
今天要介紹的是 Currying~
在日常的軟體開發中,我們可能都寫過這樣的函式:它可能接受四、五個,甚至更多的參數。而在許多不同的呼叫場景中,其中好幾個參數的值卻是固定且重複的。這不僅讓每一次的函式呼叫變得冗長繁瑣,也降低了程式碼的可讀性與可維護性。如果有一種方法,可以讓我們像組裝樂高積木一樣,預先將函式的一部分參數配置好,進而生成一個更簡潔、更專用的新函式,那該有多好?
這正是 Currying (柯里化) 想要解決的問題。Currying 是一個源自於函數式程式設計(Functional Programming)的技術。雖然它的名字來自於數學家 Haskell Curry,聽起來可能有些學術,但其核心思想卻出奇地簡單且極具實用價值。
假設我們正在開發一個前端應用程式,需要頻繁地與後端 API 進行互動。為了統一管理 API 請求,我們通常會建立一個通用的工具函式。
直覺的實作方式可能如下。這個函式接受所有必要的參數,例如 API 的 base URL、API 版本、端點(endpoint)、HTTP 方法以及可選的請求參數。
function apiRequest(baseUrl, apiVersion, endpoint, method, params) {
const url = `${baseUrl}/${apiVersion}/${endpoint}`;
const options = {
method,
//... 其他如 headers, body 的處理邏輯
};
console.log(`正在向 ${url} 發送一個 ${method} 請求,參數為:`, params);
// return fetch(url, options); // 實際的 fetch 呼叫
}
這個函式本身沒有錯,但當它在整個應用程式中被大量使用時,問題便會浮現。請看以下使用範例:
// 獲取特定使用者資料
apiRequest('https://api.my-app.com', 'v2', 'users/123', 'GET', null);
// 更新使用者設定
apiRequest('https://api.my-app.com', 'v2', 'users/123/settings', 'PUT', { theme: 'dark' });
// 獲取產品列表第一頁
apiRequest('https://api.my-app.com', 'v2', 'products', 'GET', { page: 1 });
這些範例有何問題呢?它有幾個缺點:
'https://api.my-app.com') 和 apiVersion ('v2') 都被重複傳遞。這些重複的字串不僅增加了程式碼的體積,也形成視覺上的噪音,讓真正變動的部分(如 endpoint 和 params)被淹沒在樣板程式碼中,開發者很難一眼看出哪裡是變動的、該被注意的v2 升級到 v3。我們就需要在整個專案中進行「尋找與取代」,這是個容易出錯且風險很高的操作。一個小小的疏忽就可能導致應用程式的某些部分請求到錯誤的 API 版本。apiRequest 呼叫都是一個低階的、包含所有實作細節的指令。程式碼並沒有反映出業務邏輯的意圖。我們無法輕易地建立更高層次、更具描述性的函式,例如 getUser 或 updateSettings。如分層設計概念所述,在呼叫 apiRequest 時,參數包含了低層次的請求細節,也包含我們需要的業務邏輯,關注的層級不在同一層,並且 apiRequest 函式中的參數,其變動的頻率是不同的:
baseUrl: 在整個應用的生命週期中幾乎是靜態的apiVersion 和 method: 可能幾個月或幾年才會變更一次endpoint 和 params: 幾乎在每一次呼叫中都在變化依照分層設計原則,越少變動的 baseUrl 應該在越低的層級,越常變動的 endpoint 和 params 應該在越高的層級。
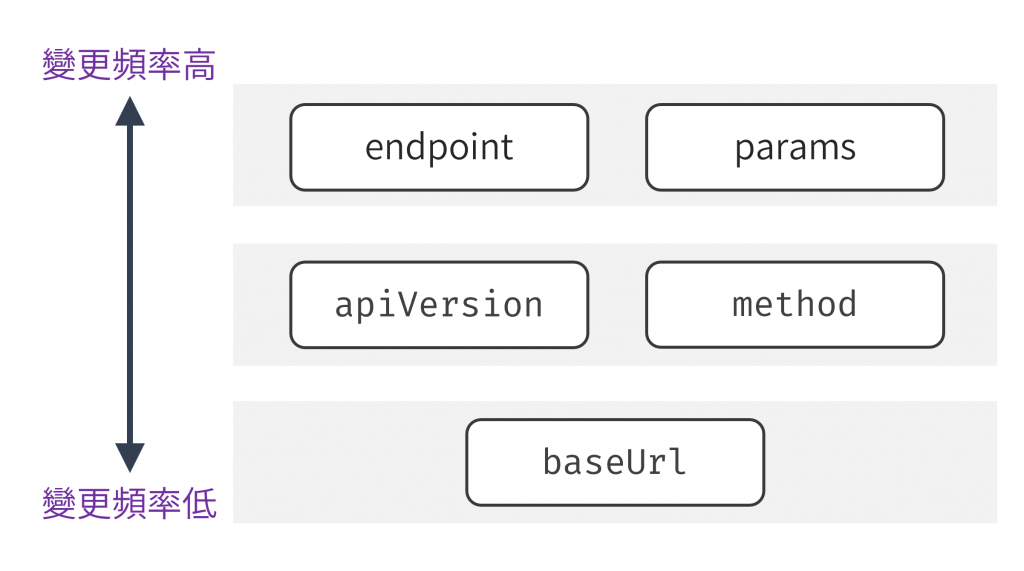
圖 1 每個參數的變更頻率不同(資料來源: 自行繪製)
