在前幾篇的內容中,介紹了 Bag-of-Words 與 TF-IDF,這些把文本轉成向量的方法,但因為他們是用「詞頻統計」的方式,所以屬於 稀疏向量(sparse vector)。
後來 稠密向量(dense vector) 的概念就出現啦~這個做法指的是把文本壓縮到相對「低維度」的空間中,而且每個維度都真正承載了語意上的資訊。這樣的表示方式,就是我們所說的 「語意向量」(semantic embeddings)。
在 2013 年 Google 的 Mikolov 團隊提出了 Word2Vec,這是第一個真正將「語意向量」推向主流的模型架構。雖然在此之前,也有像 LSA、HAL 這些方法也嘗試過用數字來表示語意,但 Word2Vec 以更高效、更直觀的方式實現了這個想法,並成功捕捉到詞語之間的語意結構。
所以今天,我們就要來介紹 Word2Vec,並帶大家做一個簡單的小實作~
Word2Vec 的核心概念很簡單,就是透過 「看詞的上下文,學到詞的語意」
舉例來說,我們有兩個句子:
從例子中,我們可以看到「蘋果」和「香蕉」會出現在類似的上下文中,像是前面可能都可以加「吃」或「買」,所以我們就能推測它們的語意應該是相近的。
Word2Vec 就是透過大量文本,梳理上下文來去學習出這樣的語意關係,並把每個詞表示成一個稠密向量,或是我們可以說 word embedding。
Word2Vec 有兩種主要的訓練方式:
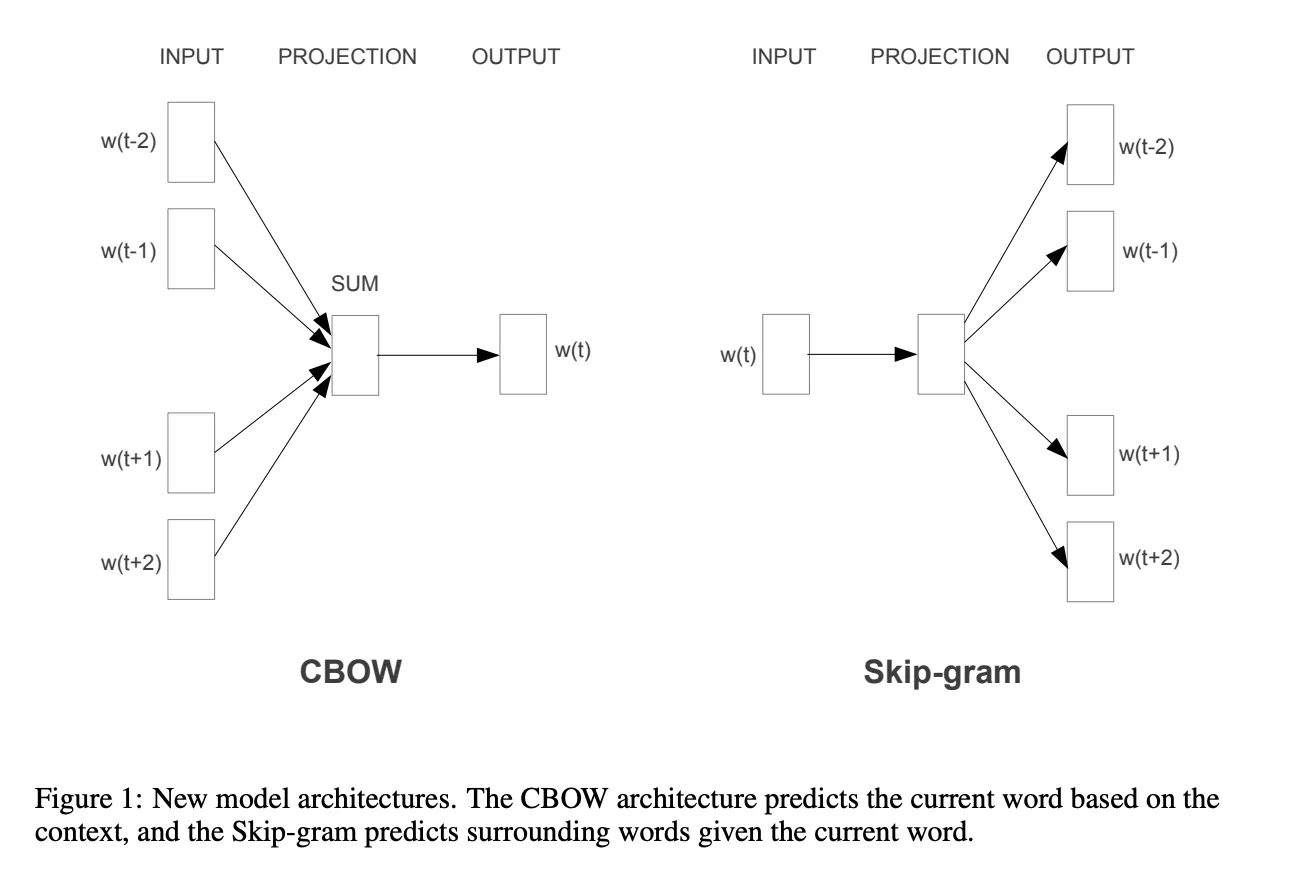
圖片來源:https://arxiv.org/pdf/1301.3781.pdf
細節的模型架構就先不多說明(我們之後才會講到神經網路模型),先進入程式實作吧~
這邊我們先用少少幾句中文文本作為範例,來看看要如何用 Word2Vec 將中文文本轉成 embedding,並且最後畫出他們在 2D 空間的樣子。
gensim(generate similarity) 是專門用在將文本向量化的模組,更多資訊可以參考 Gensim 官方文件學習筆記
import jieba
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
import plotly.express as px
# 測試訓練句子
docs = [
"我喜歡吃蘋果",
"我喜歡吃香蕉",
"蘋果和香蕉都是水果",
"我不喜歡吃芭樂",
"我要買水果",
"我要買蘋果",
"我要買香蕉",
"我不買芭樂"
]
# 斷詞
tokenized_sents = [jieba.lcut(doc) for doc in docs]
print("斷詞結果:")
for doc, tokens in zip(docs, tokenized_sents):
