經過了 7 天不同情況、時間點,來看 LLM 輸入問題前會經歷的各種事,是時候在概念的角度上做一個小結了。

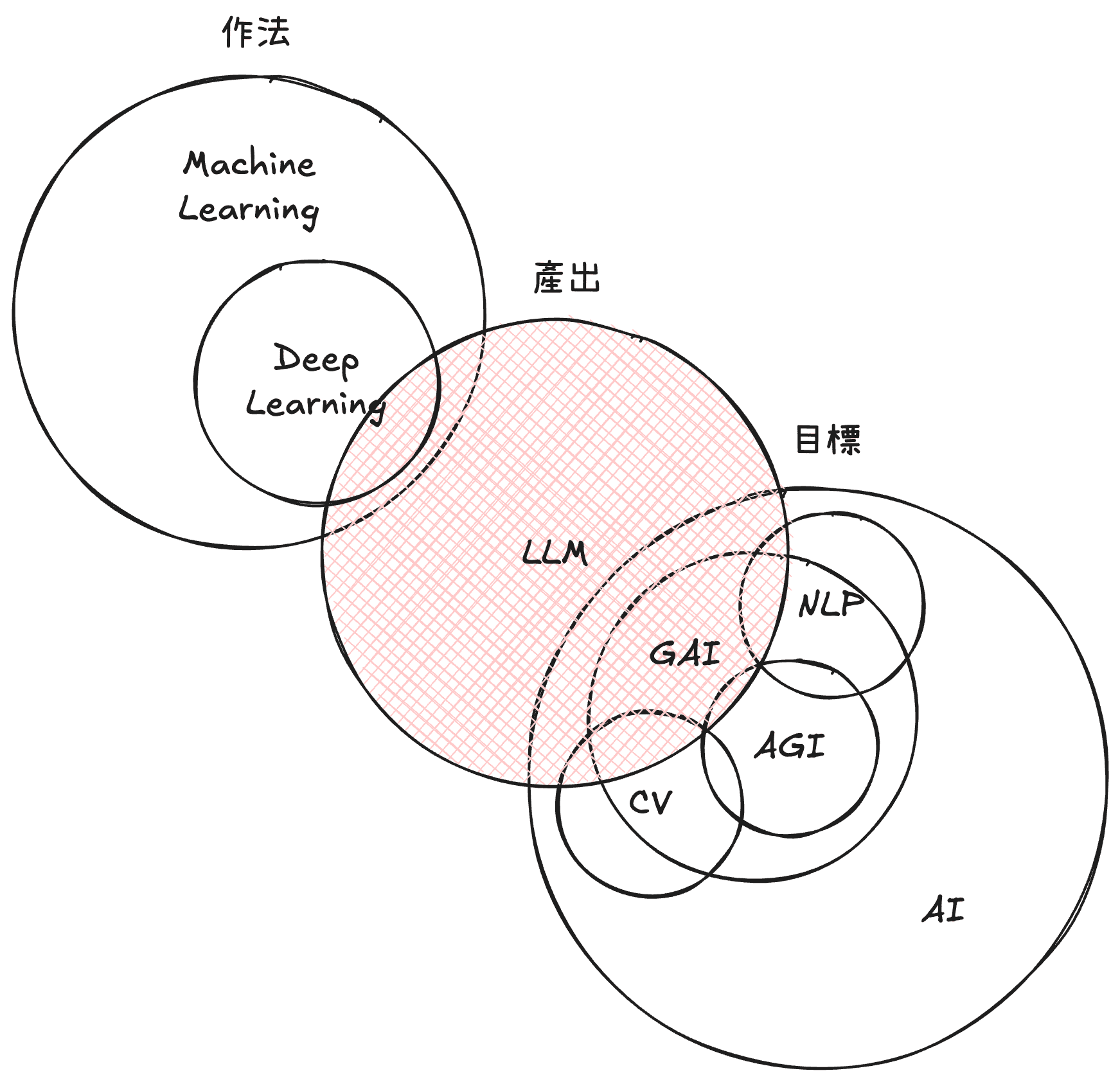
AI 人工智慧是一個人類持續想要達到的目標,這個目標希望讓機器趨近甚至超越人類的所有智慧,如果有朝一日真的做到了終點,那種 AI 叫做通用人工智慧 Artificial General Intelligence (AGI)。其中在 AI 中,有一個目標是生成式 AI (Generative AI),也就是能生成彷彿與人類能創造無異的人工智慧。
AI 領域歷史悠久,除了 Generative AI 外,在視覺辨識問題上有電腦視覺 Computer Vision (CV) 、在文字理解問題上有自然語言處理 Natural Language Processing (NLP) 這些研究領域,運用了各種作法來達到上述各自領域目標。