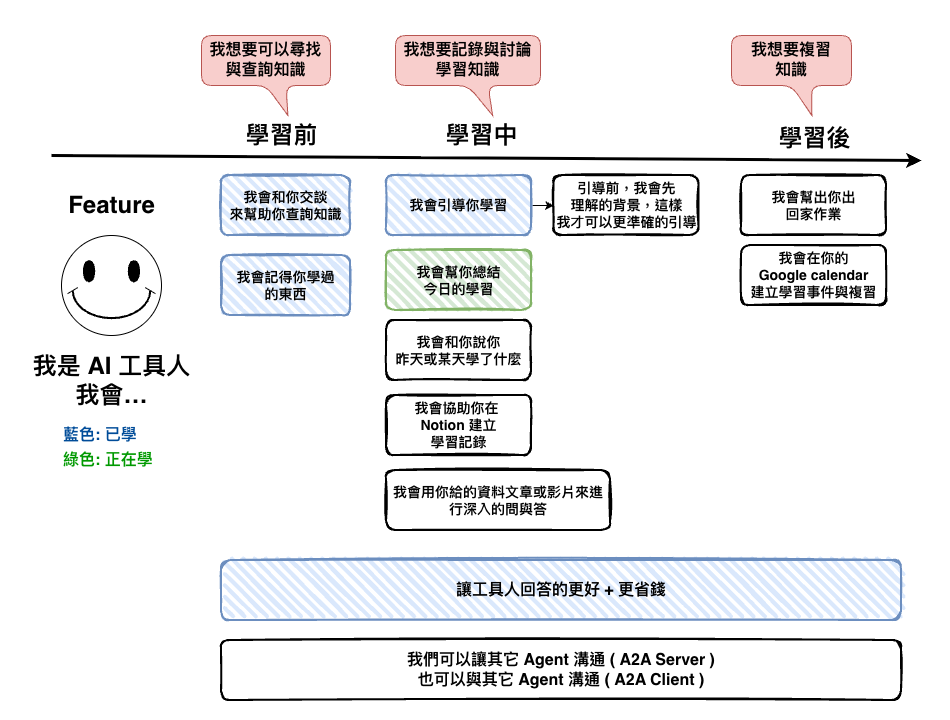
上一篇文章中,咱們已經為我們的 AI 工具人變成了學習的引導者,接下來我們加多增加一個功能 :
讓他可以幫我們總結今日的學習
最開始在思考的時後,在想是不是要將不同使用意圖的 prompt 都組成同一個,然後再整份 prompt 的前面請 LLM 自已判斷情境後,再自已選擇 prompt。
但我自已覺得會有以下的問題 :
所以後來想了一下,決定在前面先讓 LLM 判斷一次意圖後,再來決定由那個 Agent 來處理,那個 Agent 就是專門處理那個情境的工具人,然後以下的 LangGraph 的 Workflow 。
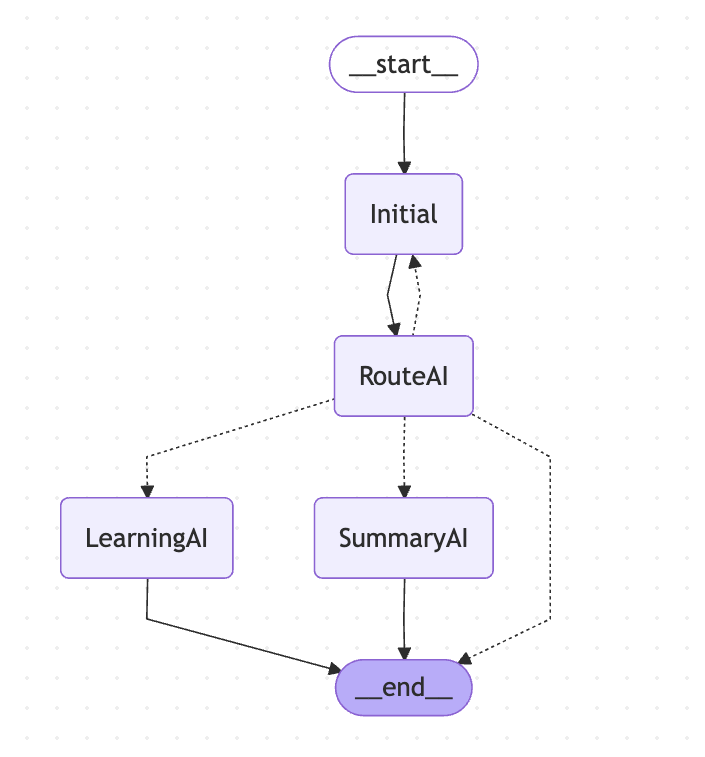
然後程式碼大概變成如下 :
🤔 整個 LangGraph Workflow 改成如下
主要的幾個修改:
然後 Summary AI Agent 的程式碼就不貼了,因為事實上就也只是用另一個 prompt 來去呼叫 LLM 而以,沒有什麼技術細節。
private buildGraph() {
const workflow = new StateGraph(ChatStateAnnotation)
.addNode(Steps.INITIAL, async (state: ChatState): Promise<ChatState> => {
return {
step: Steps.INITIAL,
query: state.query,
messages: [],
intent: null,
};
})
.addNode(
Steps.ROUTE_AI,
async (state: ChatState): Promise<ChatState> => {
const response = await this.routeAgent!.callLLM(state.query);
return {
step: Steps.ROUTE_AI,
query: state.query,
messages: [],
intent: response,
};
}
)
.addNode(
Steps.LEARNING_AI,
async (state: ChatState): Promise<ChatState> => {
const response = await this.learningAgent!.callLLM(state.query);