print(f"{doc} → {tokens}")
# === Output ===
斷詞結果:
我喜歡吃蘋果 → ['我', '喜歡', '吃', '蘋果']
我喜歡吃香蕉 → ['我', '喜歡', '吃', '香蕉']
蘋果和香蕉都是水果 → ['蘋果', '和', '香蕉', '都', '是', '水果']
我不喜歡吃芭樂 → ['我', '不', '喜歡', '吃', '芭樂']
我要買水果 → ['我要', '買', '水果']
我要買蘋果 → ['我要', '買', '蘋果']
我要買香蕉 → ['我要', '買', '香蕉']
我不買芭樂 → ['我', '不', '買', '芭樂']
Word2Vec() 參數:
model = Word2Vec(tokenized_sents, vector_size=50, window=2, min_count=2, sg=0)
# 詞彙表
words = list(model.wv.key_to_index)
print(f"詞彙表:{words}")
# 詞向量
vectors = [model.wv[word] for word in words]
print(f"「{words[0]}」的向量:\n{vectors[0]}")
# === Output ===
詞彙表:['買', '我', '我要', '香蕉', '蘋果', '吃', '喜歡', '芭樂', '不', '水果']
「買」的向量:
[-1.07358338e-03 4.76127345e-04 1.02034053e-02 1.80208236e-02
-1.86018180e-02 -1.42308073e-02 1.29166720e-02 1.79546662e-02
-1.00395251e-02 -7.52585474e-03 1.47595024e-02 -3.07206251e-03
-9.06693377e-03 1.31137725e-02 -9.71385464e-03 -3.63675831e-03
5.76050673e-03 1.99499261e-03 -1.65814739e-02 -1.89066064e-02
1.46204270e-02 1.01353303e-02 1.35167204e-02 1.51790457e-03
1.27119245e-02 -6.81579020e-03 -1.88859983e-03 1.15456525e-02
-1.50521975e-02 -7.86695257e-03 -1.50185302e-02 -1.86774926e-03
1.90725997e-02 -1.46450233e-02 -4.67420043e-03 -3.87720601e-03