其中一個作法是現在很多領域都會用到的:機器學習 Machine Learning,而機器學習中又有一個更好用的作法叫深度學習 Deep Learning。總之,不同的作法會有各有特色的模型,如今已經可以做出 大型語言模型 Large Language Model (LLM) ,來達到生成式 AI 目標。
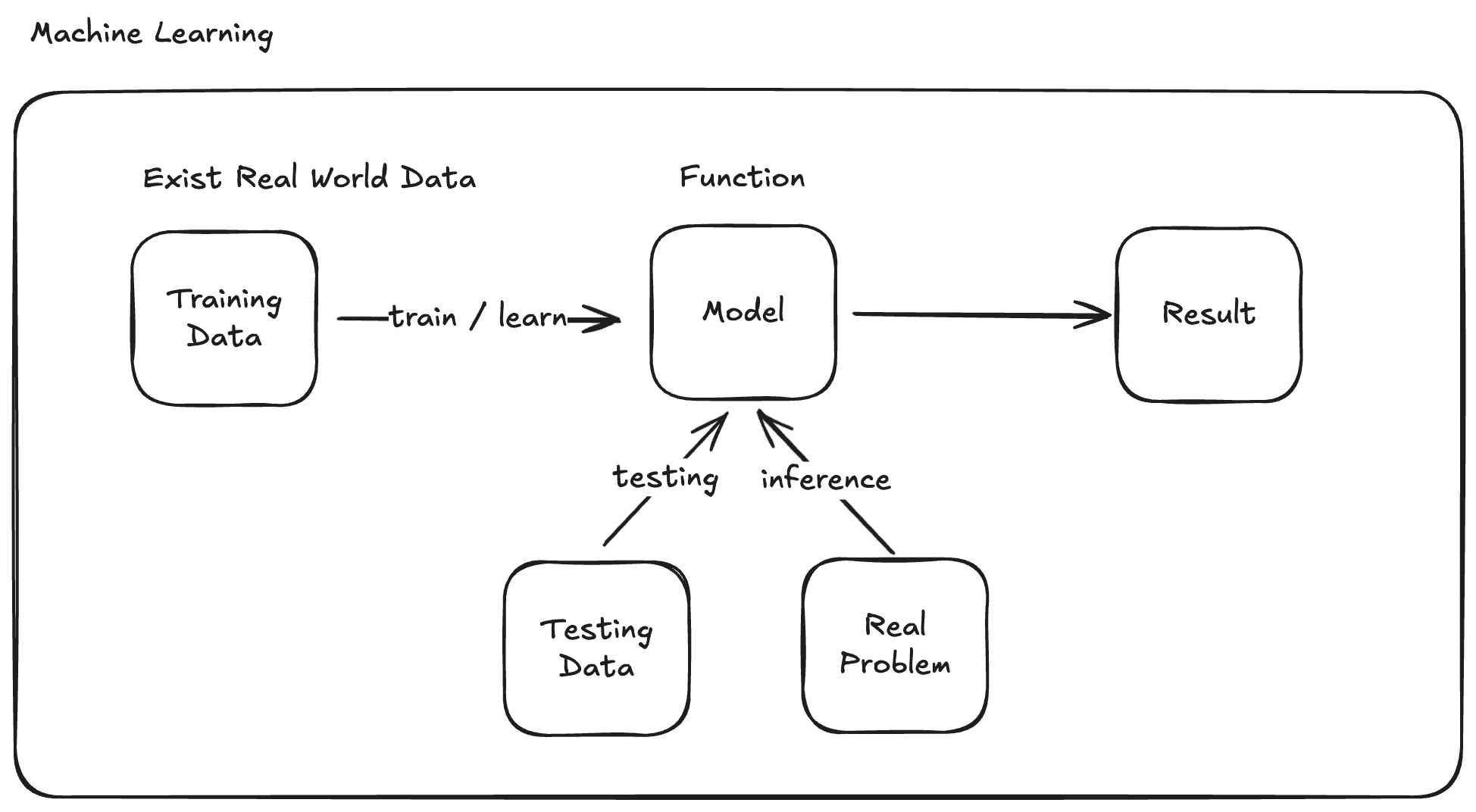
那模型(Model)是什麼,模型的本質就是一個能夠給 x 就能預測出 y 的方程式,簡單至二維上的一條斜線,複雜到要能給一個句子,就預測出後面要生成什麼字,都還是方程式。只是後者的方程式因為要預測的情況更為複雜,會擁有非常多的參數(Parameter)才能得到符合人類預期的成果。
