
上一篇文章中,我們已經學會評估的方式後,接下來我們要來談 Experiments,然後主要的目的是 :
系統性的來比較你所設計的 AI Application 的 Prompt、參數、Retrieveal 策略的效果,而不在是用感覺來評估這些東西
那這問個問題。
🤔 我們前天那篇文章有提到那些評分方式,用那個判斷不就好了 ?
因為範圍與情境太小了,它還不能客觀的判斷。但不代表昨天學的沒用,因為評估方式會是 Experiments 的其中一個部份。
🤔 整個 Experiments 流程
接下來我們就來詳細的說明一下每一個流程。
這個地方的指標就是昨天那些文章中提到的這些 :
30-26: [知識] AI Application Evaluation ( 2 ) 之 Langfuse 支援的 Evaluator 與 Ragas 指標
首先會先決定這個實驗的目的,以下為範例 :
接下來我們會根據我們要驗證的服務與功能,來決定用什麼指標,以下為我簡單腦袋有想過的情境來列出一些適合的指標,下面只是大概,我還沒詳細的判斷過 :
| 情境 | 目的(實驗假設) | 可參考指標 |
|---|---|---|
| 1) 課程字幕做 RAG 問答品質評估 | 提升答案是否根據提供的片段 | Faithfulness、Response Groundedness、Context Precision、Context Recall、Response Relevancy |
| 2) Chunk 策略 A/B 的優化實驗 | 提升取用 Chunk 的精準度 | Context Precision、Context Recall、Noise Sensitivity |
| 3) Rerank 是否增加品質 | 降低不相干片段進入生成 | Noise Sensitivity、Context Precision、Response Relevancy |
| 4) 日期/事實型 QA (有標準答案)的準確性 | 提高客觀正確性 | Answer Accuracy、Factual Correctness、Faithfulness |
| 5) 開放式主觀評論(無標準答案)的品質 | 讓回答更貼題、更聚焦要點 | Response Relevancy、Rubrics based scoring、Aspect critic |
https://langfuse.com/docs/evaluation/experiments/datasets
這個 Dataset 就是會用來進行實驗的資料集,它只有以下三個資訊要輸入 :
然後在 Langfuse 有兩種方式可以建立 :
以下為這三種的範例。
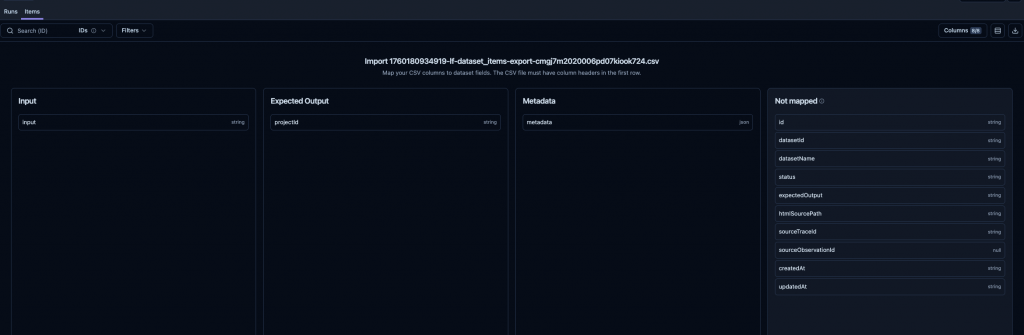
