
在上一篇文章中,我們介紹了「函數組合(Function Composition)」,透過把多個小函數拼接起來,我們能寫出更具模組化與表達力的程式。而今天要談的是 Point-Free(無參數風格),這是一個與函數組合、柯里化等技術密切相關的程式風格。
Point-Free 這個名字我第一次看到時也是很困惑:到底「free of point」是什麼意思?
簡單來說,它指的是在定義函數時,不再顯式地提及資料(也就是「點」),而是專注於描述資料應該經過哪些轉換。
讓我們從應用場景出發,看看程式碼是如何一步步演進,最終走向 Point-Free 的。
假設現在的需求是:「給定一個使用者物件的列表,取得所有管理員(admin)的電子郵件地址。」
若使用傳統的命令式(Imperative)風格,程式碼可能如下:
// 命令式風格
function getAdminEmails(users) {
const emails =;
for (let i = 0; i < users.length; i++) {
if (users[i].role === 'admin') {
emails.push(users[i].email);
}
}
return emails;
}
這段程式碼非常明確地告訴電腦「如何做」:建立一個空陣列、從索引 0 迴圈到 users.length、執行一個 if 條件判斷、將符合條件的元素推入陣列,最後回傳這個陣列。
問題在於,它讓閱讀者必須在腦中完整執行一次這個過程,必須追蹤 emails 陣列的狀態、i 的值以及整個控制流程。其核心的商業邏輯——「篩選管理員」和「取得信箱」——被埋藏在大量的實作細節之下。這些細節就是我們想要消除的「認知噪音」。
我們可用 JavaScript 內建的陣列方法來重構程式:
// 宣告式風格
function getAdminEmails(users) {
return users
.filter(user => user.role === 'admin')
.map(user => user.email);
}
我們不再描述「如何做」,而是描述「做什麼」。程式碼讀起來就像一組指令:「篩選使用者,然後 map 出結果。」然而,這裡仍然存在一些「噪音」:參數 user。它被重複提及,而箭頭函式 user =>... 基本上是一次性的連接用程式碼。雖然清晰許多,但我們仍然需為流經處理鏈的資料命名並追蹤它。
讓我們看看理想化的 Point-Free 版本,這也是我們追求的目標:
// 宣告式 (Point-Free) 風格
const getAdminEmails = compose(
map(getEmail),
filter(isAdmin)
);
這段程式碼現在讀起來像一個「定義」:「取得管理員信箱」這個操作,是由「map 取得信箱」和「篩選管理員」這兩個操作組合而成。在整個定義中,資料本身(users)未被提及。
這分離了「做什麼」(商業邏輯管線)與「對誰做」(最終會流經管線的資料)。這種關注點分離正是 Point-Free 的核心概念。
從命令式到宣告式,再到 Point-Free,這不僅是語法上的改變,更是抽象層次上的根本轉變。
命令式程式碼關注的是比較低層次的視角(以分層設計的觀點來看,屬於低層級):迴圈、索引、記憶體分配。
宣告式(Pointful)程式碼更接近開發者的視角,但仍需明確管理資料的流動(user 進入 filter,其結果再進入 map)。而 Point-Free 則將其提升到了更高層次的視角。它純粹以其他更小的流程(getEmail, isAdmin)來描述一個商業流程(getAdminEmails)。
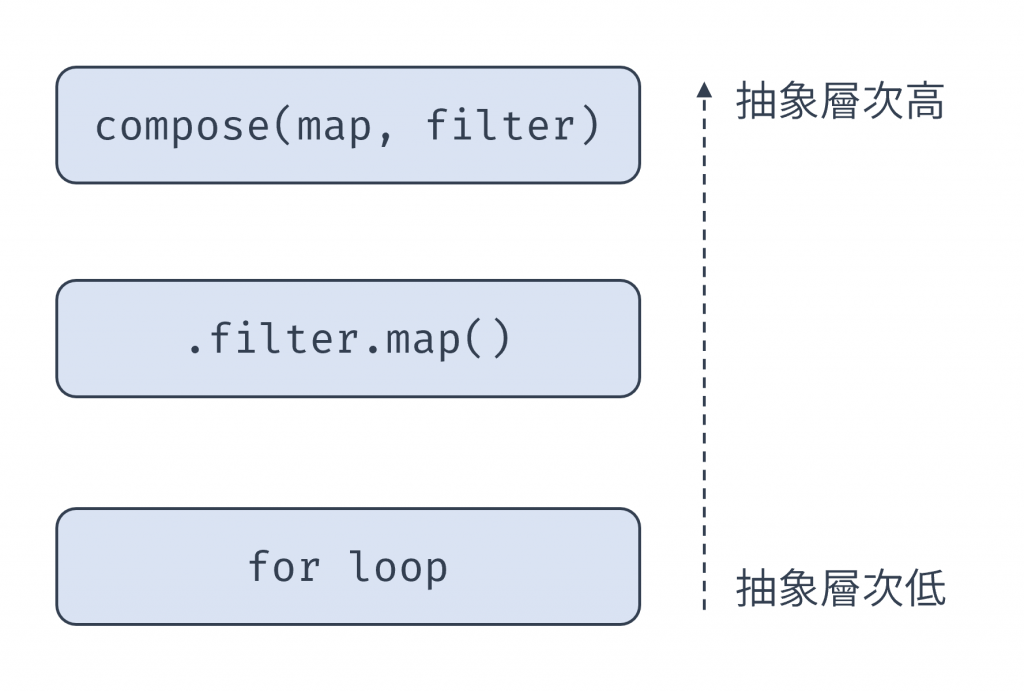
圖 1 三種撰寫方式的抽象層次(資料來源: 自行繪製)
稍微說明一下 Pointful 和 Point-Free 的差異~
在 Functional Programming 的語境中,「Point」指的是函式定義中被明確命名的參數(引數)。例如:
const double = x => x * 2; // x 就是一個 Point

圖 2 Point 指的是函式中被明確定義的參數(資料來源: 自行繪製)
因此 Point-Free 風格也被稱為「Tacit Programming」(隱式程式設計),其字面意思就是在撰寫程式時不需明確提及這些「Points」。
Pointful 是我們平常撰寫的程式碼風格。它直接、明確,資料的流動路徑一目了然。
const isOdd = n => n % 2!== 0;
