經過兩週的練習,從最基本的文字生成、參數調整,到各種NLP應用,我已經能在Colab上跑出不少有趣的結果。接下來的第三週,我想聚焦在一個更核心的主題:Prompt。
簡單來說,Prompt就是我們給AI的指令。有點像是考試題目,題目怎麼出,學生就怎麼答。AI雖然不是人,但它也會根據我們的輸入去決定生成的方向。
為什麼要特別拿Prompt出來談?因為同樣一段文字,如果前面加上不同的要求,AI產生的內容就會完全不一樣。這也是現在大家常說Prompt 工程的由來,怎麼設計輸入,會直接決定輸出品質。
實際操作
一開始我用最基本的gpt2模型來測試不同的提示詞,程式碼如下:
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2")
# 同一句話,不同提示
prompt1 = "請幫我寫一首關於人工智慧的詩:"
prompt2 = "請用新聞報導的方式寫人工智慧的影響:"
result1 = generator(prompt1, max_length=60, num_return_sequences=1)
result2 = generator(prompt2, max_length=60, num_return_sequences=1)
print("詩歌風格:\n", result1[0]["generated_text"], "\n")
print("新聞風格:\n", result2[0]["generated_text"])
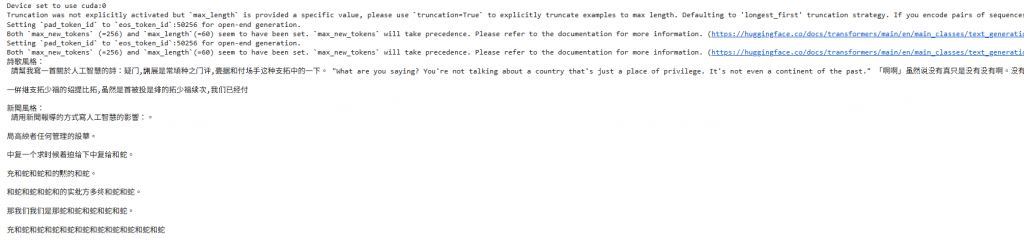
跑出來的結果讓我嚇了一跳,新聞風格的內容到後面突然跳出一段英文對話,詩歌風格則是陷入蛇和蛇和蛇...的重複,像是卡在迴圈一樣。
經過查證發現,這種情況在生成式AI裡其實蠻常見的,凸顯了GPT-2這類早期模型的限制。但原因我就先不在這邊展開了,之後再專門做一篇來解釋!
因此我接下來改用Hugging Face上的中文指令微調模型,再加上更明確的Prompt
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
model_id = "Qwen/Qwen2-1.5B-Instruct"
tok = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id, device_map="auto", torch_dtype="auto", trust_remote_code=True
)
pipe = pipeline("text-generation", model=model, tokenizer=tok)
prompt_poem = "你是詩人。請用現代中文寫四行短詩,主題:人工智慧。每行≤12字,避免重複詞。"
resp = pipe(prompt_poem, max_new_tokens=120, do_sample=True,
temperature=0.7, top_p=0.9, repetition_penalty=1.1,
no_repeat_ngram_size=4)[0]["generated_text"]
print(resp)
prompt_news = "你是科技記者。請用新聞口吻寫三句話,主題:人工智慧在醫療的應用,避免詩句與贅詞。"
print(pipe(prompt_news, max_new_tokens=120, do_sample=True,
temperature=0.7, top_p=0.9)[0]["generated_text"])
得出的結果如圖,內容相較第一次更有詩和新聞報導的感覺。可以很清楚看到Prompt+模型選擇對輸出結果的影響。