🤔 1. 我們自已手動匯入 CSV。
如下圖,然有提到 mapping 欄位的功能。

🤔 2.自已寫程式透過 LLM 來產生資料到 Dataset。
如下程式碼,還算簡單。
import { Langfuse } from "langfuse";
(async () => {
const langfuse = new Langfuse({
publicKey: process.env.LANGFUSE_PUBLIC_KEY,
secretKey: process.env.LANGFUSE_SECRET_KEY,
baseUrl: process.env.LANGFUSE_BASE_URL,
});
try {
await langfuse.api.datasetItemsCreate({
datasetName: "RouteAI",
input: "你很棒棒嗎",
expectedOutput: "other",
metadata: {
model: "llama3",
},
});
} catch (error) {
console.error(error);
}
})();
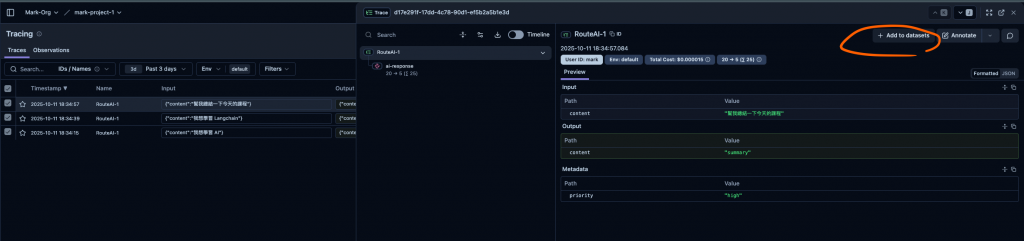
🤔 3. 將現有的 Trace 放入到 Dataset
如下圖。
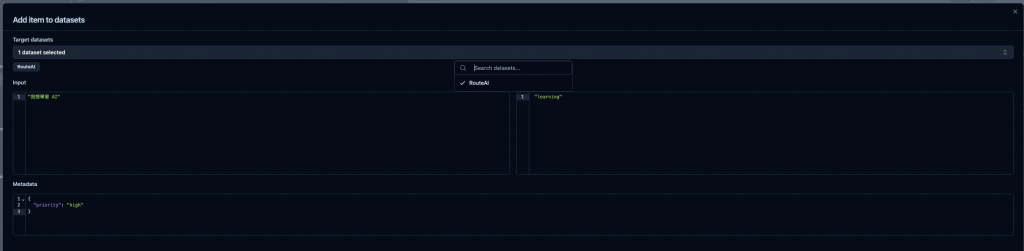
❗小提醒,有時後三不五時可以去看 trace,然後定期的將它加入到你的 Dataset 中
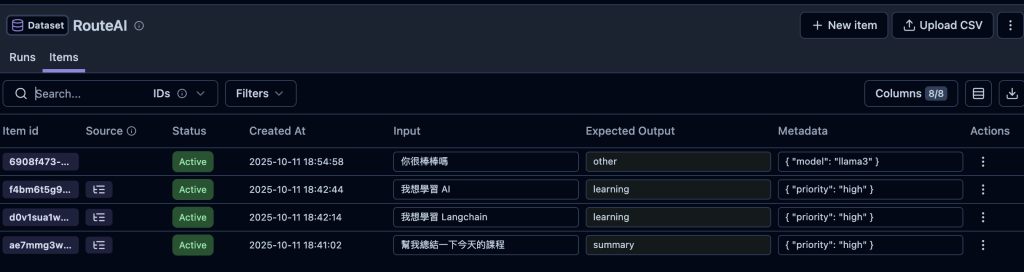
🤔 然後我們這次的測試的 Dataset 長的如下
我的模擬情境是,這個 AI 是個 RouteAI 然後他會根據使用者的問題,來判斷意圖,然後回傳意圖,如下圖,例如我想學習 AI 就會預期回傳 learning。
這裡分兩種情況:
你要先在 UI 上設定好,如下圖,然後其中 filter 要設定你的那要測試的那個 dataset。
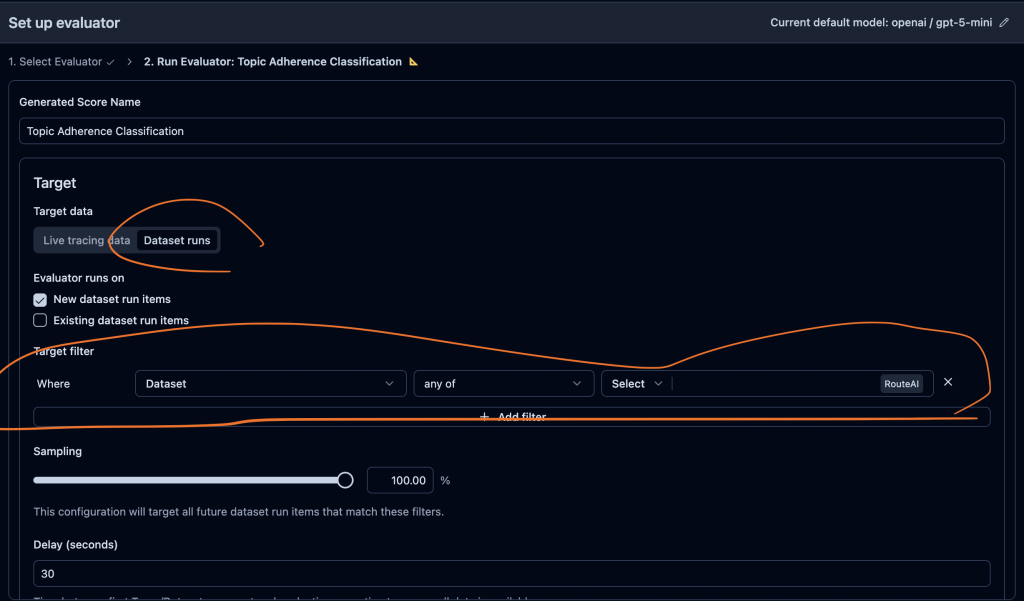
‼️ 但是如果是用 Local Dataset 的情況下,好像我就找不到方法了,可能就還是要將 Local Dataset 建立到 Langfuse Dataset
執行實驗有兩種方式 :
然後我們先來說說第一種,如下圖,然後有以下欄位要填寫 :
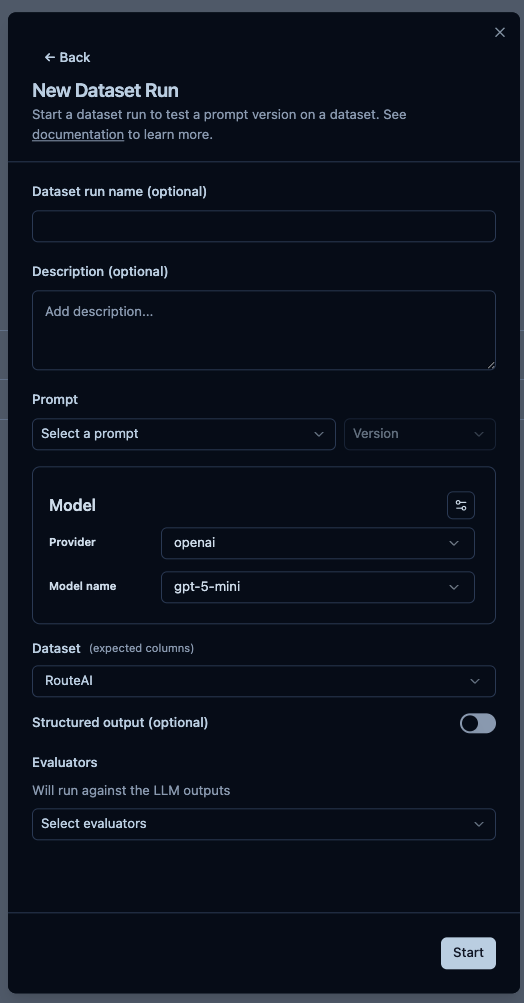
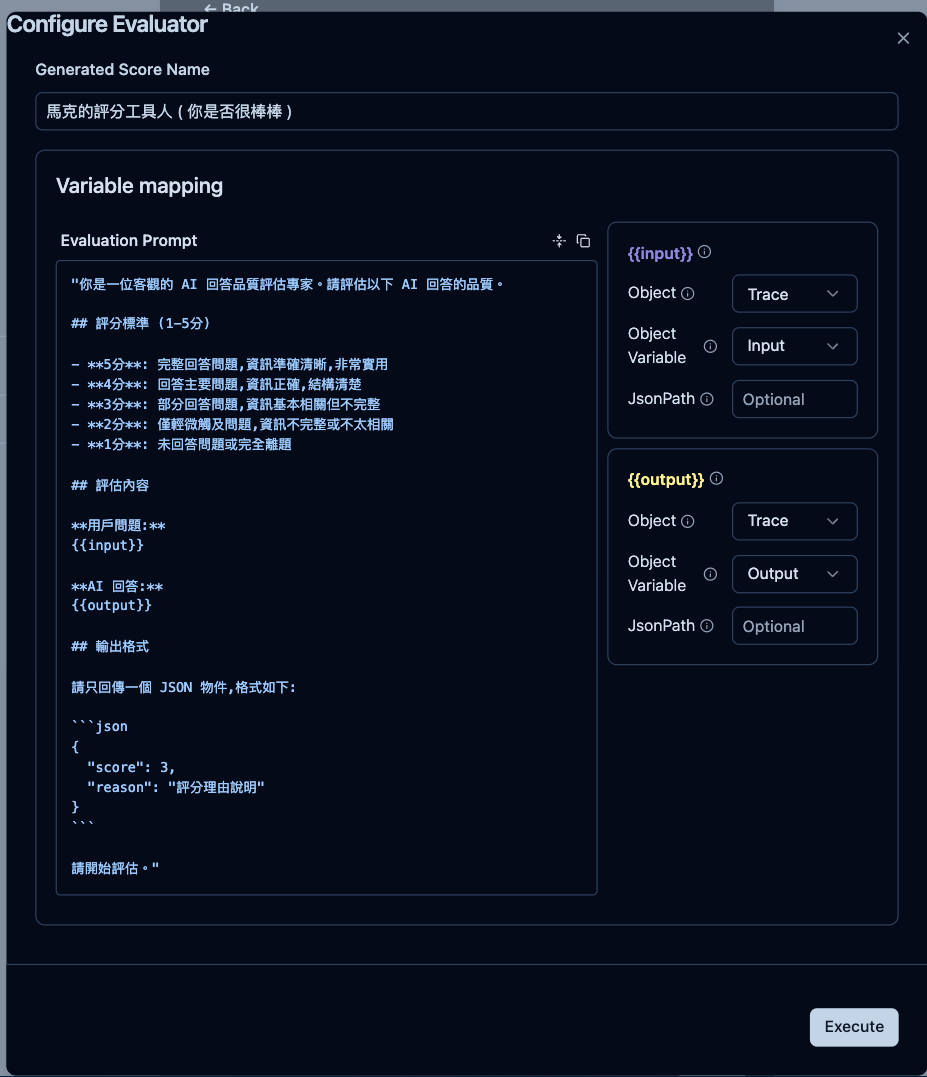
這個功能就是可以使用 SDK 來建立與實驗,以下為最簡單過的執行方式。
import { NodeSDK } from "@opentelemetry/sdk-node";