流程上,模型透過大量訓練資料(Training Data) 來學習找出最接近答案的參數組合。學習出來後,再透過測試資料(Testing Data)來驗證學的好不好。又或者不透過測試資料,直接拿真實環境來實戰推論(Inference)。
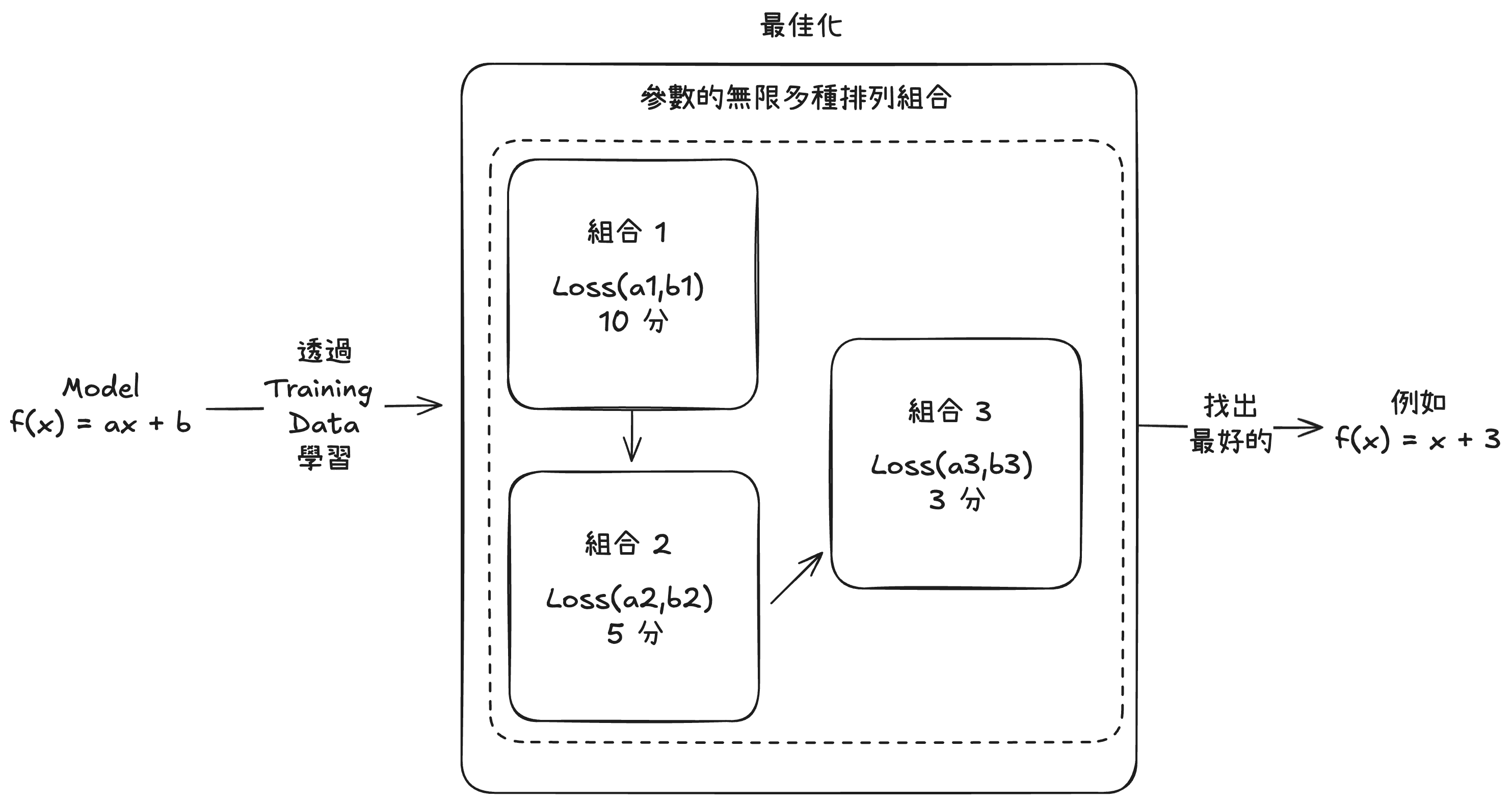
更詳細地說,模型會先定義一個方程式的架構,例如:f(x) = ax + b 就是一種架構,並決定需要幾個參數,以上述為例 a 作為權重(Weight) 與 b 作為偏移 (Bias) 就是兩個參數。
其中我們透過大量 f(x) 與 x 組合而成的訓練資料,我們會去定義一個損失函數(Loss Function) 以評估模型在各個參數組合下,以與訓練資料的實際差距來算差幾分。接著透過最佳化(Optimize)作法讓模型可以在有限資源下,找出在訓練資料中的最佳表現。
