在深度學習的實務應用中,圖像數據的處理與模型的優化是非常重要的環節。今天將帶你了解如何在 Python 中讀取圖像,並且利用 PyTorch 進行模型的訓練、優化與儲存,同時解釋訓練、驗證、測試資料集的差異與使用場警,最終告訴你該如何觀察損失值來評估模型的表現。
CIFAR-10 是電腦視覺領域中非常經典的影像資料集,包含 10 個類別(如飛機、汽車、貓、狗等)。每張圖片的大小為 32×32 的彩色影像。在進行深度學習任務時,輸入資料的理解與處理是關鍵的一環,因此我們首先要學會如何在 PyTorch 中正確準備資料集。
在深度學習的影像處理任務中,「正規化」是一個關鍵步驟。它的主要目的,是讓輸入數據的數值範圍保持一致。以常見的影像資料來說,像素值原本落在 [0, 255] 之間,而透過正規化,我們會將這些值縮放至 [0, 1] 或 [-1, 1] 的範圍。這麼做不只是為了美觀的數據分佈,更能有效提升模型訓練的穩定性,減少像是梯度爆炸或梯度消失等常見問題,也能加速優化器的收斂速度。
在 PyTorch 框架中,torchvision 是一個非常實用的套件,不僅能快速下載如 CIFAR-10 等常用的影像資料集,還內建支援資料增強與標準化的功能。在載入資料之前,我們可以先定義好一組轉換方式,例如以下這段程式碼:
import torch
import torchvision
import torchvision.transforms as transforms
# 定義影像轉換流程,包括 Tensor 化與正規化
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 將像素值縮放至 [-1, 1]
])
這裡的 Normalize 函式會針對每個顏色通道(紅、綠、藍)分別進行正規化。這個處理除了提升數據一致性外,也能減少不同通道之間因尺度差異所導致的學習偏差。換句話說,模型在這樣的條件下,更能「公平」地學習各種影像特徵。整體來看正規化不僅讓訓練過程更穩定高效,也有助於模型在面對不同光照或色彩變化的情境時,展現更好的泛化能力。
載入與處理資料集是訓練模型的重要前置步驟。我們使用 torchvision.datasets.CIFAR10 套件來下載 CIFAR-10 資料集,並搭配前面設定好的 transform 進行資料預處理,確保圖片在進入模型前已具備良好格式與特徵分佈。
# 下載完整訓練集(共 50,000 張),再進一步拆分為訓練集與驗證集
full_train = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform
)
train_size = int(0.9 * len(full_train)) # 90% 作為訓練資料
val_size = len(full_train) - train_size # 剩餘 10% 作為驗證資料
trainset, valset = random_split(full_train, [train_size, val_size])
trainloader = DataLoader(trainset, batch_size=64, shuffle=True, num_workers=0)
valloader = DataLoader(valset, batch_size=64, shuffle=False, num_workers=0)
在預處理階段,我們將原始的訓練資料拆分為兩個子集:訓練集(train)與驗證集(validation),它們在模型訓練過程中扮演著不同角色:
這樣的劃分方式能幫助我們更有系統地控制訓練流程,進一步提升模型的泛化能力。除了訓練與驗證之外,在更嚴謹的實驗或比賽中,通常還會使用第三組資料:測試集(test)。測試集完全不參與模型訓練,只在模型訓練結束後用來評估最終的性能表現,模擬模型在實際應用中的預測效果。
| 資料類型 | 功能 | 是否用於訓練 | 是否打亂順序 |
|---|---|---|---|
| 訓練集 | 學習模型參數 | ✅ 是 | ✅ 是 |
| 驗證集 | 監控訓練過程、調整模型 | ❌ 否 | ❌ 否 |
| 測試集 | 最終模型評估 | ❌ 否 | ❌ 否 |
我們也同樣下載了測試資料集:
# 載入測試資料集(共 10,000 張)
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=64, shuffle=False, num_workers=0
)
在程式中,資料的讀取與分批由 DataLoader 負責。由於一次將所有資料送入模型會超出 GPU 記憶體限制,因此透過 mini-batch 的方式,每次僅處理部分資料,不僅有效率,也利於模型收斂。
而DataLoader 也支援 資料隨機化(shuffle)。在訓練階段開啟 shuffle=True 可以避免模型過度記住資料順序,提高泛化能力;而在驗證與測試階段則關閉隨機化,以確保結果的穩定性與可重現性。
對於初學者來說,在設計卷積神經網路時,最常見的疑問之一莫過於:每一層的輸入與輸出尺寸到底是怎麼算出來的?那全連接層的參數數量又該如何推導? 要釐清這些問題,我們得從最基本的輸入特徵結構與各層之間的轉換邏輯談起。
就拿本次資料集來說,每張圖像的尺寸都是固定的:
(Height=32, Width=32, Channels=3)
也就是說,原始影像的格式為 (H, W, C)。不過在 PyTorch 的卷積層中,模型預期的張量格式則是 (C, H, W)。幸好這樣的轉換在 torchvision.datasets.CIFAR10 裡已經幫我們處理好了,所以不必手動調整。而實際訓練時,資料通常會以「批次」的形式餵給模型,因此整體的輸入格式會變成:
(Batch_size, Channels, Height, Width) → (N, C, H, W)
這種設計使得模型能夠分別處理 R、G、B 三個顏色通道,也就是說進而在不同的色彩維度中萃取出關鍵特徵,因此我們可以這樣設計模型架構:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 第一層卷積:從 RGB 三通道轉成 6 個特徵圖
