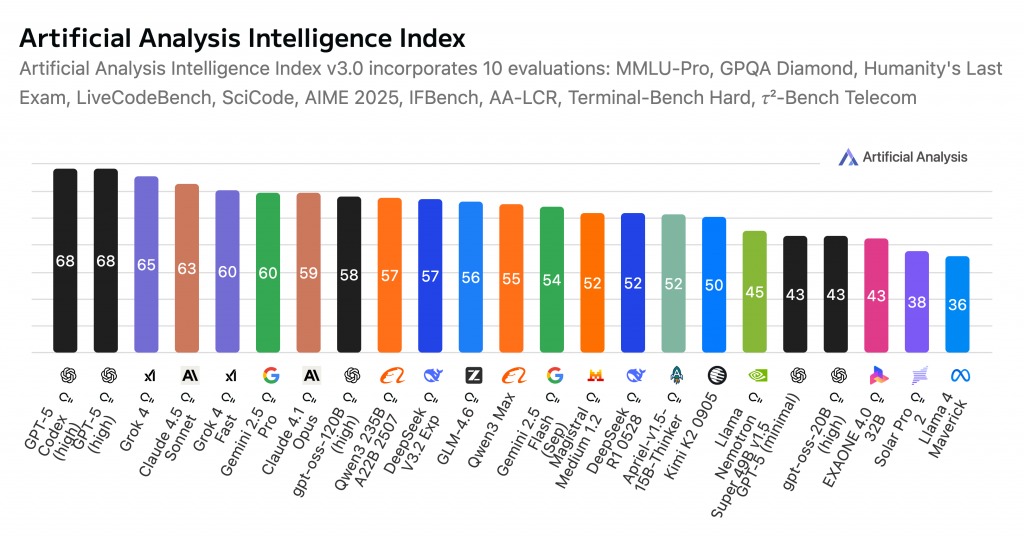
那目前這個時間點那個最聰明呢 ? 有點好奇~
https://artificialanalysis.ai/#artificial-analysis-intelligence-index
如果我們以 Artificial Analysis Intelligence Index 來看答案是GPT-5 Codex(high)
這裡事實上就是考慮點 2,其中一個重點 :
不是 CP 值就要選,而是要看你的使用情境才能決那個 CP 值最高
這裡可以先用這為大分類 :
1. Non-Reasoning Model
非推理型模型,主要就是看題輸出,它的特點就是便宜與快,但相對的如果在一些需要思考的情況,他的表現很不好,例如 Grok 4 Fast 就是 non-reasoing model。
那要去那查呢 ? 有兩個管道,一個就是去各 Model 供應商的官網自已看,有些會有寫,另一個就是去這裡。
https://artificialanalysis.ai/models
然後你用 non-reason 去找,你就會看到有些 model 名稱會有寫。
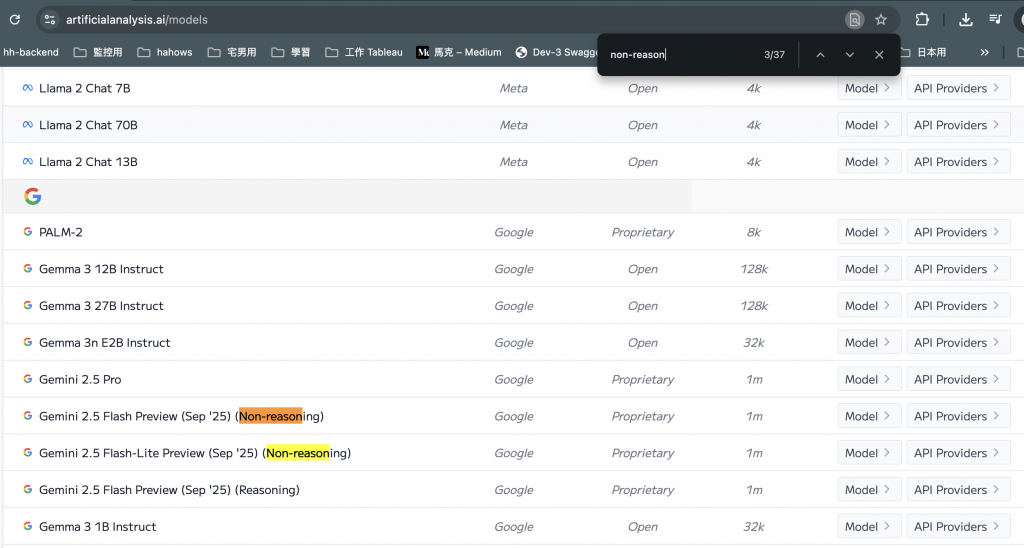
目前現在好像越來越少了,像 GPT-5 後就開始沒有這種了,就算是 GPT-5-nano 也是 reasoning model。
2. Reasoning Model
這種類型的 Model 內建了 CoT、規畫、反思等思考模式,例如我們現在常使用的 GPT-5 包含 GGPT-5 Mini 都是這種類型,你在 GPT 用時,它們應該有顯示他們思考的流程。
🤔 接下來再將我們要做的工作分配給這兩種類型
不過這裡事實上也很難判斷的出,是不是真的用 Non-Reasoning Model 來處理我們覺得簡單的任務就好,所以比較嚴謹的方法還是建議進行我們 27 天寫的實驗,來用這個 model 來跑 1 次就較安心點。
30-27: [知識] AI Application Evaluation ( 3 ) 之 Experiments 篇
還記得我們在這篇文章中,有提到的 embedding model 嗎 ?
30-21: [實作-10] 用字幕檔實作 AI 課程問答功能 - Native RAG + MongoDB Atlas
