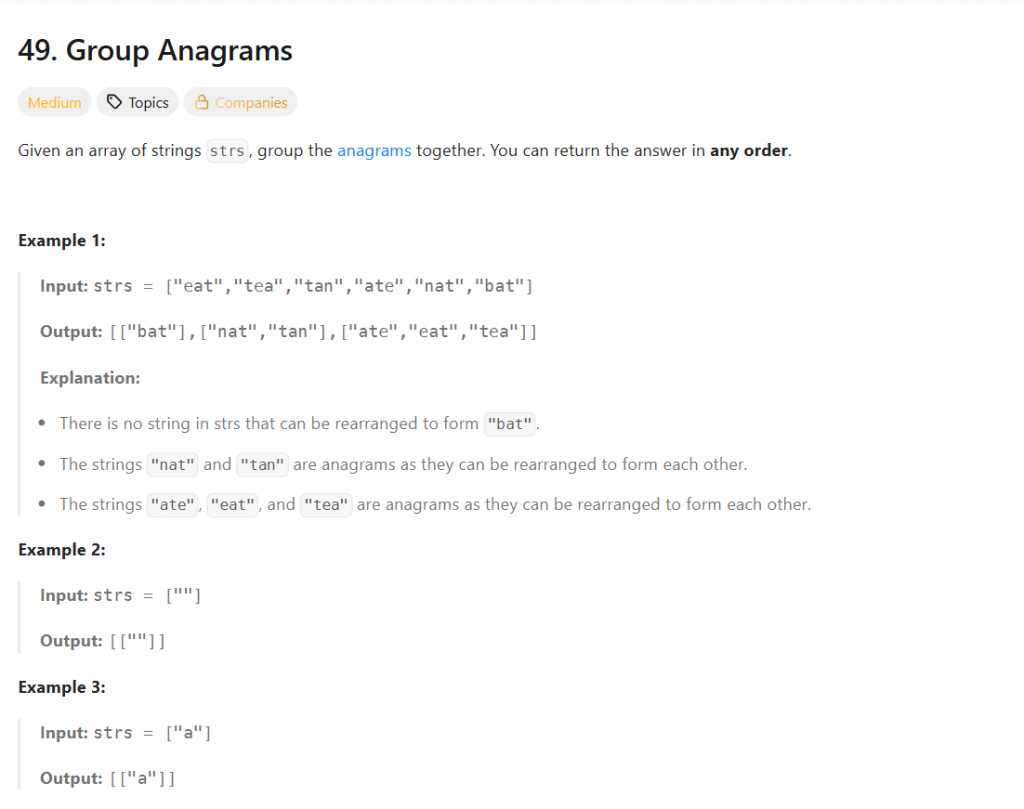
題目說他會給我一個字串的陣列,然後我要把是anagram的分類在一起,anagram就是他們的組成字母一樣,但順序不同。然後回傳一個分類好的字串陣列給他。
Example:
Input: strs = ["eat","tea","tan","ate","nat","bat"]
Output: [["bat"],["nat","tan"],["ate","eat","tea"]]
我要先把一樣是anagram的他們分類在同一個地方,但我不太知道要怎麼做,所以決定這一題問一下Gemini。
他說有一個很好的辦法就是把每個字串重新排序,因為異位詞的字母組成是完全相同的所已把他們排序後的結果也一定一樣。就像 eat、ate、tea都可以排成aet>
所以這樣就可以創一個hash map來儲存分組結果,hash map的key就是排序後的字串,再用一個value儲存對應的原始字串。然後遍歷他給的字串陣列,把每個字串s轉成字元陣列然後排序,排好後的字元再轉回去當作key。將原始字串s加入到key對應的值列表中。如果key還不存在,就創一個新的列表,遍歷結束後,hash map中的values就是我們需要的分組結果。
然後他還更訴我了一個東西:增強型for迴圈,可以省略變數i的宣告和條件判斷與增量,就是
for (int i = 0; i < strs.length; i++) {
String s = strs[i];
}
可以省略成
for (String s : strs) {
}

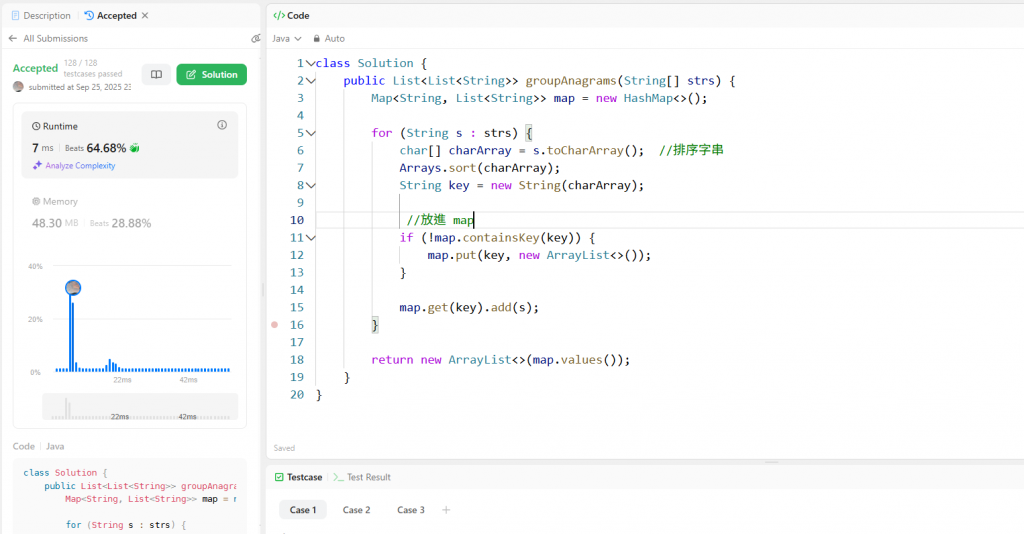
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<>();
for (String s : strs) {
char[] charArray = s.toCharArray(); //排序字串
Arrays.sort(charArray);
String key = new String(charArray);
//放進 map
if (!map.containsKey(key)) {
map.put(key, new ArrayList<>());
}
map.get(key).add(s);
}
return new ArrayList<>(map.values());
}
}
執行成功