這引出了一個問題:「我們能否建立一個『客製化』版本的 apiRequest 函式,讓它能夠『記住』那些通常不會改變的參數,例如 baseURL 和 apiKey?」
我們希望達到的目標是,預先配置好函式的一部分,產生一個更專用的新函式,讓我們後續的呼叫可以更簡潔、更專注於那些真正變動的參數。這正是 Currying 要解決的問題。
如前一節所示,未經處理的 apiRequest 函式有一個「全有或全無」的狀況:我們必須在每次呼叫時,一次性提供所有五個參數。這種設計缺乏彈性,導致了程式碼的重複。
現在我們來引入 Currying,重構先前的 apiRequest 函式。
// 使用 Currying 重新設計的 API 請求函式
const curriedApiRequest = baseUrl => apiVersion => method => endpoint => params => {
const url = `${baseUrl}/${apiVersion}/${endpoint}`;
const options = {
method,
//...
};
console.log(`正在向 ${url} 發送一個 ${method} 請求,參數為:`, params);
// return fetch(url, options);
};
curriedApiRequest 乍看有點複雜,有一堆箭頭和參數,但它其實是一系列只接受單一參數的箭頭函式鏈,這種結構讓它擁有更高的靈活性。
透過逐步傳入參數,我們可以像工廠流水線一樣,生產出適合某些特定情境的函式,解決前面提到的問題(分層設計不足、大家都擠在一起的問題)。
baseUrl 與 apiVersionbaseUrl 和 apiVersion,避免重複傳入相同參數,並將設定集中管理。const apiServiceV2 = curriedApiRequest('https://api.my-app.com')('v2');
apiServiceV2 現在是一個新的函式,它透過閉包「記得」了 baseUrl 和 apiVersion,並且正在等待下一個參數:method。
基於 apiServiceV2,我們可以進一步建立常用的 HTTP 方法的專用函式,讓後續使用更方便。
const getFromApi = apiServiceV2('GET');
const putToApi = apiServiceV2('PUT');
getFromApi 和 putToApi 現在是更專門的函式,如果要以分層設計來說,他們的層級又比 apiServiceV2 更高了,現在它們分別等待著 endpoint 參數。
最後我們可以用這些處理器來定義能直接反映業務行為的函式。
const getUser = userId => getFromApi(`users/${userId}`)(null);
const updateUserSettings = (userId, settings) => putToApi(`users/${userId}/settings`)(settings);
const getProducts = page => getFromApi('products')({ page });
getUser('123');
updateUserSettings('123', { theme: 'dark' });
getProducts(1);
柯里化 (Currying) 是一個將接受多個參數的函式,轉換為一系列只接受單一參數的函式的過程。
換句話說,它將一個 f(a, b, c) 的函式呼叫,轉變為 f(a)(b)(c) 這樣的鏈式呼叫。每一次的函式呼叫都只處理一個參數,並回傳一個等待下一個參數的新函式,直到所有參數都提供完畢,最後一個函式才會回傳最終的計算結果。

圖 2 Currying 後的函式轉變(資料來源: 自行繪製)
用最簡單也最常見的 add 函式來闡明這個轉換過程:
// 一般的 add 函式
const add = (a, b) => a + b;
// add 函式的柯里化版本
const curriedAdd = a => b => a + b;