1.61593333e-02 -1.18580684e-02 9.44020430e-05 -9.50895250e-03
-1.92138422e-02 1.00156358e-02 -1.75258722e-02 -8.77958722e-03
-6.77432981e-05 -5.86947077e-04 -1.53204454e-02 1.92299057e-02
9.96202230e-03 1.84676088e-02]
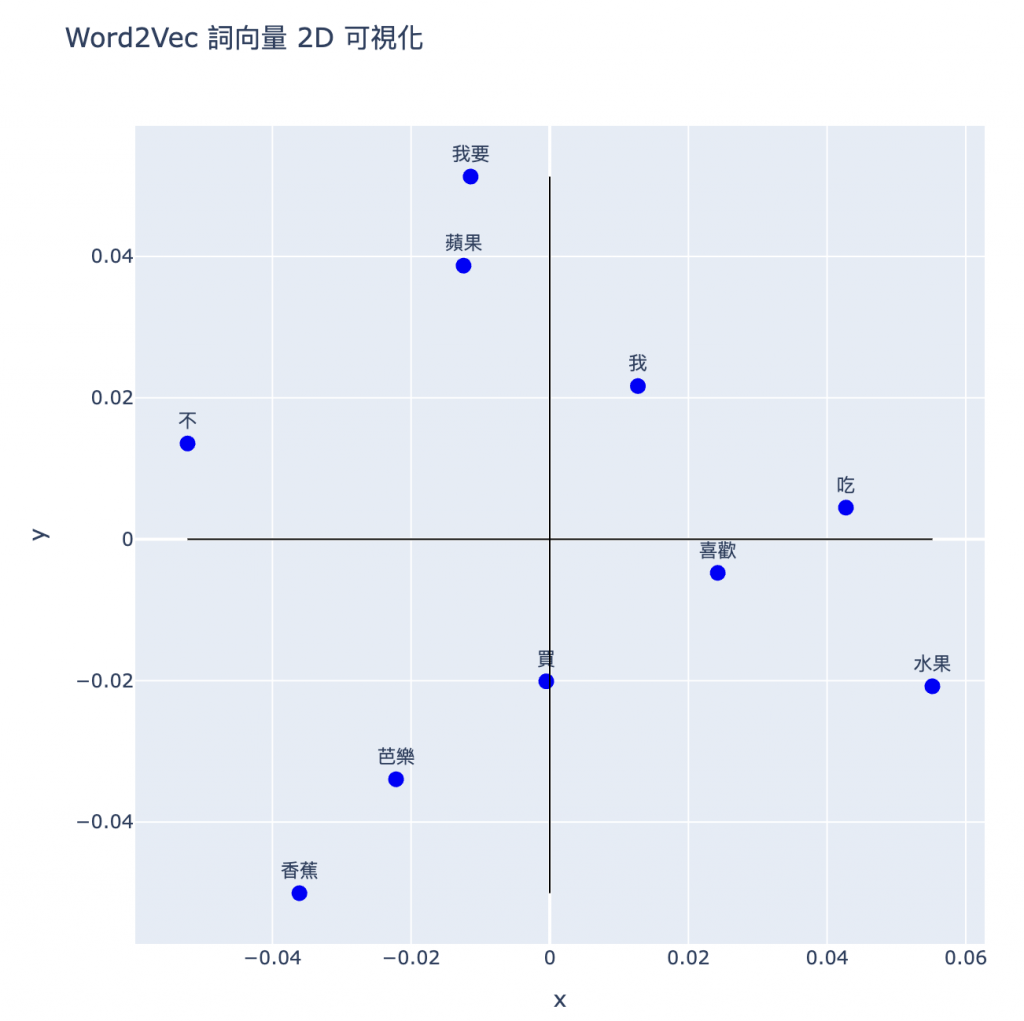
# PCA 降到 2 維
pca = PCA(n_components=2)
vectors_2d = pca.fit_transform(vectors)
# 整理成字典方便做圖
data = {
"x": vectors_2d[:, 0],
"y": vectors_2d[:, 1],
"word": words
}
plotly做出動態圖# 互動散點圖
fig = px.scatter(data, x="x", y="y", text="word",
title="Word2Vec 詞向量 2D 可視化",
width=700, height=700)
# 調整文字顯示
fig.update_traces(textposition='top center', marker=dict(size=10, color='blue'))
# 加上四象限的參考線
fig.add_shape(type="line", x0=min(data["x"]), y0=0, x1=max(data["x"]), y1=0,
line=dict(color="black", width=1))
fig.add_shape(type="line", x0=0, y0=min(data["y"]), x1=0, y1=max(data["y"]),
line=dict(color="black", width=1))
fig.show()
一句話總結 Word2Vec,就是使用 淺層神經網路,透過考量 「詞」跟「上下文」 的關係,去學習詞的語意!
今天我們用程式自己訓練了一個 Word2Vec 的模型,把文字轉成了 embedding,然後也在 2D 空間中看到詞語之間的語意距離。(雖然訓練資料量太小,基本上不太準XD)目前繁體中文有一些預訓練的詞向量資源也提供給大家:
不過大家可以想想看,Word2Vec 訓練出來的詞向量,會有什麼限制嗎?
提示💡:「我每天騎機車上學」跟「你這人很機車欸」,這兩個句子中的「機車」意思相同嗎?
明天我們要介紹 語境中的向量(Contextual Embedding),就會探討這個問題哦!