const getFirstInitial = person => person.firstName;
這種風格的優點在於其直觀性:n 作為輸入,被用於表達式中,然後產生輸出。對於簡單、非組合的函式,這通常是最具可讀性且最合理的寫法。
Point-Free 則轉變了我們的思維模式。我們不再考慮如何操作單一資料,而是思考如何將現有的「運算」組合成新的「運算」。
將上面的 isOdd 和 getFirstInitial 重構為 Point-Free 風格,會長這樣:
// 假設我們有 not, isEven, head, prop 等輔助函式
const isOdd = compose(not, isEven);
const getFirstInitial = compose(head, prop('firstName'));
在 getFirstInitial 的例子中,我們不再思考如何操作 person 物件,而是思考 getFirstInitial 這個「概念」是由哪些更小的「概念」組成的。它可以被分解為兩個更基礎、更通用的操作:「取得一個物件的特定屬性」和「取得一個列表(或字串)的第一個元素」。因此,getFirstInitial 這個概念,就是將「取 firstName 屬性」和「取首位元素」這兩個概念組合起來的結果。
這種方式使得函式之間的「關係」變得明確且具有宣告性。例如,const isEven = compose(not, isOdd); 這行程式碼並不是在說「一個數字除以 2 餘數為 0」,而是在宣告一個數學上的事實:「偶數就是奇數的相反」。這種寫法讓程式碼的意圖變得更清晰,程式碼本身就在註解自己,這正是提升可讀性與可維護性的關鍵。
以下表格比較了三種撰寫風格的差異,要注意的是,雖然這次的系列文是 Functional Programming,但不代表 Point-Free 風格是最好的,實際應用時還是要根據情境選擇最合適的撰寫風格。
| 風格 | 程式碼範例 | 優點 | 缺點 |
|---|---|---|---|
| 命令式 (Imperative) | for (let i = 0; ...) |
對初學者友好,控制流程最直接。 | 冗長、容易出錯、難以複用、副作用風險較高。 |
| 宣告式 (Pointful) | .filter(user => ...).map(user => ...) |
可讀性高、意圖較清晰、鏈式呼叫流暢。 | 仍有匿名函式和臨時參數的噪音。 |
| 宣告式 (Point-Free) | compose(map(getEmail), filter(isAdmin)) |
極致簡潔、高度複用、完美體現關注點分離。 | 學習曲線陡峭、過度使用會降低可讀性、除錯困難。 |
Point-Free(或 Tacit)程式設計是一種程式設計範式,其中函式定義不包含其將要操作的參數資訊。相反,它們是透過組合其他函式來定義的。
更簡單的說法就是:「point free 沒有再跟你說資料長怎樣的。」
另外,要補充的思維是,Point-Free 本身不應該是一個終極目標,而是採用良好 Functional Programming 實踐後自然產生的「結果」。可能有些人在初學 FP 時,會為了消除參數而消除參數,結果寫出不好理解的程式碼,但其實當我們致力於建構小而可複用的函式,並利用柯里化和函數組合將它們串聯起來時,參數往往會自然而然地消失(例如,x => f(x) 可以被簡化為 f)。
因此 FP 追求的目標不是「變得 Point-Free」,而是建立一個由可組合、可配置的小單元構成的系統。Point-Free 風格只是剛好是這系統會有的特色,而不是 FP 的最終目標。
Point-Free 風格建立在我們前面提過的幾個 FP 概念上。
這是 Point-Free 的骨架。如前文所述,compose 或 pipe 是我們建立資料處理管線的機制。
compose(f, g) 會建立一個新函式,且不須提及要處理的資料,它等同於 x => f(g(x))。函數組合讓我們能夠以「組合行為」而非「傳遞資料」的方式來思考問題。
如果說函數組合是骨架,那柯里化就是讓骨架得以靈活活動的關節。
柯里化是將一個接受多個參數的函式,轉換成一系列只接受單一參數的函式的過程。這讓我們可透過「部分應用」來將通用函式特化,使其成為適合函數組合的完美「積木」。
常見的輔助函式例如 prop,prop 是一個用來安全地取得物件屬性的函式。為了適用於 Point-Free 風格,它通常被設計成一個柯里化的函式,並遵循「資料最後 (data-last)」的原則。 prop 的作用是,它會先接收一個「屬性名稱」(字串),然後回傳一個新的函式。這個新函式接著會接收一個「物件」,並回傳該物件對應屬性的值。
