

FP 系列的最後,想進一步看看,在軟體設計的世界裡,到底哪些東西和 FP 相關,哪些技術和工具其實背後借鏡了 FP 的原理,藉此將 FP 的抽象概念與實際應用建立連結,避免只專注於 Functor 或 Monad 等理論細節,而忽略它們在實務中的價值。
在實際開發時,其實很多技術背後有借鏡 FP 的設計思想,以下簡單舉幾個例子。
Git 的核心其實是一個內容定址檔案系統 (content-addressable filesystem)(ref),其基礎是一個簡單的鍵值資料儲存庫。
當任何內容被加入 Git 倉儲時,Git 會對其內容加上一個標頭 (header) 進行雜湊運算,產生一個獨一無二的 SHA-1 雜湊值作為鍵,並將原始內容儲存起來。這個雜湊值取決於內容本身,這代表一旦物件被建立,其內容與其識別碼就永久綁定,無法被修改。
補充:雜湊運算
雜湊運算是一種數學函數,它可以接收任意長度的輸入資料(例如一個檔案的完整內容),並將其轉換為一個固定長度的、獨一無二的字串(稱為「雜湊值」)
這過程有幾個特性:
- 確定性:相同的輸入永遠會產生相同的雜湊值。
- 雪崩效應:輸入內容哪怕只有一個微小的變動(例如一個字母的改變),都會導致產生一個完全不同、無法預測的雜湊值。
- 單向性:從雜湊值幾乎不可能反推出原始的輸入內容。
在 Git 中,SHA-1 雜湊演算法被用來為每一個資料物件(檔案內容、目錄結構、提交紀錄)產生一個唯一識別碼。這能確保資料的完整性,如果檔案內容被修改,它的雜湊值就會改變,Git 會立刻知道這個檔案已經不是當初儲存的那個版本了。
Git 的核心資料物件—blobs(檔案內容)、trees(目錄結構)與 commits(時間點快照)—都是不可變的(ref)。一旦一個物件被寫入 .git/objects 目錄,它就永遠不會被改變 。當開發者執行看似修改歷史的指令,例如 git commit --amend 來修正最後一次的提交訊息,或是 git rebase 來重整提交順序時,Git 並沒有去修改舊有的 commit 物件。它會建立一個全新的 commit 物件(或是一整串新的 commit 物件),然後將分支的參考指標(例如 refs/heads/main)指向這個新的 commit 。舊的 commit 物件雖然不再被分支直接引用,但它們依然存在於物件資料庫中,這確保了歷史的完整性與可追溯性。
Git 的這種設計原則就體現了 FP 重視的不可變性,在 Git 的世界裡,改變並非原地修改 (mutation),而是基於舊有資料創建一個新版本的資料結構。也因此,Git 之所以如此可靠,正是其利用了 Functional Programming 的核心原則,因為它提供了一個完整且可驗證的歷史紀錄。
這種可驗證性來自於每個物件都由其內容(以及其父物件的雜湊值,對 commit 而言)的雜湊值來唯一識別。如果 commit 是可變的,那修改歷史中任何一個檔案的任何一個字元,都將導致其後所有的 commit 雜湊值失效,更重要的是,會破壞歷史的完整性。
透過使所有物件都不可變,Git 確保了歷史是一部只能追加、不容竄改的日誌。
若大家對更深入的 Git 運作有興趣,剛好這屆鐵人賽有 ralphhong5465 大大寫的 深入一點點認識 Git 系列,可以參考看看~
