昨天我們介紹 Word2Vec,學會了怎麼把文字變成 語意向量。但這只是用數字來表示語意的第一步!語意可是比你想得更複雜許多~~還記得我們在本系列的第二篇文 文字探勘(Text Mining)的挑戰 中提到,語言有 「歧義性」(ambiguity) 嗎?
簡單來說就是一段文字可以有不同意思。那麼如果一個詞在不同語境下意義不同,Word2Vec 能抓到真正的語意嗎?答案是:辦不到 ❌
原因是因為 Word2Vec 所產生的是 「靜態向量」(static embedding),無論這個詞出現在什麼句子裡,它的向量都是一樣的。
但是今天要介紹的 Contextual Embedding 是 「動態向量」(dynamic embedding),它可以隨上下文改變。這種方法讓電腦能夠捕捉語境的差異,更智慧地理解語意,也讓文字向量真正活起來!
今天的內容我們先不談太深奧的模型架構(之後的文章才會提到),先來輕鬆的了解這個概念,還有用簡單的程式實作來看看同一個詞在不同句子裡長得不一樣的模樣吧~
首先,我們來看兩個句子:
身為人類,我們應該可以輕鬆地靠上下文判斷「蘋果」在這兩句話的差異吧~
Contextual Embedding 就是要解決「多義詞」的問題。它會根據句子的上下文,為同一個詞生成不同的向量。
目前常用的做法,是利用大型預訓練模型(例如 BERT)來生成這種向量。這些模型會觀察整句話,去注意哪些詞是比較重要的,然後再動態調整每個詞的向量。所以整個生成 contextual embedding 的過程大概會經歷下面幾個步驟:
例如:「蘋果」在「我買了蘋果」這句話中可能更重視「買了」這個詞;在「蘋果推出新產品」這句話中可能更重視「產品」這個詞。
然後模型會透過多層的計算,讓向量能捕捉更精準、深層的語意關係。
實作的部分,我們使用中文的 BERT 模型bert-base-chinese,並且選了幾個包含「蘋果」的句子。但是「蘋果」在這幾個句子的意思都不同,我們就透過模型來轉成 contextual embedding,然後在可視化空間中看他們的分布跟距離~
from transformers import AutoTokenizer, AutoModel
import torch
from sklearn.decomposition import PCA
import plotly.express as px
# 選用 BERT 中文模型
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModel.from_pretrained("bert-base-chinese")
# 測試句子
docs = [
"我去買蘋果", # 水果
"我喜歡吃蘋果", # 水果
"蘋果推出了新產品", # 公司
"蘋果的手機很好用", # 公司
"我買了蘋果日報" # 報紙
]
BERT 中文斷詞通常會是一個字一個 token,如果 target_word 多個字,要取 embedding 有幾種常見方法:
在這裡我們使用 mean pooling
target_word = "蘋果"
vectors = [] # 存 target_word 的向量
contexts = [] # 存含有 target_word 句子
for sent in docs:
# 斷詞/編碼
inputs = tokenizer(sent, return_tensors="pt")
outputs = model(**inputs)
embeddings = outputs.last_hidden_state # shape: (batch_size, seq_len, hidden_size)
# 查看斷詞結果
tokens = tokenizer.tokenize(sent)
print(sent, "→", tokens)
# 找出 target_word 的位置範圍
target_tokens = tokenizer.tokenize(target_word)
target_len = len(target_tokens)
for idx in range(len(tokens) - target_len + 1):
if tokens[idx: idx + target_len] == target_tokens:
# 把 subword 的向量取平均
word_vector = embeddings[0, idx: idx + target_len, :].mean(dim=0).detach().numpy()
vectors.append(word_vector)
contexts.append(sent)
break
# 查看結果
print(f"\ntarget word 向量維度:{len(vectors[0])}")
# === Output ===
我去買蘋果 → ['我', '去', '買', '蘋', '果']
我喜歡吃蘋果 → ['我', '喜', '歡', '吃', '蘋', '果']
蘋果推出了新產品 → ['蘋', '果', '推', '出', '了', '新', '產', '品']
蘋果的手機很好用 → ['蘋', '果', '的', '手', '機', '很', '好', '用']
我買了蘋果日報 → ['我', '買', '了', '蘋', '果', '日', '報']
target word 向量維度:768
Plotly 做圖# 降維
pca = PCA(n_components=2)
vectors_2d = pca.fit_transform(vectors)
# 建立 DataFrame
import pandas as pd
df = pd.DataFrame({
"x": vectors_2d[:,0],
"y": vectors_2d[:,1],
"sentence": contexts
})
print(df)
# 用 Plotly 畫散點圖
fig = px.scatter(df, x="x", y="y", text="sentence", title=f"Contextual Embedding of '{target_word}'")
fig.update_traces(textposition='top center')
fig.show()
# === Output ===
x y sentence
0 5.907347 -4.127521 我去買蘋果
1 7.210994 -5.499431 我喜歡吃蘋果
2 -11.100585 0.684716 蘋果推出了新產品
3 -10.296168 0.128546 蘋果的手機很好用
4 8.278411 8.813690 我買了蘋果日報
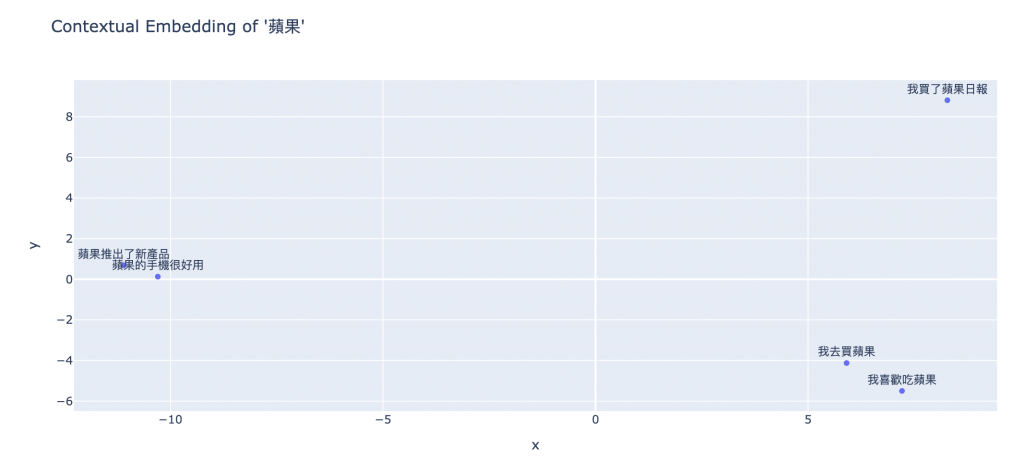
我們可以看到「蘋果」在不同的語境底下,會有不同的 embedding,並且可以看到意思相近的,向量真的有比較靠近!很神奇吧~~
今天介紹的 Contextual Embedding 看到了一個很重要的突破,是讓電腦可以更貼近人類理解語言的方式,捕捉到語意會隨著上下文而變化的特性。那這系列的 主題三:特徵與表示 就在這裡畫下句點,明天開始會進入 主題四:模型與方法 啦~~
你可能會好奇,這些 embedding 背後到底是怎麼算出來的?有了這些文字特徵,接下來要如何做運算?
其實這就涉及到各種不同的模型方法,從比較傳統的 機器學習(Machine Learning),再到 神經網路架構(Neural Network),一路到 深度學習(Deep Learning),再到現在更強大的大型語言模型(Large Language Model)。接下來的幾天,我們就會慢慢介紹這些演算法,一步步揭開這些模型背後的祕密!