然後 embedding model 的評比與分析我是從以下這兩個地方看的。
首先說說第一個 huggingface 它是一個開源的 AI Model 與資料生態平台,和 ArtificialAnalysis 有點像,但它是以開源模型為主且可以在上面部署一些東西。
然後 MTEB 全稱為 Massive Text Embedding Benchmark,是一個對文字 embedding 評測的套件與排行榜,如下圖。
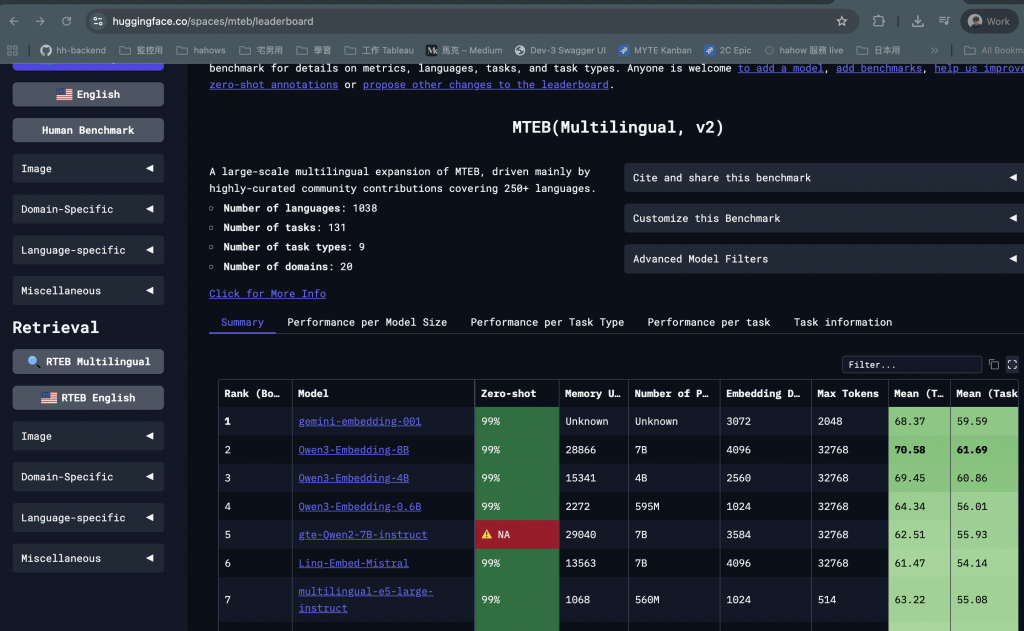
然後下面請 AI 整理了一下每個欄位代表的意思,不然真的第一次看有點看不懂,我們以第一欄 gemini-embedding-001 來當理解範例。
然後詳細的每個欄位實際上的計算與說明請參考以下的論文。
MTEB: Massive Text Embedding Benchmark
| 欄位名稱 | 說明 | 數字範例說明(用這行的實際值解釋) |
|---|---|---|
| Zero-shot | 是否以「零樣本」設定評測(未針對任務微調)。 | 99%:此模型幾乎整套評測都是在零樣本情境下完成,泛化能力代表性高。 |
| Memory Usage (MB) | 推理時計算所需記憶體,影響硬體/雲端成本。 | Unknown:官方沒公布需要多少記憶體,無法直接估成本。 |
| Number of Parameters | 模型參數量,影響能力與成本。 | Unknown:未揭露參數規模,無法用參數量推測性能/成本。 |
| Embedding Dimensions | 向量維度,越高語意更細、計算/儲存成本也更高。 | 3072 維:每段文字變成 3072 個數字的向量,語意表達細緻,但向量庫/相似度計算較花資源。 |
| Max Tokens | 一次能處理的文字長度上限。 | 2048 tokens:可讀約數千英文詞的上下文;太長的文件需切段。 |
| Mean (Task) | 所有任務的平均分數(整體能力)。 | 68.37:整體表現屬中高水準;在大多數任務上都有不錯成績。 |
| Mean (TaskType) | 依任務類型加權的平均分數(平衡度)。 | 59.59:各任務類型的表現較為平均但仍有可進步空間。 |
| Bitext Mining | 跨語言句子對齊能力。 | 79.28:跨語言配對很強,適合多語檢索/比對。 |