Event Sourcing (ES) 是一種架構模式,它將應用程式狀態的所有變更,都捕獲為一系列不可變的事件(Events),並將它們儲存在一個只能追加 (append-only) 的日誌中。這個事件儲存庫 (Event Store) 成為系統中唯一且權威的紀錄來源 (System of Record)。
在 Event Sourcing 模式下,應用程式的當前狀態並非系統儲存的主要重點。相反地,當前狀態是透過從頭到尾重播事件日誌中的所有事件所推導出來的結果。更簡單來說,當前狀態是事件流經過 fold 或 reduce 運算後的產物。
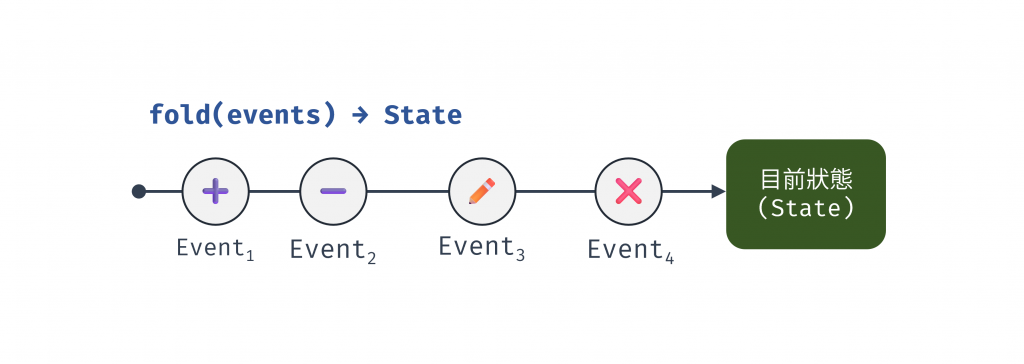
圖 1 Event Sourcing 模式下,狀態由事件歷史 fold 而成(資料來源: 自行繪製)
Event Sourcing 與 Functional Programming 的核心關聯在於,狀態不再是一個可變的實體,而是對一個不可變資料結構(事件日誌)進行計算的結果。這種設計原則帶來一些優點,例如:
更多 Event Sourcing 的說明可再參考 Event Sourcing。
進一步說,Event Sourcing 與 Git 本質上是相同函數式思想在不同領域的體現。
Git 透過 Stateₙ = apply(Stateₙ₋₁, Commitₙ) 推導出新狀態,Event Sourcing 則以 Stateₙ = evolve(Stateₙ₋₁, Eventₙ) 構成應用狀態。兩者都將真實的根源從可變的最終狀態,轉向那串不可變的歷史變化序列。
這顯示了他們共同的核心模式:狀態是歷史的左摺疊 (State as a Left Fold over History)。
無論是 Git 的版本演進還是 Event Sourcing 的事件流,它們皆以函數式方式重構狀態,並帶來了可追溯性與可驗證性這兩項價值。
React 的 function component 本身就是純函數,它接收 props 與 state 作為輸入,並回傳一段描述使用者介面 (UI) 的 JSX 作為輸出。這代表給定相同的輸入,一個純粹的 React 元件應該總是回傳相同的輸出,並且在渲染過程中不應產生任何可觀察的副作用。
為了讓 React 的渲染流程保持純粹,React 18 提供了嚴格模式(Strict Mode),在開發環境下,它會刻意將元件的渲染函數呼叫兩次,以利於偵測非預期的副作用。所有會改變外部世界狀態的行為,如網路請求或 DOM 操作,都被 React 歸類為副作用,並被延遲到事件處理函數 (event handlers) 或 useEffect hook 中執行,以保持渲染邏輯的純粹性。
在 React 中,狀態的更新是不可變的,這也遵循 FP 設計原則。開發者不能直接修改 state 物件,而必須透過狀態設定函數(如 useState 回傳的 setter)提供一個全新的 state 物件或陣列來觸發更新。這種對不可變性的強制要求,讓 React 能正確的偵測狀態變更並觸發重新渲染。
此外,在之前的函數組合篇章提過,React 的核心特性是組合(Composition)。複雜的 UI 是透過將許多小而簡單的元件組合在一起而構建的,這與 FP 的函數組合概念相同。
