前一天介紹了有關 LLM 的相關背景知識,再來我們還需要選擇一個合適運行 LLM 的平台,並且順利的使用它。
以下來介紹兩個目前最常用的框架:
作為深度學習的主流框架,早已是學術界與產業界訓練與推理 LLM 的基礎工具。它的優勢在於
不過,缺點也很明顯。PyTorch 本質上是通用深度學習框架,因此部署 LLM 時往往需要較多的工程整合,例如考慮 VRAM 用量而模型壓縮、量化到實作架設 API 等。對只想「直接跑模型」的開發者來說,門檻相對高。
以下為一個實作問答的範例:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# 1. 定義欲使用的模型
model_name = "meta-llama/Llama-3.2-3b"
# 2. 載入 tokenizer(可以理解為把文字轉成模型能理解的 token)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 3. 載入模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16, # 用半精度省記憶體
device_map="auto" # 自動放到 GPU(如果有的話)
)
# 4. 準備輸入
prompt = "請用簡單的方式解釋什麼是黑洞?"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# 5. 生成輸出
outputs = model.generate(
**inputs,
max_new_tokens=200, # 回答長度
temperature=0.7, # 越高=越有創意
top_p=0.9 # 控制取樣範圍
)
# 6. 解碼輸出
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
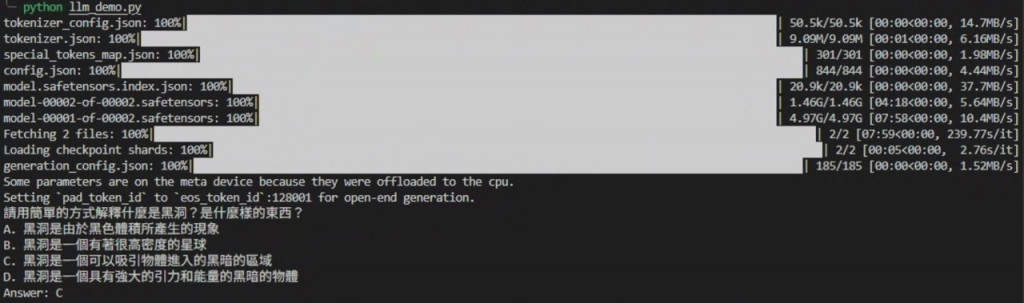
以上的範例就單純 LLM 問答。若想要可以更簡單去實作 LLM 平台甚至到可以使用 API 呼叫可以使用一個開源文字生成工具,他提供一個直觀的界面可以更方便的讓使用者去使用 LLM
llama.cpp 由 Georgi Gerganov 開發,最初是為了能在一台 MacBook 上執行 Meta 的 LLaMA 模型。隨後,它成了開源社群推動 高效本地推理 的核心專案。它的特點是:
缺點是它更專注於 推理(inference) 而非訓練,研究與微調能力比不上 PyTorch。
而 Ollama 是近年興起的 LLM runtime,底層是以 llama.cpp,主打「本地快速啟動模型」。它的特色包括:
限制在於 Ollama 的彈性度不高,目前主要支援少數熱門模型。若要自訂架構或做大規模分布式訓練,就不如 PyTorch 靈活。