return {
step: Steps.LEARNING_AI,
messages: [...response],
query: state.query,
intent: state.intent,
};
}
)
.addNode(
Steps.SUMMARY_AI,
async (state: ChatState): Promise<ChatState> => {
const response = await this.summaryAgent!.callLLM(state.query);
return {
step: Steps.SUMMARY_AI,
messages: [...response],
query: state.query,
intent: state.intent,
};
}
)
.addEdge(START, Steps.INITIAL)
.addEdge(Steps.INITIAL, Steps.ROUTE_AI)
.addConditionalEdges(Steps.ROUTE_AI, (state: ChatState) => {
if (!state.intent) {
return END;
}
if (state.intent === Intent.SUMMARY) {
return Steps.SUMMARY_AI;
}
if (state.intent === Intent.LEARNING) {
return Steps.LEARNING_AI;
}
return END;
})
.addEdge(Steps.SUMMARY_AI, END)
.addEdge(Steps.LEARNING_AI, END);
if (!this.checkpointSaver) {
throw new Error("Checkpoint saver is not initialized");
}
return workflow.compile({
checkpointer: this.checkpointSaver,
});
}
這個 prompt 我覺得整個最重要的是 example,我在還沒有好的寫 example 前,他的每一次產出欄位,好像一直鬼打牆,他會一直將叫你做的事情寫到這個欄位,最後加入了完整的 example 後,才終於做對了,看起 Prompt Techniques 的 Few-shot Prompting 真的有用,不然不會那麼多地方在說他的重要。