React 運用 FP 原則來簡化 UI 狀態管理的難題,在 React 的觀念裡,UI 是 state 的函數,即 UI = f(state)(ref:The Two Reacts)。透過單向資料流與不可變狀態更新,UI 的變化變得可預測且可追溯。開發者只需關注 state 的生成與傳遞,而不必追蹤複雜的 DOM 操作。
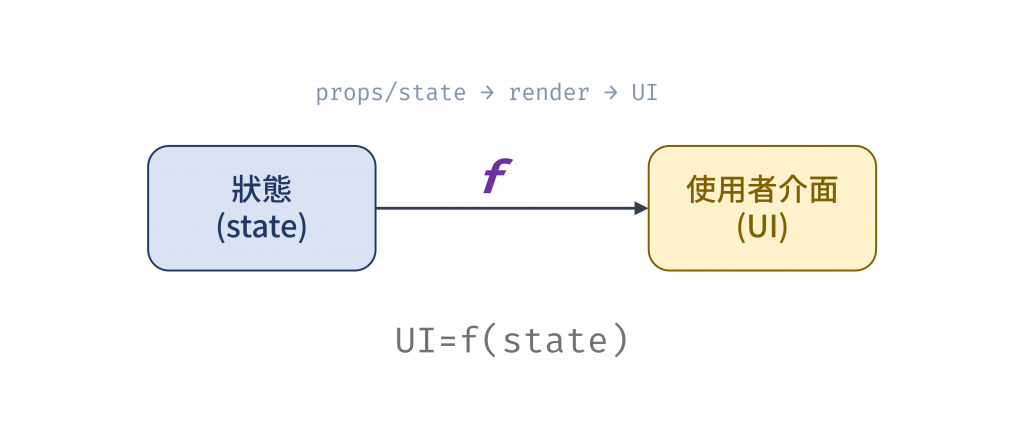
圖 2 React 元件是純函數,UI 由不可變狀態決定(資料來源: 自行繪製)
先簡單介紹下 MapReduce 是什麼,想像一下,如果我們要統計一座巨大圖書館裡所有書籍中,每一個單字各出現了幾次,一個人做可能要花上一輩子,而 MapReduce 就是為了解決這類「大到單一電腦無法處理」的問題而設計的程式設計模型與框架。它的核心思想是「分而治之」(Divide and Conquer)。運作上可分兩階段:
('the', 150)、('a', 200)。 ('the', 57000)。B 幫手則負責 "a" 的統計。這種方式可讓一個龐大的問題被分解成許多可以平行處理的小任務,使得處理巨量資料成為可能。MapReduce 框架會自動處理任務分發、資料傳輸、節點故障等複雜的底層細節,讓開發者可以專注於 Map 和 Reduce 這兩個核心的處理邏輯上。
MapReduce 程式設計模型的靈感,源於 Lisp 和其他函數式語言中常見的 map 和 reduce 函數。map 操作會將一個函數獨立地應用於一個集合中的每一個元素。正因為每一次操作都是獨立、無副作用的,它們可以以任何順序執行,且還可以同時執行,這正是平行化的關鍵。
MapReduce 框架正是利用了這一點,將海量的資料分散到成千上萬台機器上,讓每台機器對其分配到的資料子集執行 map 操作,後續再 reduce 歸納值,由此可知,MapReduce 利用純粹函數式的概念,解決了大規模計算的問題。
Scatter-Gather 模式是一種訊息路由模式,它將一個請求廣播給多個接收者,然後將它們的回應聚合成單一的回應訊息。此模式包含一個scatter(分散)階段,即將任務平行地分發出去;以及一個 gather(收集)階段,即收集並組合各個部分的結果。(ref)
這模式在需要同時查詢多個資料來源以降低延遲的場景中十分有用,例如機票比價網站向多家航空公司同時發出查詢請求。
這模式的兩個階段運作與 FP 操作十分相似,scatter 階段類似於 map,將一個操作應用於多個獨立的單元;gather 階段則類似於 reduce,將部分結果組合成最終結果。
MapReduce 主要用於批次資料處理,Scatter-Gather 則常見於即時請求,但兩者的核心模型一致:將大問題拆解為可獨立執行的子任務(map/scatter),再將結果整合(reduce/gather)。這種結構體現了函數式的核心精神:獨立、無副作用的運算可自由組合與平行化。
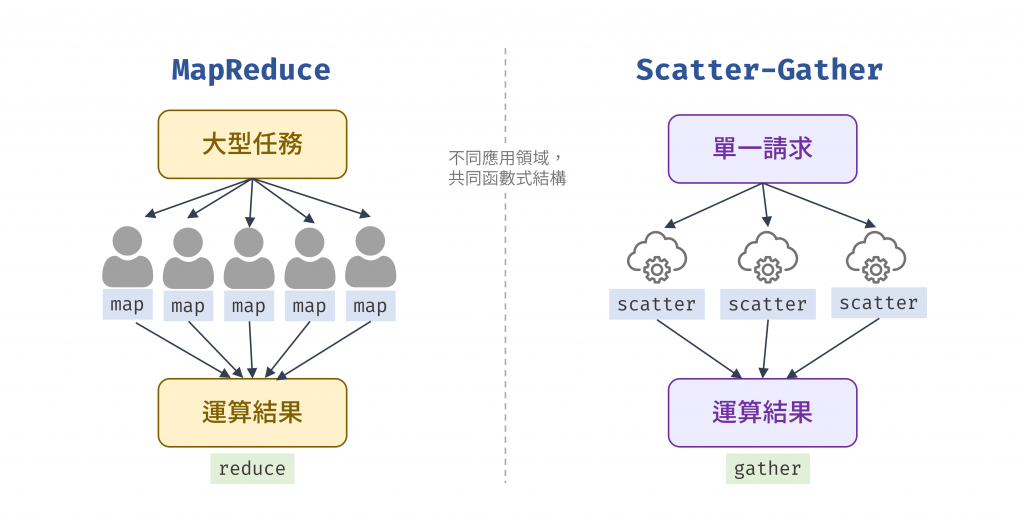
圖 3 不同應用領域,共同函數式結構(資料來源: 自行繪製)
了解這麼多 FP 的工具和設計原則,再次回來思考一下 FP 的本質:它到底解決了什麼問題?我們該如何在日常開發中運用它的力量,而不是陷入學術名詞裡?