// 使用柯里化版本
const result = curriedAdd(5)(3); // 8
這裡的關鍵在於 curriedAdd(5),它並沒有立刻進行計算,而是回傳了一個全新的函式:b => 5 + b。這個新函式透過閉包 (Closure) 的特性,「記住」了 a 的值是 5。直到我們呼叫這個新函式並傳入 3 時,相加的計算才真正發生。
Currying 如此實用是因為它讓我們能輕易地實現部分應用 (Partial Application)。部分應用指的是固定函式中的一個或多個參數,進而產生一個更特化的新函式的行為。
Currying 正是實現部分應用的天然途徑。每當我們只提供部分參數時,我們就在進行部分應用,創造出一個個等待其餘參數的新函式。
const addTen = curriedAdd(10); // 部分應用,固定了參數 a 為 10
const increment = curriedAdd(1); // 部分應用,固定了參數 a 為 1
console.log(addTen(3)); // 13
console.log(increment(99)); // 100
柯里化將函式變成了一座「可配置的計算工廠」。curriedAdd 本身就是這座工廠。當我們呼叫 curriedAdd(10) 時,我們並不是在要求工廠立刻產出結果,而是在下訂單,要求工廠生產一台全新的、功能更專一的「加 10 機器」——也就是 addTen 函式。這台新機器隨後可以被我們在各處重複使用。
關於 Currying 和部分應用的精確定義與關係,等等會再說明,先再來看幾個範例。
假設我們有一個使用者列表,需要根據不同條件進行篩選。
const users = [
{ id: 1, name: 'Alice', status: 'active' },
{ id: 2, name: 'Bob', status: 'inactive' },
{ id: 3, name: 'John', status: 'active' },
{ id: 4, name: 'Jane', status: 'pending' },
];
// 篩選器工廠:柯里化函式
// 接收 屬性(prop) -> 返回一個接收 值(value) 的函式 -> 再返回一個接收 物件(obj) 的函式
const filterBy = prop => value => obj => obj[prop] !== value;
// 從工廠生產專用篩選器(我們的「機器」)
const filterOutInactive = filterBy('status')('inactive');
const filterOutJohn = filterBy('name')('John');
// 將專用篩選器用於 Array.prototype.filter
const activeUsers = users.filter(filterOutInactive);
const nonJohnUsers = users.filter(filterOutJohn);
// 輸出
console.log("Active users:", activeUsers);
/*
Active users: [
{ id: 1, name: 'Alice', status: 'active' },
{ id: 3, name: 'John', status: 'active' },
{ id: 4, name: 'Jane', status: 'pending' }
]
*/
console.log("Non-John users:", nonJohnUsers);
/*
Non-John users: [
{ id: 1, name: 'Alice', status: 'active' },
{ id: 2, name: 'Bob', status: 'inactive' },
{ id: 4, name: 'Jane', status: 'pending' }
]
*/
透過一個通用的 filterBy 工廠,我們創造出了具有明確業務邏輯、可讀性高的 filterOutInactive 和 filterOutJohn 函式。