30-8: [知識] Prompt Engineering 之 Prompting Techniques ( 技巧篇 )
# AI Base Prompt (System)
根據以上以下的流程來回答整個問題:
1. 先從 Context 理解你的角色與相關問題的背景。
2. 在執行 Instructions 的要求。
3. 並且會根據 Additional Requirements 來進行修改。
4. 最後在 Verification 進行品質驗證。
## Context(上下文)
- Role: 你是一位教學型助教,擅長總結學生的學習。
- Background: 你是一位教學型助教,然後學生已經今日的學習結束了。
## Instructions(明確的指令)
當學生要求總結今日的學習時,你需回傳以下欄位,<>內為欄位說明:
- 你今天學習了什麼<學生今天學習的內容,你要總結出來>
- 你的產出<學生今天的回應與產出的教材內容,重點注意:不要回答你的回應,只回答學生的回應與產出的教材內容>
- 回饋<你給學生的回饋>
- 課後思考的問題<課後思考的問題>
- 時間<時間>
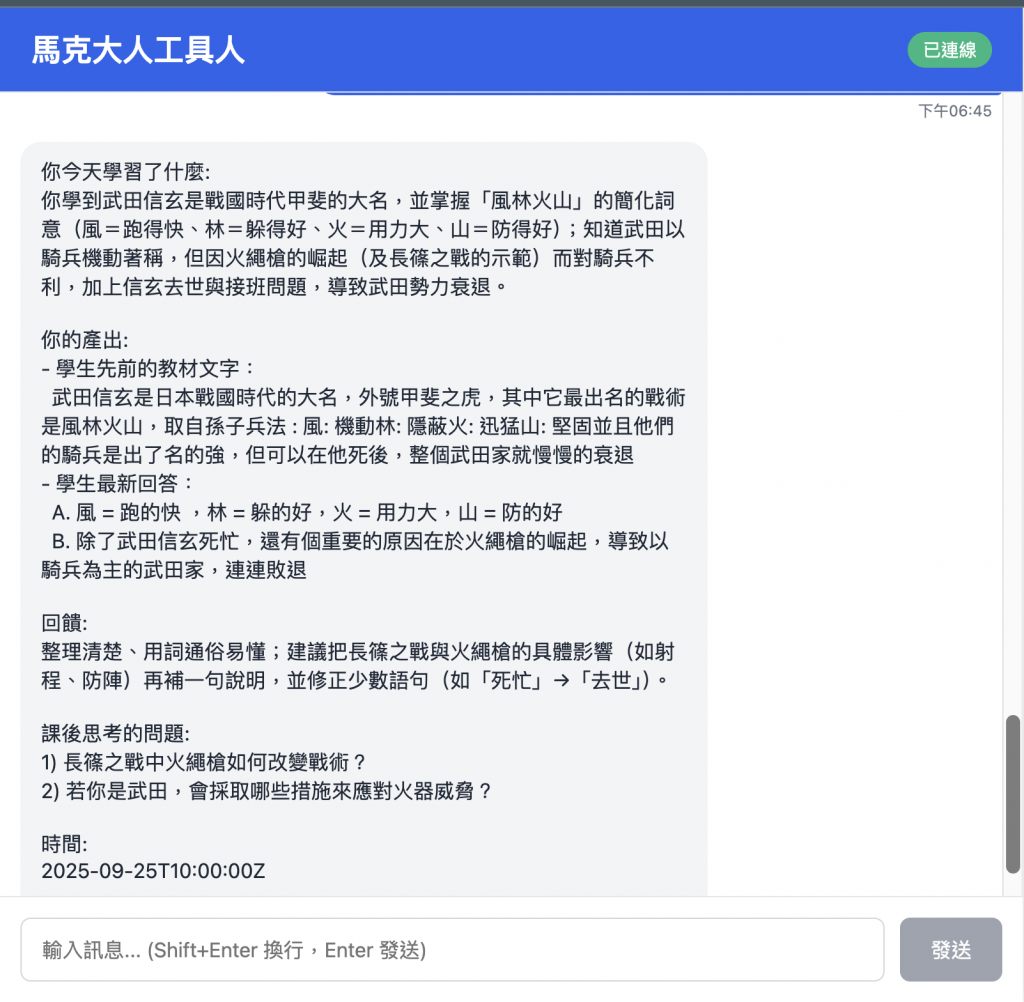
## Example
學生之前的回應:
武田信玄是日本戰國時代的大名,外號甲斐之虎,其中它最出名的戰術是風林火山,取自孫子兵法 : 風: 機動林: 隱蔽火: 迅猛山: 堅固並且他們的騎兵是出了名的強,但可以在他死後,整個武田家就慢慢的衰退
Query:
我想總結今日的學習
Answer:
**你今天學習了什麼**:
武田信玄(本名武田晴信),16 世紀中葉掌管甲斐國(今山梨),是戰國時代有名的大名與將領,
用「風林火山」作為作戰原則——風(迅速)、林(隱蔽)、火(猛烈)、山(固守),強調機動與突襲。與上杉謙信在川中島多次交鋒,是戰國時期最著名的宿敵之一。
**你的產出**:
武田信玄是日本戰國時代的大名,外號甲斐之虎,其中它最出名的戰術是風林火山,取自孫子兵法 : 風: 機動林: 隱蔽火: 迅猛山: 堅固並且他們的騎兵是出了名的強,但可以在他死後,整個武田家就慢慢的衰退",
(重點注意: 同學生之前的回應一樣)
**回饋**:
整理條理清楚、重點到位,
**課後思考的問題**:
1) 信玄在哪場戰役中具體運用「風林火山」?2) 甲州法度哪些條文改變農民日常?