當然上述是最微觀且簡略地說法,現在的模型已經複雜到會有層層模型疊加並搭配各種前後處理的環節,而這其中有一個經典架構叫做 Transformer,大量的運用在涉及有情境、有上下文情境的 AI 問題中。
模型就如同所有技術的演進,一個模型誕生後也很難一次到位。
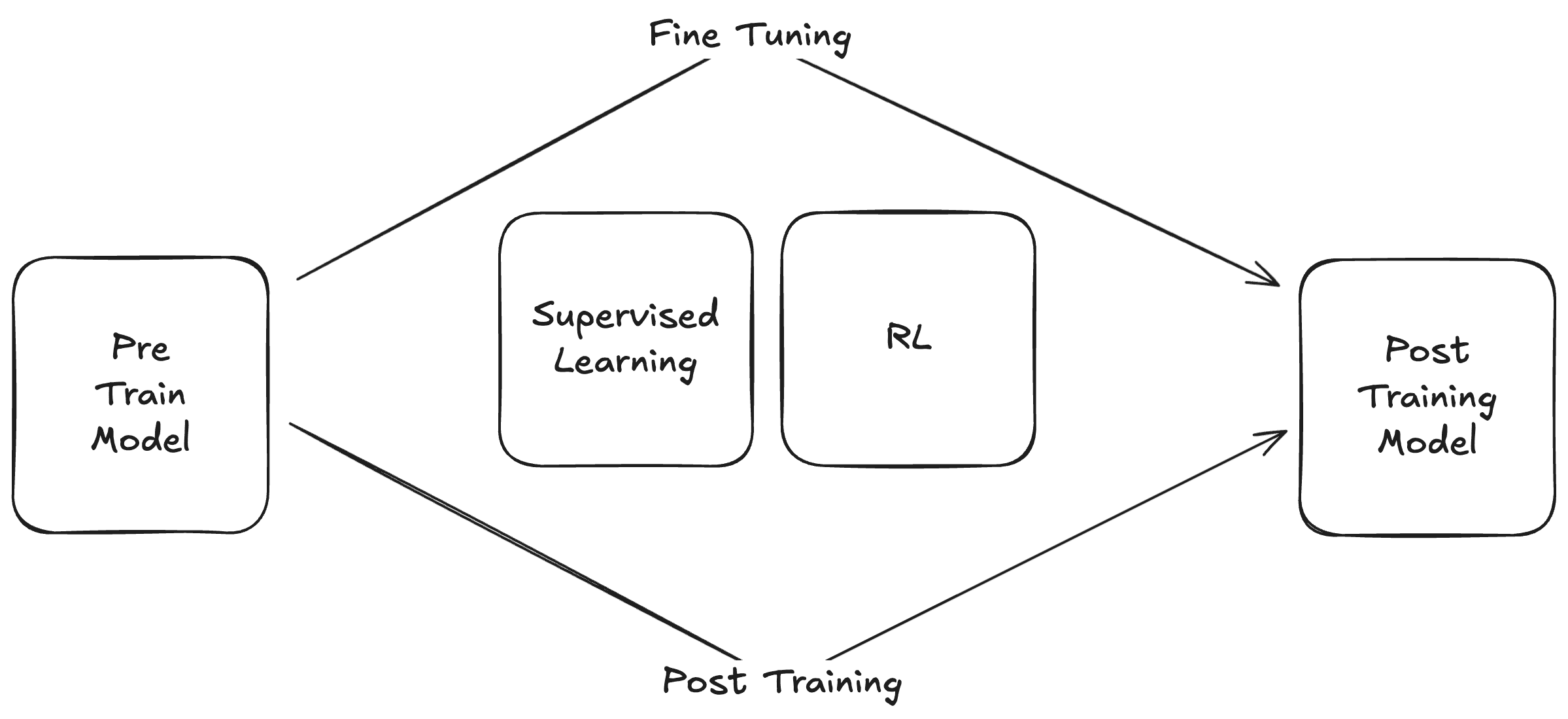
哪怕我們餵給模型史上巨多資料訓練出巨多參數,可能一開始還有一些改善,也逐漸來到一個瓶頸。但姑且我們稱這種餵過巨多資料、資料也沒做太多處理,透過非監督式學習(Unsupervised Learning) 訓練出巨獸模型叫大型語言模型(LLM)。一個沒經過任何微調的 LLM 時常成為後來我們實際使用的 LLM 的前訓練(Pre Train)模型當成基底,接著在搭配一些後訓練 (Post Training) 或微調(Fine Tuning) 來。