| Classification | 單標籤分類(情感/主題等)。 | 71.82:分類準確度高,適合做標籤預測類任務。 |
| Clustering | 語意分群,把相似文本聚在一起。 | 54.59:分群能力中等,能用但非亮點。 |
| Instruction Retrieval | 檢索指令/提示的能力(RAG/Agent 很關鍵)。 | 5.18:在「找對指令」這件事上表現偏弱,不建議單靠它做指令檢索。 |
| Multilabel Classification | 多標籤分類(同一文本多個類別)。 | 29.16:多標籤表現較弱,需搭配其他模型/流程。 |
| Pair Classification | 兩段文字是否相關(問答配對、重複問題)。 | 83.63:配對判斷非常強,適合 FAQ 配對、去重。 |
| Reranking | 對初檢索結果重新排序(搜尋/推薦)。 | 65.58:重排序效果不錯,可用於提升搜尋結果品質。 |
| Retrieval | 從庫中找回相關文件(RAG 核心)。 | 67.71:檢索力佳,能穩定找回對的內容。 |
| STS(語意相似度) | 兩句話語意是否相近。 | 79.40:相似度判斷很強,適合相似問句合併、去重、推薦近似內容。 |
🤔 那我們 embedding 要看那個呢 ?
答案是不一定,應該有能會直接用 zero-shot 率來判斷,它比較代表的意思為『 表示「這個模型在 MTEB 所有要跑的資料集中,有多少成功跑出有效分數 』,所以只是有效,不代表是好與壞。
所以比較準確還是要看你用這個 embedding model 的目的,例如 Retrieval 或 Reranking 之類的,在來看他相對應的分數。
🤔 但上面的好像都是以簡體來測 ?
這個我是從 ihower 這篇文章中注意到這件事,所以我們繁中用戶建議可以讀完上面的知識後,然後再參考這篇文章,真的寫的很棒。
ihower-使用繁體中文評測各家 Embedding 模型的檢索能力
這篇文章我本來是想打算在最前面的幾篇文章開頭就說,但是我那時實際上嘗試寫了以後發現,完全不懂在衝啥小,因為那時我對 AI 真的還不算很熟,上面 MTEB 的欄位連 zero shot 是啥鬼都不知道,embedding 也是,所以最後決定拉到最後面來寫,然後真的發現一切都變很好理解,這次的鐵人賽真的學到了不少。
總於要結束了……

