大語言模型(Large Language Model 或者LLM)是一種人工智慧模型,它的主要功能是「理解文字並生成文字」。你可以把它想像成一個超大型的「文字自動補全器」,不只是能猜出下一個字,而是能回答問題、寫文章、翻譯語言、甚至寫程式。
LLM 的原理是透過「機器學習」裡的一種技術叫 「深度學習」。模型會讀取大量的文字資料(像是書籍、文章、網頁),學習其中的語言規則與知識。它並不是逐字死背,而是透過一種叫做 Transformer 的架構來理解句子中每個詞和其他詞的關係。這樣一來,它就能產生聽起來自然、甚至有邏輯的內容。
在 LLM 出現之前,自然語言處理(NLP)模型主要用兩種方法來處理文字:
問題是:當句子很長時,前面的資訊會被「遺忘」或變得模糊。
那到了 2017 年,Google 發表了一篇劃時代的論文:《Attention Is All You Need》
在這篇論文裡,他們提出了一個全新的架構 —— Transformer。它拋棄了 RNN 的「逐字讀取」,改用 Attention 機制,可以一次「同時關注」句子裡不同位置的詞,這讓模型能夠有效理解「長距離的語意關係」,例如在一句話中,主詞和動詞可能隔很遠,Transformer 也能正確對應。
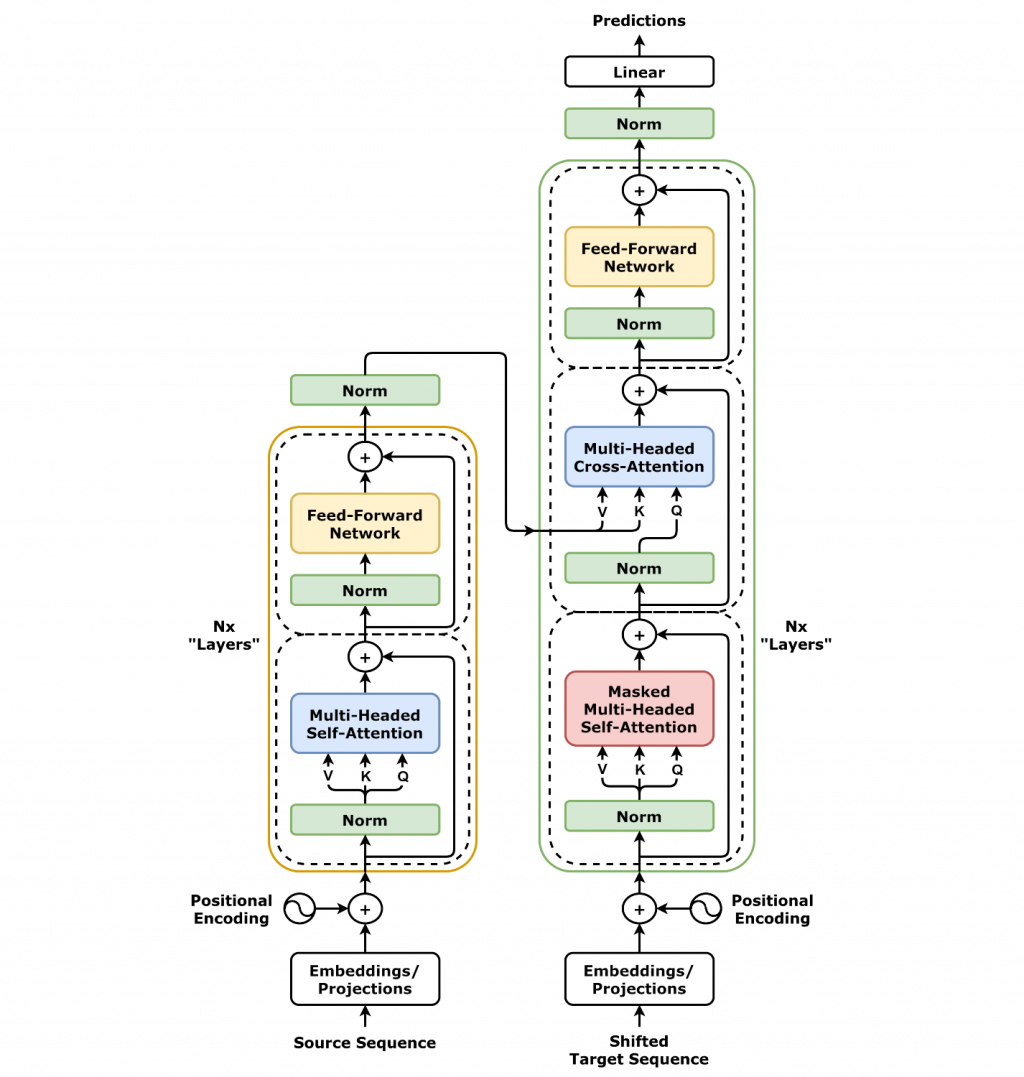
舉例來說:
你問「太陽為什麼會發光?」它會根據訓練時學到的知識回答科學解釋。
若你要求它「幫我寫一首小詩」,它會生成有韻律的詩句。
簡單來說,LLM 就像一個經過大量閱讀訓練的超強文字助手,可以用來做聊天機器人、搜尋引擎、寫作輔助、客服回應等等。

