搜尋的功能在一個部落格中,通常是一個加分項,因為有了標籤、分類的架構後,其實要找到有興趣的文章已經不會太困難了,況且個人部落格的文章數量通常不會太多,超過百篇我都覺得已經沒那麼簡單了。
但是在當成工具書「查閱」的情境下,我認為搜尋還是有蠻大的幫助,像是臨時想找找某個 Library、工具、網站、專有名詞等等,不一定會放在標題或是為此新增標籤,搜尋功能就派得上用場了。
那麼這一講我們就來聊聊搜尋的基本原理,以及在我們使用 SSG 產出靜態網頁的限制下,純前端的搜尋是怎麼做到的,又有什麼限制?
首先,來看看在部落格當中有什麼情境會使用到搜尋功能。
我們可能正在學習網路通訊的相關知識,想要找找部落格有哪些文章討論到「協定」的內容,在搜尋欄中輸入「協定」這個關鍵字,通常就會列出所有包含這個關鍵字的文章標題,並 Highligh 出在什麼句子中出現。

*關鍵字搜尋示意圖
找到有出現這個關鍵字的文章,就是搜尋的最基本功能。
要怎麼做出這個功能呢?我們先不論到底是有資料庫的後端搜尋,還是靜態的前端搜尋,先由最簡單的方式開始試著把他實作出來。
我想最直接的方式,就是把輸入的關鍵字和所有文章中的所有內容一一比對。
就以上面的兩個文章為例,我們將關鍵字「協定」和所有文章標題、內文來比較,從前面兩個字「PP」和「協定」比較,不符合的話就往下找,直到恰好比對成功,我們便把內文配對成功中的位置 index 記錄下。

*內文字串比對
然而,這肯定是一個很不經濟的做法,因為每一次搜尋,都需要把所有文章拿出來,每個字都看過一次,假設整個部落格的文章字數有 100 萬個字,就要和關鍵字比對 100 萬次。
但可能有人會說,100 萬次比對可能也還好吧?但這僅僅是一個關鍵字就要比對的次數,如果我們擴充搜尋功能,加上多個關鍵字、甚至 AND / OR 的邏輯呢?複雜度就會成倍數的增長。
不全文字串比對的話,有沒有什麼更好的方法來做關鍵字搜尋呢?
這就可以提到「索引」了,由於使用者會透過關鍵字來搜尋內文有出現的地方,那麼我們是否將所有關鍵字做成一個 Hash Table 就好了:Key 為關鍵字、出現的所有位置為 Value。
如此一來,只要輸入的關鍵字剛好在這個 Hash Table 當中,我們立刻就可以找到所有位置。
以一篇英文的文章為例子,我們透過空白鍵等符號作為分割點,把每個英文單字做成一個關鍵字,也就是 Hash Table 的 Key,就可以產出下圖右方的一張表格,記錄每個單字有出現的 Index。
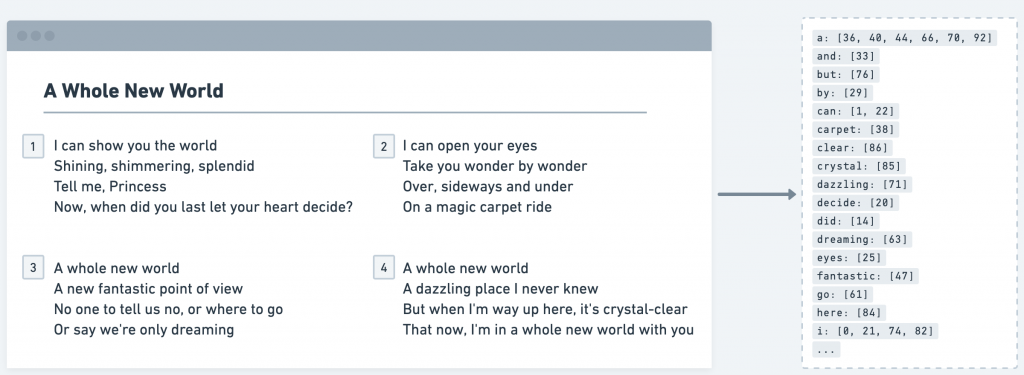
*關鍵字索引範例
例如 i 出現在 Index 為 [0, 21, 74, 82] 的位置,而 can 出現在 [1, 22] 的位置。
使用 Index 的做法優點就是效率比全文比對的方式高了一大截,因為 Hash Table 搜尋 Key 的複雜度平均下來只有 O(1) 而已。也就是說在預處理的階段把這張表建立完成後,搜尋的複雜度就是常數等級了。
再來擴充到關鍵字能定位到某篇文章的做法,我們一樣可以在預處理的階段將每個文章的關鍵字取出,然後在 Index 的 Array 中加上文章的路徑即可,例如
const keywordIndexMap = {
a: [
{ path: '/a-whole-new-world', index: [36, 40, 44, 66, 70, 92] },
{ path: '/you-ve-got-a-friend-in-me', index: [2, 8] },
],
and: [],
// ...
}
產出這張關鍵字和位置的對照表,搜尋功能就完成了大半了,然而這張表有這麼容易做出來嗎?
在英文的文章中,我們可以透過空白鍵、換行或標點等符號當成拆分字詞的「分割點」,分出來的就是我們表格中的關鍵字。然而名詞大多有複數、有型態,例如 car 和 cars、play 和 playing 等等,都需要特別處理。
中文就更加麻煩一點了,字詞之間並沒有明顯的分野,一句簡單的「下雨天留客天留我不留」到底要怎麼拆?要拆成「下雨、天、留客、天、」還是「下雨天、留客天、」,有什麼邏輯可以參照?
為了處理這些問題,就可以提到「斷詞」這個重要概念了,我們下一講接著聊。