self.conv2 = nn.Conv2d(6, 16, 5) # 第二層卷積:再從 6 個特徵圖提取出 16 個
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 第一層全連接,輸入來自 flatten 後的特徵圖
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) # 最終輸出對應 10 個分類
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), 2)
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, 16 * 5 * 5) # 將三維特徵圖展平
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) # 最後一層直接輸出 logits
return x
在進入全連接層前,有一個重要的細節需要注意:16 × 5 × 5 這個數字到底怎麼來的?它其實是前面經過兩次卷積與池化操作後,最後一層輸出特徵圖的維度計算結果。我們可以透過以下的數學公式來推導每一層輸出大小
具體的過程可以整理成一張表:
| 層級 | 輸入尺寸 | 輸出尺寸 |
|---|---|---|
| conv1 | (3, 32, 32) | (6, 28, 28) |
| maxpool1 | (6, 28, 28) | (6, 14, 14) |
| conv2 | (6, 14, 14) | (16, 10, 10) |
| maxpool2 | (16, 10, 10) | (16, 5, 5) |
| flatten | - | 400 |
| fc1 | 400 | 120 |
| fc2 | 120 | 84 |
| fc3 | 84 | 10 |
而經過這樣的轉換後,我們會得到 16 張大小為 5×5 的特徵圖。這就是為什麼在進入第一個全連接層時,我們需要先把三維的 (16, 5, 5) 展平成一個長度為 400 的向量,作為後續神經網路層的輸入來源。
而這次訓練的核心目標,是根據驗證集的表現來監控模型學習進度,並在表現最優時儲存對應的參數設定。由於本次任務屬於分類問題,因此我們選擇了常見的損失函數 交叉熵損失(CrossEntropyLoss),而優化器則採用 隨機梯度下降法(SGD),並加入動量(momentum)來加速收斂。
import torch.optim as optim
criterion = nn.CrossEntropyLoss() # 分類任務標配的損失函數
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 可調整學習率與動量
而正常的訓練中通常會在每個訓練週期使用訓練集資料更新模型權重,再透過驗證集來觀察泛化能力,而這樣的設計是為了早偵測是否發生過擬合,並在訓練過程中或是後續的驗證查看模型訓練是否產生Overfitting的問題。
import torch
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net.to(device)
num_epochs = 20
best_val_loss = float('inf')
train_losses, val_losses = [], []
for epoch in range(num_epochs):
# -------- Training --------
net.train()
running_loss = 0.0
for inputs, labels in trainloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# -------- Validation --------
net.eval()
val_loss = 0.0
correct, total = 0, 0
with torch.no_grad():
for inputs, labels in valloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_train_loss = running_loss / len(trainloader)
avg_val_loss = val_loss / len(valloader)
val_acc = 100 * correct / total
train_losses.append(avg_train_loss)
val_losses.append(avg_val_loss)
print(f"Epoch [{epoch+1}/{num_epochs}] "
f"Train Loss: {avg_train_loss:.4f} "
f"Val Loss: {avg_val_loss:.4f} "
f"Val Acc: {val_acc:.2f}%")
# -------- Save Best Model --------
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
torch.save(net.state_dict(), "best_cifar10_model.pth")
print(">> Model saved with Val Loss:", best_val_loss)
# -------- Plotting Training Curve --------
plt.figure(figsize=(10, 5))
plt.plot(range(1, num_epochs+1), train_losses, label='Train Loss')
plt.plot(range(1, num_epochs+1), val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss Curve')
plt.legend()
plt.grid(True)
plt.show()
輸出結果:
...