import { OpenAI } from "@langchain/openai";
import {
LangfuseClient,
ExperimentTask,
ExperimentItem,
} from "@langfuse/client";
import { observeOpenAI } from "@langfuse/openai";
import { LangfuseSpanProcessor } from "@langfuse/otel";
const otelSdk = new NodeSDK({ spanProcessors: [new LangfuseSpanProcessor()] });
otelSdk.start();
const langfuse = new LangfuseClient();
const dataset = await langfuse.dataset.get("RouteAI");
const myTask: ExperimentTask = async (item) => {
const question = item.input;
const response = await observeOpenAI(
new ChatOpenAI({
modelName: "gpt-5-nano",
})
).invoke([
{
role: "system",
content: `
學生問題: ${question}
## Instructions:
根據學生問題,來判斷意圖 (intent),並且回傳結果
意圖只能有以下幾種:
- 學習
- 總結
- other
## Example
Example 1:
學生問題: 我想學習 AI
結果:學習
Example 2:
學生問題: 幫我總結一下今天的課程
結果:總結
Example 3:
學生問題: 馬克很棒棒嗎
結果:other
`,
},
{
role: "user",
content: question,
},
]);
return response.content;
};
(async () => {
const result = await dataset.runExperiment({
name: "RouteAI 實驗-2025-10-11",
description: "RouteAI 實驗-2025-10-11",
task: myTask
});
// Print formatted result
console.log(await result.format());
await otelSdk.shutdown();
})();
然後他有提供很多用 UI 沒辦法做的事情