FP 的重點不是消滅副作用,而是讓我們用一些工具來隔離與管理它們,之前文章有介紹過程式可分為 Action、Calculation 與 Data 三種類型,而 FP 的整體架構策略,就是盡可能地將 Actions 推向系統的最外層,進而打造一個由純粹的 Calculations 和不可變的 Data 組成的、穩定且可驗證的「函數式核心」(Functional Core)。圍繞在這個核心之外的,則是一個薄薄的「指令式外殼」(Imperative Shell),專門負責執行那些不可避免的 Actions。這也是延遲執行的體現,盡可能將要產生副作用的 Actions 推到外層,只在最需要的時候呼叫。(ref: A Look at the Functional Core and Imperative Shell Pattern)
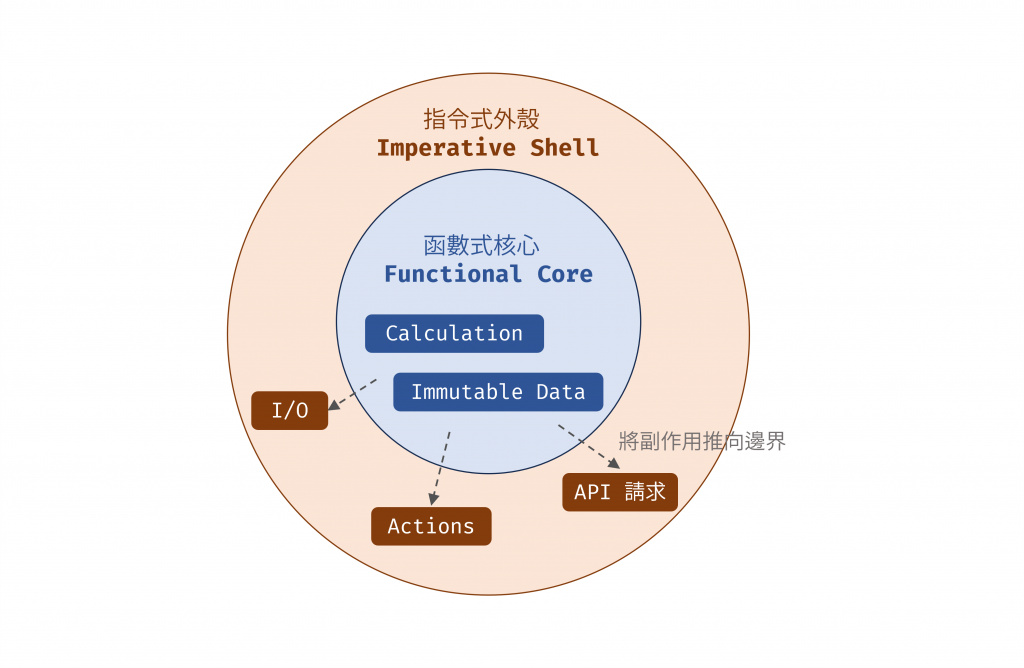
圖 4 Functional Core, Imperative Shell:將副作用推向邊界(資料來源: 自行繪製)
另一張圖我覺得畫得更清楚,也附上來。
圖 5 Functional Core, Imperative Shell 示意圖(資料來源: https://github.com/allousas/functional-core-imperative-shell?tab=readme-ov-file)
但這種劃分方式會遇到一些困難:如果 Calculations 是純粹的,它們要如何處理那些必須透過 Actions 才能取得的資料(例如,從 API 獲取的用戶資料)?如果 Calculation 內部直接呼叫 Action,那它就不再是純粹的了。
這就是 Functor、Applicative 與 Monad 等容器的價值。它們的價值在於作為一種連接器/膠水,讓我們能夠在不破壞純粹性的前提下,將純粹的 Calculation 附加到一個不純粹的 Action 之後執行。
更進一步來說,我們用容器包裹要執行的 Action,然後在容器內傳遞這些「打算要執行、但還沒實際執行的 Action」,以此避免副作用提前發生。
JavaScript 的 Promise 本身就可視為一個容器,它包裹的不是一個確切的值,而是一個「非同步」的 context。當我們發起一個網路請求時:
// 1. Action: 發起網路請求,這是不純粹的
const userPromise: Promise<Response> = fetch('/api/user/1');
userPromise
// 2. 串接另一個可能不純粹的轉換
.then(res => res.json())
// 3. 串接一個純粹的 Calculation
.then(user => user.name.toUpperCase())
.then(upperCaseName => {
// 4. Action: 將結果顯示在畫面上,這也是不純粹的
console.log(upperCaseName);
});
拆解一下上述流程:
