GPT (Generative Pre-trained Transformer) 系列是當前所有生成式 AI (如 ChatGPT) 的基石。它代表了與 BERT 不同的語言模型範式:從「理解」轉向「生成」。
GPT 模型系列的核心在於其架構和訓練方式。
這種單向性造就了 GPT 的自回歸特性。模型會一次只生成一個 token,並將這個新生成的 token 作為下一個時間步的輸入,循環往復,直到生成完整的序列。
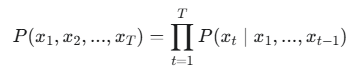
GPT 的生成過程就是一個連續的機率預測和採樣過程。如果模型總選擇機率最高的詞(Greedy Search),生成的文本會變得重複且缺乏創意,因此需要多種生成策略來平衡文本的品質與多樣性。
| 策略名稱 | 核心原理 | 目的與應用 |
|---|---|---|
| Greedy Search (貪婪) | 每一步只選擇機率最高的詞。 | 快速、簡單,但結果單調、缺乏創意。 |
| Beam Search (集束) | 每一步保留 k 條累計機率最高的序列。 | 追求全局最佳,結果通常最流暢、品質最高 (常用於機器翻譯)。 |
| Top-K 採樣 | 只從 k 個機率最高的詞中隨機抽取。 | 引入隨機性,保證多樣性,同時避免選到機率極低的詞。 |
| Top-P 採樣 | 動態選取累積機率 ≥ 的最小詞彙集後隨機抽取。 | 比 Top-K 更靈活,是目前 LLM 最常使用的策略之一 (Nucleus Sampling)。 |
| Temperature | 作為額外參數,控制機率分佈的平滑程度。 | 調整創作性:高溫度 > 1.0 -> 更隨機;低溫度 < 1.0 -> 更保守。 |
GPT 系列的演進史,就是語言模型參數規模和能力的擴張史,最終透過引入人類反饋,實現了實用性的突破。
| 模型版本 | 提出年份 | 參數規模 | 關鍵突破 |
|---|---|---|---|
| GPT | 2018 | 117M | 證明 Transformer Decoder + 自回歸預訓練的可行性。 |
| GPT-2 | 2019 | 1.5B | 證明大規模訓練能生成極為流暢、連貫的文章。 |
| GPT-3 | 2020 | 175B | 實現了驚人的少樣本學習 (Few-shot Learning) 能力。 |
| ChatGPT / GPT-4 | 2022-2023 | 數十億到數萬億 | 結合 人類回饋強化學習 (RLHF),使模型輸出更符合人類的偏好和指令。 |
總結來說:
GPT 的成功建立在:Transformer Decoder 結構、自回歸生成的訓練方式,以及各種採樣策略的配合。這種模式徹底釋放了生成式 AI 的潛能,帶來了我們今天看到的強大應用。


 iThome鐵人賽
iThome鐵人賽