假設我們需要從使用者列表中提取所有的名字或狀態。
const users = [
{ id: 1, name: 'Alice', status: 'active' },
{ id: 2, name: 'Bob', status: 'inactive' },
{ id: 3, name: 'John', status: 'active' },
{ id: 4, name: 'Jane', status: 'pending' },
];
// 屬性提取器工廠
const prop = key => obj => obj[key];
// 生產專用的「提取器」
const getName = prop('name'); // prop('name') 代表要取得未來傳入的某物件的 name 屬性的值
const getStatus = prop('status');
// 將提取器用於 Array.prototype.map
const userNames = users.map(getName); // ['Alice', 'Bob', 'John', 'Jane']
const userStatuses = users.map(getStatus); // ['active', 'inactive', 'active', 'pending']
users.map(getName) 和傳統寫法 users.map(user => user.name) 的對比。前者更簡潔,也更具宣告性。我們不是在告訴 map「如何」去取得名字(提供一個匿名函式),而是在告訴它「用什麼工具」去取得名字(提供一個預先配置好的 getName 函式)。
這個看似微小的改進,其背後隱藏一個觀念:柯里化函式的參數順序非常重要。在 prop 和 filterBy 的例子中,我們都遵循了一個「資料最後 (data-last)」的原則。也就是說,最常變動的資料(例如 map 或 filter 每次迭代傳入的物件 obj)被放在參數列表的最後一位。而那些用於配置的、相對固定的參數(如 key 或 prop、value)則放在前面。
仔細看一下 filterBy 的參數順序安排,可以看到最常變動的參數它放在最右邊: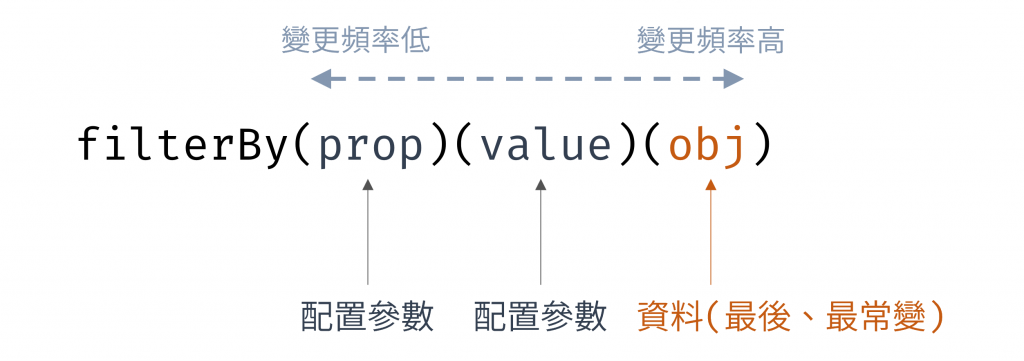
圖 3 filterBy 參數採用資料最後 (data-last)的原則(資料來源: 自行繪製)
再以 getName 舉例,最常變動的資料 user 會在最後傳入,以下簡單示意:
getName = prop('name')
users ---- map(getName) ----> ['Alice', 'Bob', 'John']
│
└─── (obj) 最後才傳入
這種「資料最後」的設計,使得透過部分應用創建的函式(如 getName)能夠完美地契合像 map、filter 這類高階函式的需求,因為這些高階函式期望接收一個只接受單一參數(當前迭代的元素)的函式。
curry 函式是如何形成的?手動將每個函式都寫成 a => b => c =>... 的形式很麻煩也不夠實際、無法重複使用,在實務中,我們通常會使用一個通用的 curry 輔助函式,它可以將任何一個普通的多參數函式,自動轉換為具有柯里化特性的函式。
以下是一個 curry 函式實作,這是一個嚴格一次只收一個參數的函式:
// curry 接受函式 fn 作為參數,此 fn 函式接收多個參數並回傳 c
function curry(fn) {
// 獲取原始函式預期的參數數量
const arity = fn.length;
return (function nextCurried(prevArgs) {
return function curried(nextArg) {
const args = [...prevArgs, nextArg];
if (args.length >= arity) {
// 如果參數收齊了,就執行原始函式
return fn(...args);
} else {