fetch('/api/user/1') 是一個 Action。它與外部網路互動,其結果具有不確定性。它回傳的不是使用者資料本身,而是一個 Promise 物件,一個承諾未來某個時間點會給你結果的容器。user => user.name.toUpperCase() 是一個純粹的 Calculation。這個函數本身完全不知道什麼是網路、什麼是非同步。它只關心如何將一個使用者物件的名字轉換為大寫。.then() 方法就類似於 Monad 的操作 flatMap 或 chain,它的作用是打開 Promise 這個容器,取出裡面的值(當它可用時),將這個值傳遞給純粹 Calculation,然後將 Calculation 的結果再用一個新的 Promise 包裝起來,以便繼續串接下去。透過 Promise 和 .then,我們建立了一條清晰的處理管道,將不純粹的網路請求與純粹的資料轉換邏輯分開。Calculation 維持了純粹性,而副作用則被 Promise 這個容器有效地隔離與管理。
這個模式可以推廣到其他容器,例如 Array 的運作類似 Functor,Array.prototype.map 讓我們能將一個 Calculation(例如 n => n * 2)應用於陣列這個 context 中的每一個元素,而不需手動撰寫迴圈。
雖然在 JS 這種不是純函數式的程式語言中,去學習 Functor、Monad 這些概念會覺得有點奇怪,好像繞一圈在解決問題,但其實 Functor、Monad 這些概念的真正意義是一種可組合、用於包裹 context(如非同步、空值、列表)的模式,目的是盡量讓程式保持純粹,延遲副作用的行為產生。
而為了讓一切都可以被包裹在容器內,便於組合和傳遞,才衍伸發展出 map、chain 或是更進階的自然轉換等概念與工具,這些方法都只是為了要讓一切事物可以安全包裹在容器內,並且要能隨意組合串接、而不會導致管線斷裂出錯,為了達到這效果,因而借鏡了一些我們覺得很複雜的數學理論。
FP 的許多概念早在數十年前就已存在,會在近期更流行的原因是因為想處理軟體開發中複雜的狀態(state)與併發(concurrency)問題,隨著我們想進行的運算越來越複雜,處理器逐漸轉向多核心發展,平行運算成為常態,同時,網際網路的興起,讓分散式系統、微服務架構以及狀態極其複雜的單頁應用 (SPA) 成為主流,這讓我們面對到更多「共享的可變狀態」所引發的各種問題,如 Race Conditions 和 Deadlocks。
而 FP 剛好能為這些難題提供解答。
UI=f(state) 模型,正是借鏡了 FP 思想,用以解決 jQuery 開發中因手動操作 DOM 所導致的義大利麵式程式碼災難,簡化了複雜 UI 的狀態管理。不過 FP 也並非萬靈丹,認識其優缺點和適用場景也很重要。
在閒聊:Functional Programming 崛起,OOP 物件導向開發正在失寵?文章中,作者有提到,更好的軟體設計方式是結合 FP 與 OOP,例如,採用「大範圍 OOP,小範圍 FP」的混合策略,在高層次設計的時候使用物件導向設計,維持低耦合、易於維護擴充,細部邏輯實作時,則視需求採用函數技術滿足高並行需求。兩者都各有適合應用之處,也許結合會是最好的策略。
以下總結這篇文章幾個重點。
UI=f(state) 模型,以及 JavaScript 的 Promise 和 Array.map,都深受 FP 思想的啟發。總結來說,Functional Programming 不是要取代既有的軟體開發知識,而是為我們的工具箱增加一組新工具。讓我們能以更清晰、更可靠的方式,來面對未來日益複雜的軟體世界。

 iThome鐵人賽
iThome鐵人賽