🤔 SDK 額外功能 1. 我們可以使用 Local Dataset 來執行
const localData: ExperimentItem[] = [
{ input: "我想學習 AI" },
{ input: "幫我總結一下今天的課程" },
{ input: "馬克很棒棒嗎" },
];
(async () => {
const result = await langfuse.experiment.run({
name: "RouteAI 實驗-2025-10-11",
description: "RouteAI 實驗-2025-10-11",
data: localData,
task: myTask,
});
console.log(await result.format());
await otelSdk.shutdown();
})();
🤔 SDK 額外功能 2. 可以使用 Local Evaluator 來執行
如下官網的範例
onst accuracyEvaluator = async ({ input, output, expectedOutput }) => {
if (
expectedOutput &&
output.toLowerCase().includes(expectedOutput.toLowerCase())
) {
return {
name: "accuracy",
value: 1.0,
comment: "Correct answer found",
};
}
return {
name: "accuracy",
value: 0.0,
comment: "Incorrect answer",
};
};
// Use multiple evaluators
const result = await langfuse.experiment.run({
name: "Multi-metric Evaluation",
data: testData,
task: myTask,
evaluators: [accuracyEvaluator],
});
🤔 SDK 額外功能 3. 可以在最後實驗完後,執行一個 Run-level Evaluators 來將結果 aggregate 成一個結果
如下 averageAccuracy,它最後會將每一筆的測試結果,匯總成一個平均。
const averageAccuracy = async ({ itemResults }) => {
// Calculate average accuracy across all items
const accuracies = itemResults
.flatMap((result) => result.evaluations)