Epoch [15/20] Train Loss: 1.1974 Val Loss: 1.2446 Val Acc: 55.56%
>> Model saved with Val Loss: 1.2446476824675934
Epoch [16/20] Train Loss: 1.1670 Val Loss: 1.2554 Val Acc: 55.52%
Epoch [17/20] Train Loss: 1.1447 Val Loss: 1.2216 Val Acc: 56.44%
>> Model saved with Val Loss: 1.2215879235086562
Epoch [18/20] Train Loss: 1.1205 Val Loss: 1.1978 Val Acc: 58.04%
>> Model saved with Val Loss: 1.1978471565850173
Epoch [19/20] Train Loss: 1.1039 Val Loss: 1.1918 Val Acc: 57.80%
>> Model saved with Val Loss: 1.1918227981917466
Epoch [20/20] Train Loss: 1.0851 Val Loss: 1.1921 Val Acc: 57.70%
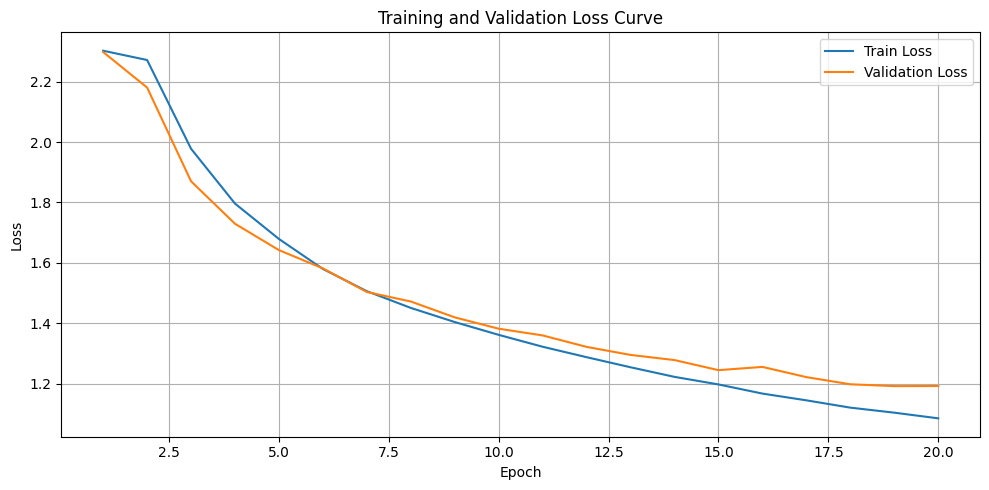
在訓練過程中,我們可以透過程式碼自動在驗證損失下降時保存模型,並繪製損失曲線圖來觀察模型的學習狀況。當我們看到訓練損失持續下降,就表示模型正在一步步學會資料中的特徵;如果驗證損失也跟著下降,那代表模型不只記住訓練資料,還能在新資料上有不錯的表現,顯示出良好的泛化能力。不過在訓練後期,若出現訓練損失持續下降,但驗證損失開始上升的情況,就要小心這可能是過擬合。遇到這種狀況時,可以考慮提早停止訓練,或是透過更換優化器、修改模型架構、加入正則化或資料增強等方法來改善。
當模型訓練告一段落,接下來最關鍵的,就是進行最終測試。我們只需要載入訓練期間表現最好的模型權重,接著透過測試資料看看它在真實環境下的表現如何。
# 載入訓練期間表現最佳的模型
best_model = Net().to(device)
best_model.load_state_dict(torch.load("best_cifar10_model.pth", map_location=device))
best_model.eval()
這邊我們會用先前準備好的 testloader 來進行測試。理論上如果模型沒有發生 overfitting,那它在測試集上的準確率應該會和驗證集差不多。反之,如果測試結果落差很大,那就有可能是訓練過程中出了些狀況——可能是資料分布不平均,也有可能是模型架構或訓練方式需要重新檢視。現在就讓我們實際測試看看成果如何吧:
import torch
import torch.nn as nn
criterion = nn.CrossEntropyLoss()
test_loss = 0.0
correct, total = 0, 0
best_model.eval()
with torch.no_grad():
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = best_model(inputs)
loss = criterion(outputs, labels)
test_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_test_loss = test_loss / len(testloader)
test_acc = 100.0 * correct / total
print(f"[Test] Loss: {avg_test_loss:.4f} | Acc: {test_acc:.2f}%")
輸出結果如下:
[Test] Loss: 1.1549 | Acc: 59.14%
從結果可以看出,我們的模型最終達到了大約 60% 的準確率。雖然不是特別高,但這其實也代表模型已經進入了收斂狀態換句話說,它已經學到了它目前能學到的最佳表現。那接下來呢?這就是深度學習中最有挑戰性的部分了:如何更進一步優化模型。
這時候我們可以開始探索像是:
訓練的流程基本上大同小異,目前我們都是透過手動的 for 迴圈來跑完整個訓練過程,包括訓練、驗證、測試,還有手動儲存表現最好的模型。這種做法雖然能讓我們一目了然每個細節,但隨著模型變得越來越複雜、需要測試的超參數組合越來越多,這樣的方式就顯得冗長且不易維護。
因此從明天開始,我們會動手打造一個通用的 Trainer 類別,讓整個訓練流程變得更有系統。我們希望能把訓練邏輯包裝成一個模組化、可重複使用的工具,讓後續不論是改模型、換資料集,甚至更新章節內容,都可以沿用同一套訓練器。這樣一來,我們可以把重心放回在「模型的設計與優化」上,而不是被大段樣板程式碼拖住進度。


 iThome鐵人賽
iThome鐵人賽