常見的作法有監督式學習(Supervised Learning)補上有人類標記、或更精緻的資料來做訓練,或者強化學習(Reinforcement Learning)搭配將最終成果的表現一併考量進來的學習方式,來後訓練模型。
但有的時候實在來不及了,我們改不了模型的體質,至少可以改變使用他的方式,而在 LLM 中,因為我們跟模型的主要互動方式都是透過一段文字去提示(Prompt)模型,請它生成我們期待的結果。而僅改善提示,以得到更好結果的領域就叫做 Prompt Engineer。提示也不僅僅只是一次性的提問,有時我們可以接二連三的去提示 LLM 也是一種互動方式,這種連續將第一步 LLM 生成的結果提供給下一步的一條 LLM 鍊(Chain),也是 Prompt Engineer 會去討論的設計環節。
當我們在一個像是對話視窗,輸入一段 Prompt 按下送出後,我們的電腦會與提供服務的 Server 建立一個單向通道。Prompt 會被送往提供模型服務的模組,一開始是先被切成一塊塊切塊(Token) 接著轉換成數學意義上的向量(Embedding)也就是前面時常提到的神秘編碼。
接著跑過 Transformer 架構中最著名的 Attention 機制,計算在上下文中應該怎麼重新得到新的向量,最後在一個清單中,找出數學意義下最接近的文字,透過單向通道送回顯示在對話視窗上。
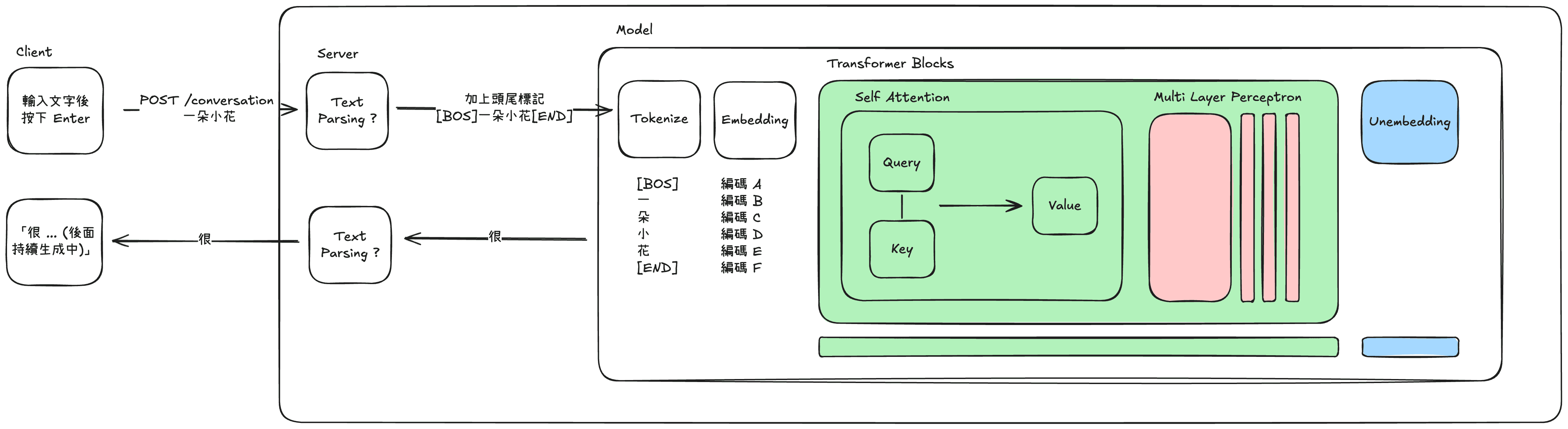
但現代的 LLM 不只會回下一個字,他可以回你圖片、回你語音、甚至幫你操作電腦做一件事,這種可以代替你做東做西的解決方案,叫做代理(Agent)。代理也不是近幾年才有的方案,但有了用 LLM 打造的代理比過去的要聰明多。Agent 可以比過去更洞悉使用者意圖,透過背後所擁有不同的工具庫達成多種任務。
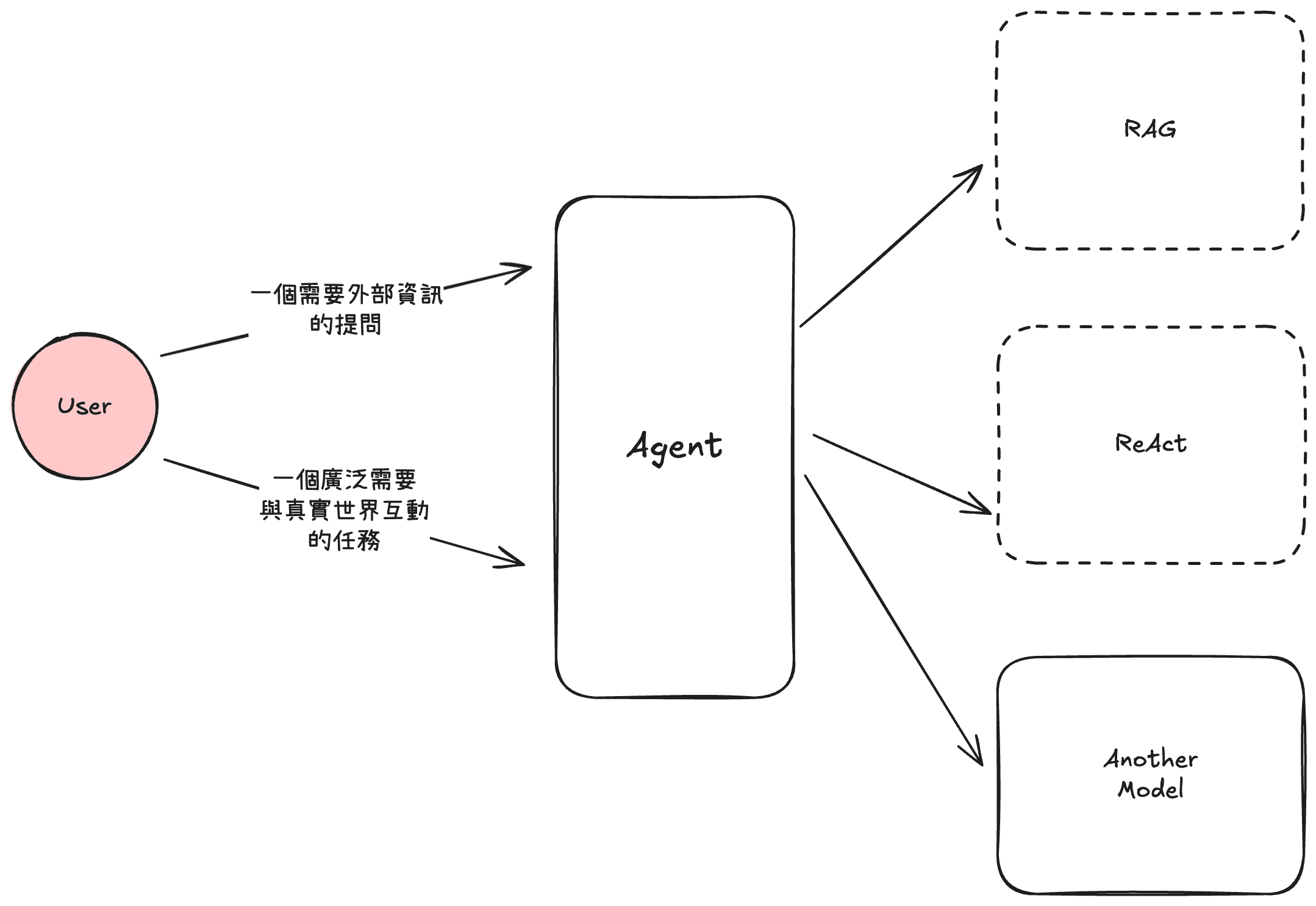