.filter((evaluation) => evaluation.name === "accuracy")
.map((evaluation) => evaluation.value as number);
if (accuracies.length === 0) {
return { name: "avg_accuracy", value: null };
}
const avg = accuracies.reduce((sum, val) => sum + val, 0) / accuracies.length;
return {
name: "avg_accuracy",
value: avg,
comment: `Average accuracy: ${(avg * 100).toFixed(1)}%`,
};
};
const result = await langfuse.experiment.run({
name: "Comprehensive Analysis",
data: testData,
task: myTask,
evaluators: [accuracyEvaluator],
runEvaluators: [averageAccuracy],
});
console.log(await result.format());
🤔4. 可以使用 concurrency 讓實驗跑的更快。
const result = await langfuse.experiment.run({
name: "Async Experiment",
data: testData,
task: asyncLlmTask,
maxConcurrency: 5, // Control concurrent API calls
});
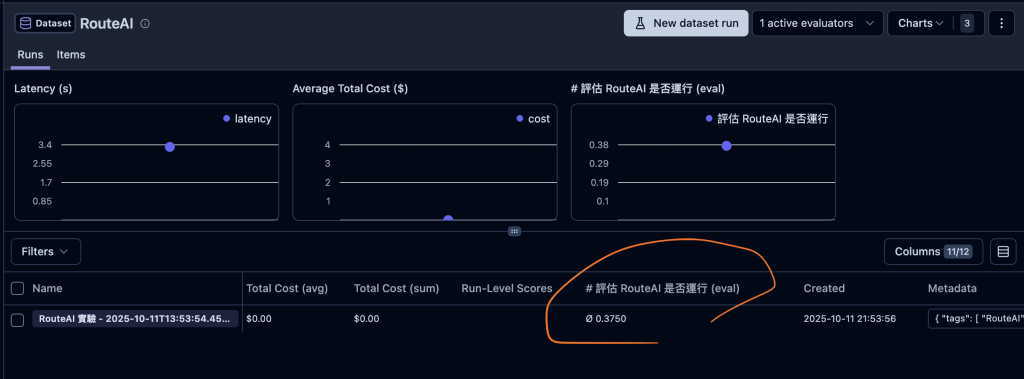
然後下面這個地方,就可以看到你這次實驗指定的 Evaluators 跑的平均分數,不過這裡就是簡單的範例,好像也沒說這個結果。
❗然後我有發現 Token 與 Cost 沒有正常顯示,還在研究中
然後下面這張是我們上面點進去後看到的每個結果,先說一下我們的 Dataset 有 4 筆,所以這個實驗就是每 1 筆都會去跑,然後如下圖就會有 4 筆的結果,其中幾個欄位可以注意一下 :

最後這個就是整個實驗的分數。
到了今天事實上我們已經將 AI Application Evaluation 整個體系都已經基本的講過了 :
然後這篇文章的 Experiments 就是將這個 Evaluation 體系串起來的東西,不過這次鐵人賽寫的事實上也只是寫個基本與串起來整個體系,如果真的往下挖還有不少呢 ~~
不過鐵人賽總於快結束了 ~