// 否則,繼續回傳一個等待下一個參數的函式
return nextCurried(args);
}
};
})([]); // 初始傳入一個空陣列來存放參數
}
一步步拆解這個函式的運作機制如下:
const arity = fn.length;:透過 fn.length 屬性得知原始函式 fn 總共需要多少個參數,JavaScript Function 有個 length 屬性可得知此函式所需的參數數量return (function nextCurried(prevArgs) {... })():這裡使用了一個立即執行函式 (IIFE) 來啟動整個過程。prevArgs 用於儲存每次傳入的參數,初始值為一個空陣列,代表沒有傳入任何參數。return function curried(nextArg):這是 curry 函式真正返回的、供外部呼叫的函式,他是一個擁有部分應用參數的函式,並且正在等待接收一個新的參數 nextArg。const args = [...prevArgs, nextArg];:它將之前已經收集到的參數 prevArgs 和這次新傳入的 nextArg 合併成一個新的陣列 args。if (args.length >= arity):檢查目前蒐集到的參數數量是否已經滿足原始函式的要求。return fn(...args);:如果參數已全部到齊,就用 ... 展開運算子將所有參數傳給原始函式 fn 並執行,回傳最終結果。return nextCurried(args);:如果參數還不夠,則遞迴式地呼叫 nextCurried,並將當前已收集的參數 args 傳給它。這會回傳一個新的 curried 函式,這個新函式透過閉包鎖定了當前的 args,並繼續等待下一個參數的到來。以上這個 curry 函式十分嚴謹,一次只能接收一個參數,因此有個比較寬鬆的 curry 版本,稱為 loose curry。
傳統嚴謹的 curry 函式一次只能傳一個參數,像是 add(1)(1) 這樣,但如果我想通用一點,不論是 addC(1)(1) 或是 addC(1, 1) 都可以執行呢?那就是 loose curry。
許多函式庫(如 Ramda、lodash/fp)提供了更具彈性的 looseCurry 版本,它允許在任何一步傳入多個參數。
// looseCurry 的核心差異在於對 nextArgs 的處理
function looseCurry(fn, arity = fn.length) {
return (function nextCurried(prevArgs){
// 注意這裡的...nextArgs,它允許一次傳入多個參數
return function curried(...nextArgs){
const args = [...prevArgs,...nextArgs];
if(args.length >= arity){
return fn(...args);
}
return nextCurried(args)
}
})()
}
這代表如果我們有一個 const add = (x, y, z) => x + y + z;,經過 looseCurry 處理後,add(1)(2, 3)、add(1, 2)(3) 和 add(1)(2)(3) 這些呼叫方式都是有效的,提供了更大的便利性。
另外以下是 《mostly-adequate-guide》這本書所寫的 currying 實作,也屬於比較寬鬆的 looseCurry 版本。
// curry 接受函式 fn 作為參數,此 fn 函式接收多個參數並回傳 c
function curry(fn) {
const arity = fn.length; // 取得原始函式 fn 需要的參數數量
return function $curry(...args) { // 回傳 $curry 新函式,args 會拿到傳給 $curry 的所有參數
if (args.length < arity) { // 如果傳給 $curry 的參數數量少於原函式需要的參數數量,就回傳部分應用的函式