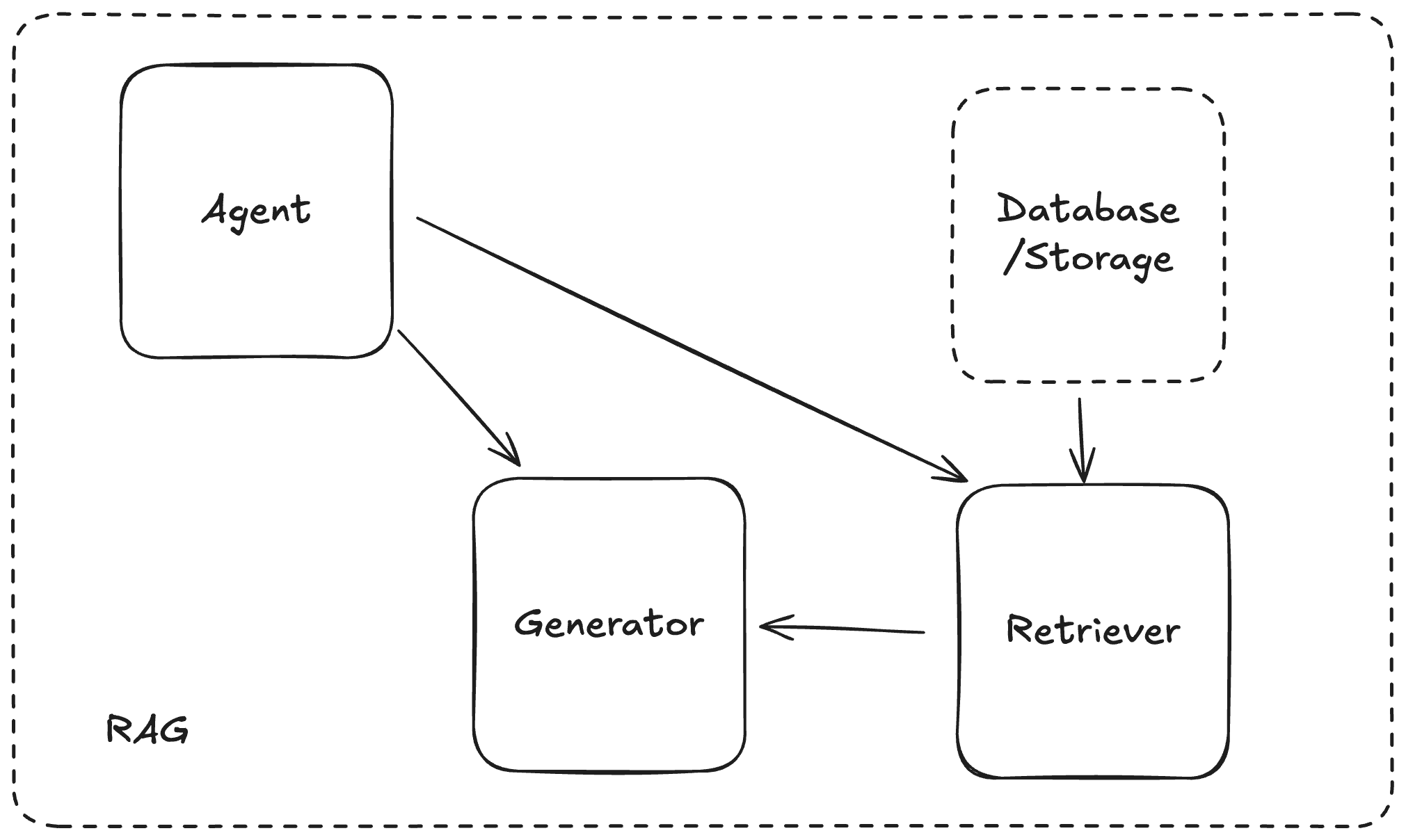
如果今天是一個要能回答特殊領域知識、或當初訓練時不知道的問題,最有名的有 Retrieval-Augmented Generation(RAG) 架構來解決這個問題。透過訓練一個善於查找資訊的檢索器(Retriever) 補足一開始使用者透過 Agent 發來提示中的上下文,以取得更好的生成結果。
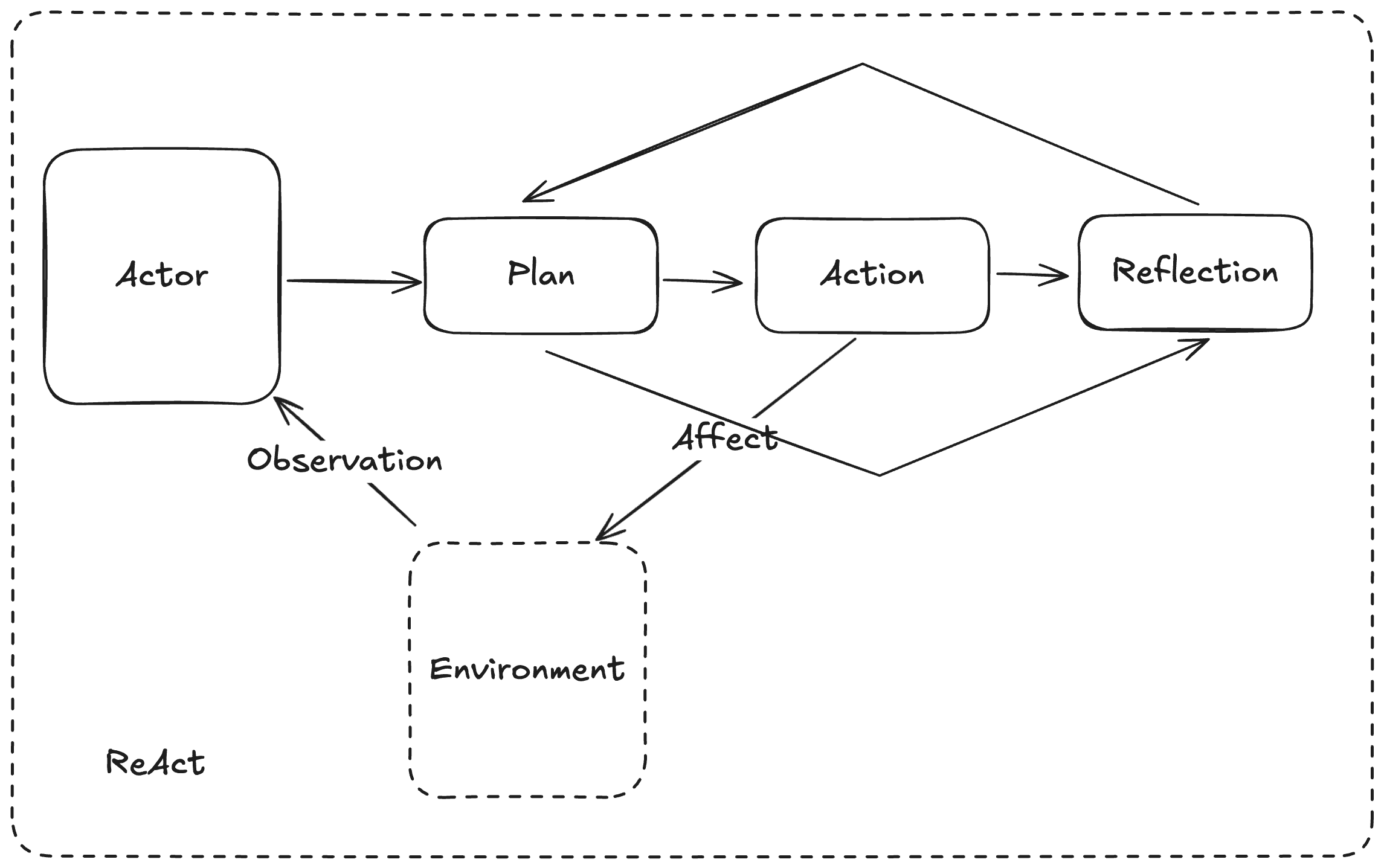
如果廣泛想要達成一些現實世界任務,則有 ReACT 模式來做到,讓模型接收來自環境(Environment) 的刺激來採取行動(Action),其中行動包含了:規劃、執行與從中的反思,藉此來更好的達成提示目標。
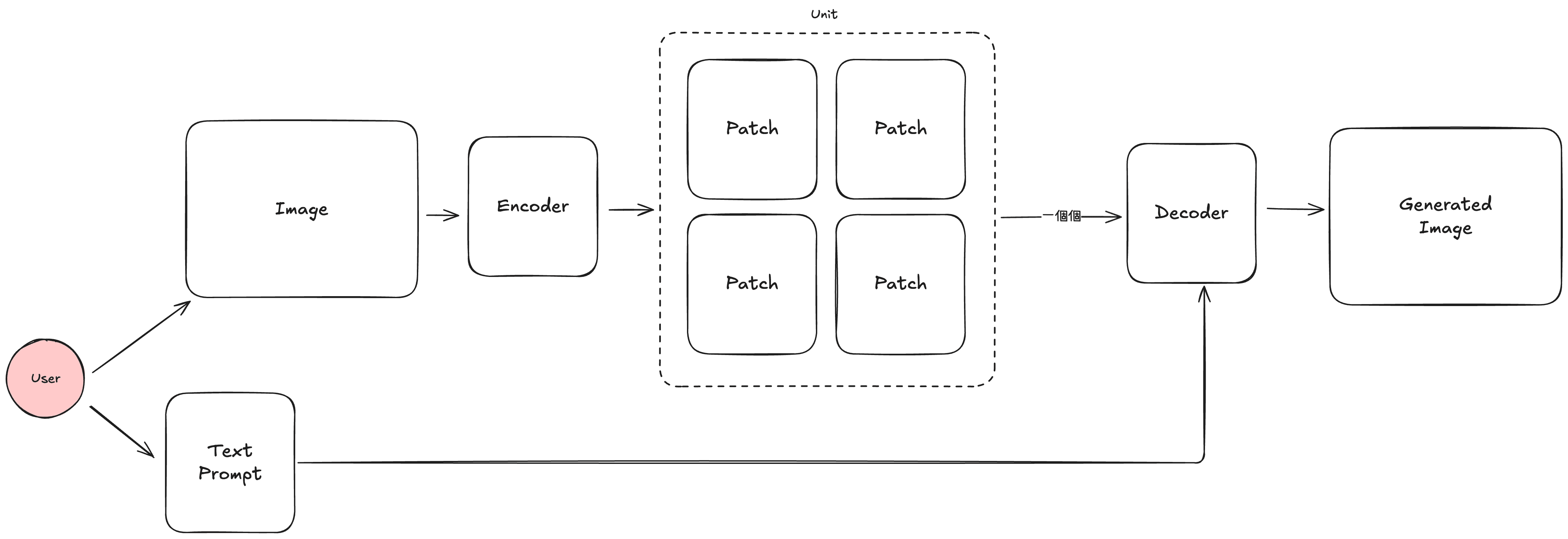
又或者只是更單純的直接轉交給一個強項不同的模型,例如一個能處理多模態(Multi Modal) 的模型,強項於語音、圖片甚至影片的多模態模型,因為輸入的最小單位與語言不同,這些多模態模型在訓練與生成流程上也與一般 LLM 不同。
以最具代表性的圖片為例,因為圖片的最小單位為像素,要以像素為單位來處理圖片生成太消耗資源了,所以會先透過編碼器(Encoder) 將圖片拆成一個個分塊(Patch),接著加入希望的 Prompt 與 Patch 們一起,送去解碼器(Decoder)來生成期望中的圖片。
藉由回答「從 LLM 輸入問題後、按下 Enter 後會發生什麼事?」如今總算稍稍瞭解 AI 領域的最淺最淺層。而過程中有很多概念在腦裡也處於仍舊很抽象的階段。接下來的段落,將會實際參考實做的資源,一天天的做出最小可行的 LLM,將在腦中仍抽象的概念具體化一些。


 iThome鐵人賽
iThome鐵人賽