要讓電腦處理語言,必須先將人類的文字轉換成電腦能處理的數值。這個過程涉及了兩個核心步驟:Tokenization (切割最小單元) 和 Embeddings (轉換成向量)。
Tokenization 是將原始文本(字串)切分成模型能處理的**最小單位(Token)**的過程。這是所有 NLP 任務的第一步。
傳統的分詞方法(如按詞分詞)會面臨 OOV (Out-Of-Vocabulary) 問題,即模型遇到訓練集中未出現過的新詞時會無法處理。子詞編碼 (Subword Tokenization) 則在「字符級別」和「單詞級別」之間取得平衡。
| 技術名稱 | 核心原理 | 優點與應用 |
|---|---|---|
| BPE (Byte Pair Encoding) | 反覆合併最常出現的相鄰字元對,直到達到預設的詞彙表大小。 | 核心優勢是能解決 OOV 問題:將罕見詞拆解成多個常見子詞。廣泛應用於 GPT 系列、BERT。 |
| SentencePiece | 獨立於特定語言的 Tokenizer。它將空格視為一個普通字符,直接在字元層級進行分詞。 | 不依賴人工斷詞,特別適合處理多國語言和字元複雜的語言。廣泛應用於 Google 的模型 (如 T5)。 |
Tokenization 之後,下一個關鍵是將離散的 Token 轉換成電腦能處理的數值表示,即 Embeddings(嵌入向量)。
向量的幾何關係反映了語義的相似度。餘弦相似度是 LLM 中最常用來量測兩個向量語義相似性的方法。
餘弦相似度衡量的是兩個向量在空間中的方向是否一致,而不受向量長度的影響。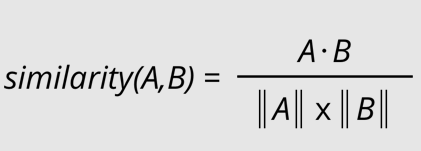
其中:
餘弦相似度的值域在 [-1, 1] 之間:


 iThome鐵人賽
iThome鐵人賽