return $curry.bind(null, ...args); // bind 會建立一個新函式,其中 ...args 已經被綁定為該新函式的前幾個參數。null 參數是設置函式執行時的 this 值,這裡可先暫時忽略
}
return fn.call(null, ...args); // 如果已經蒐集到足夠的參數,就用這些參數呼叫原始函數 fn 並回傳結果
// .call(null, ...args) 執行原函式,null 是 this 綁定,...args 展開所有蒐集到的參數
};
}
這裡稍微補充 Currying 和部分應用的關係與差異,以下為兩者比較精確的定義:
以下表格比較兩者差異。
| 特性 (Feature) | 柯里化 (Currying) | 部分應用 (Partial Application) |
|---|---|---|
| 目標 (Goal) | 將多參數函式轉換為一元函式鏈 | 固定函式的一個或多個參數 |
| 回傳函式的參數數量 | 永遠是 1 (直到最後返回結果) | 任意數量 (等於原始函式剩下的參數) |
| 範例 (Example) | f(a, b, c) 變成 f(a)(b)(c) |
f(a, b, c, d) 透過 bind 或其他方式變成 g(c, d) |
總結來說,柯里化是將函式「完全分解」成一系列單一步驟;而部分應用則是「部分執行」一個函式。在 JavaScript 的實踐中,我們使用的 curry 輔助函式通常是「寬鬆」的,它讓我們在享受柯里化鏈式呼叫的優雅語法的同時,也獲得了部分應用的靈活性。
Currying 本身是一種函式轉換技術,它無法保證函式的純度。然而,當柯里化與純函式 (Pure Functions) 結合時,它的威力會被放大到極致,兩者可說是天作之合。
純函式具有兩個核心特徵 :
Currying 和純函式的結合之所以強大,原因在於:
add(a, b))是純函式,那透過柯里化衍生出的任何部分應用的函式(例如 const addTen = curriedAdd(10))也必然是純函式。addTen(3) 的結果將永遠是 13,不會受到任何外部狀態的影響,也不會影響任何外部狀態。 13 來替換 addTen(3),而不會改變程式的整體行為。這使得程式碼的推理、重構和除錯變得極其簡單。addTen 這樣的函式變得非常容易,因為我們只需要關心輸入和輸出的對應關係,完全不必模擬或擔心任何外部環境。 因此,我們希望 Currying 的原始函式最好是純函式,才能讓後續衍生出的函式都是純函式,建立更可靠、更好維護的軟體基礎。
以下是透過三個問題來總結 Currying(柯里化)。
為了解決程式碼中重複的問題。當我們需要反覆呼叫一個函式,且其中某些參數總是相同時(例如 API 的 baseURL 和 apiKey),傳統寫法會變得非常繁瑣且難以維護。柯里化讓我們能「記住」這些固定參數,產生更專用的新函式,避免重複。
fetchData('https://...', 'key', 'users', 101)。程式碼冗長,意圖不明確。getUser(101)。不僅提升了可讀性,更將配置與執行分離,提高可維護性。它是一種函式轉換技術,將一個接受多個參數的函式 f(a, b, c),轉變為一系列只接受單一參數的函式鏈 f(a)(b)(c) 。其核心價值在於實現部分應用 (Partial Application),讓我們能預先固定部分參數,將一個泛用函式變成一座「可配置的計算工廠」,隨時生產出我們需要的、更特化的新函式 。
Hi, Monica
首先,先謝謝你的系列文章,真的獲益良多。
再次感謝你的文章~
stealing610 大大好~
感謝回饋,很開心能對你有幫助 ><
關於分層設計,我覺得當我們發現自己在寫很多重複的東西,就會想抽成函數共用了(人就是懶!)。這在某種程度上其實就已經在做抽象化或分層了,只是當下不一定會特別去想「變動頻率」或「層級設計」這些比較理論的東西。如果要把函數抽得更好,才會需要進一步去思考這些原則。另外我覺得這背後的核心可能較接近軟體設計思維,不一定是 FP 才會用到的東西。
以上是我目前的一些淺見,如果有不同的想法也很歡迎一起討論,真的很感謝你的留言!