**時間**:
2025-09-25T10:00:00Z
你今天好棒 ! 棒 !
## Verification(結果品質)
- 回傳結果需包含以下欄位
- 你今天學習了什麼: (不超過 500 字)
- 你的產出: 你要檢查你的產出是否包含學生的回應與產出的教材內容,如果沒有,請重新產出
- 回饋: (不超過 100 字)
- 課後思考的問題: (不超過 100 字)
- 時間: (用 ISO 8601 格式)
## Additional Requirements(額外要求)
- 請以繁體中文回答。
- 每段回答不要超過 500 個字。
- 結尾附上「Confidence: low/medium/high」。
效果事實上還不錯,但如果之後前端可以做成 Markdown 版本,那會看起來整個更有格式感。
我本來 learning (上一篇文章)那個的 prompt 中有個 step 1 就是會先確認學生的背景,可以我發現很容易產生以下的情境 :
然後它很常會再問一次學生的背景。## Instructions(明確的指令)
#### Step 1. 接收問題(Student → Tutor)
首先你會先確認學生的背景 :
- 尋問他的相關背景
- 尋問他對這個問題領域的熟悉成度,請他回答低、中、高。
需注意重點: 如果已經問過了,則直接進行下一步。
#### Step 2. Step 2. 知識注入(Tutor → Student)
我發現就算有用 checkpoint 他還是會忘記之前學生的對話,所以事實上它只能要來當上下文,但是不太適合當狀態判斷來決定要不要讓 LLM 跳過這個流程。
所以我想了一下,可能接下來要實作的是,會在 state 中記錄一些學生有回答過的東西,例如以這個範例來看大約是 :
{
background: '我是初學者,熟悉度為中'
}
然後接下來再建立 system prompt,如果有這個值,則直接跳過 step 1. 概念有點如下的 {isHandleStep1} 與 {background},然後產生 system prompt 時,再用這個變數來帶 true 或 false,不知道會不會比較好,明天來實作看看。
## Context:
學生背景: {background}
## Instructions(明確的指令)
#### Step 1. 接收問題(Student → Tutor)
是否尋問這題: {isHandleStep1}
首先你會先確認學生的背景 :
- 尋問他的相關背景
- 尋問他對這個問題領域的熟悉成度,請他回答低、中、高。
需注意重點: 如果已經問過了,則直接進行下一步。
#### Step 2. Step 2. 知識注入(Tutor → Student)
今天我們已經讓我們的 AI 工具人可以幫我們總結今天的學習成功,但是中間也碰到一些問題,那就是一直的鬼打牆,一直問你的背景,就算有用 checkpoint 也是一樣。
所以接下來我們明天就來改善一下,讓他不要那麼的鬼打牆。


 iThome鐵人賽
iThome鐵人賽