範例如下:
const prop = curry((key, obj) => obj[key]);
const getName = prop('name'); // 部分應用,回傳新函式 obj => obj['name']
正是因為 prop('firstName') 會回傳一個只等待 obj 的新函式,它才能完美地被放進 compose 的組合鏈中。
高階函數是指那些可以接受函式作為參數,或回傳一個函式的函式。像 Array.prototype.map 和 Array.prototype.filter 這樣的內建方法,就是我們執行 Point-Free 操作的「舞台」。
常見輔助函式例如 not (或 complement),not 是一個高階函數,它接收一個謂詞函式(回傳布林值的函式),並回傳一個與其邏輯相反的新謂詞函式。 not作用是接收一個函式 fn,回傳一個新函式。當新函式被呼叫時,它會執行 fn 並將結果取反。
範例如下:
const not = (predicate) => (...args) =>!predicate(...args);
const isOdd = not(isEven); // isEven 是一個函式
用一個例子來整合所有概念,這個例子的情境是將文章標題轉換為 URL Slug。
給定一個文章標題字串,例如 " Point-Free Style is Awesome! ",我們希望產生一個 URL 友善的 slug,像是 "point-free-style-is-awesome"。
直覺想到的第一種寫法可能是這樣:
const toSlugPointful = (title) =>
title
.trim()
.toLowerCase()
.replace(/\s+/g, '-') // 將一個或多個空白符替換為連字號
.replace(/!/g, ''); // 移除驚嘆號
這種寫法清楚好懂,但它仍然將「如何做」的細節(title 這個參數如何流動)與「做什麼」(轉換的步驟)混在一起。
現在我們將每個轉換步驟分解成獨立、可複用的函式。
// 將 String.prototype 上的方法包裝成獨立函式,以便組合
const toLowerCase = (str) => str.toLowerCase();
const trim = (str) => str.trim();
// 建立一個柯里化的 replace 函式,以便預先設定好要取代的內容
const replace = curry((pattern, replacement, str) => str.replace(pattern, replacement));
// 利用部分應用,建立特化的函式
const replaceSpaces = replace(/\s+/g, '-');
const removeExclamation = replace(/!/g, '');
有了這些可組合的「積木」,我們現在可以用 pipe 將它們組裝成一個處理管線。
const toSlug = pipe(
trim,
toLowerCase,
replaceSpaces,
removeExclamation
);
// 使用方式
const title = " Point-Free Style is Awesome! ";
const slug = toSlug(title); // "point-free-style-is-awesome"
toSlug 函式的定義是完全 Point-Free 的。它讀起來就像一份清晰的「操作手冊」或「食譜」:先修剪空白、再轉為小寫、接著替換空白、最後移除驚嘆號。管線中的每一個函式都是獨立的,可以單獨測試和複用。這也顯示 Point-Free 如何讓我們專注於流程的組合,而不是資料的傳遞。

圖 3 Point-Free 的toSlug 函式(資料來源: 自行繪製)
Point-Free 風格並不是全然的完美,它也會帶來一些缺點。
針對 Point-Free 最常見的批評是,它會讓程式碼變得晦澀難懂,成為一種「為了聰明而聰明」的無意義(pointless)練習 。一個過長或過於複雜的組合鏈,會讓其他開發者(甚至未來的自己)難以理解其真實意圖。
但 Point-Free 的可讀性問題其實也和程式設計師的命名習慣有關。程式碼的可讀性取決於其抽象的清晰度,而在 Point-Free 中,函式名稱就是抽象本身。
比較以下兩種寫法:
// 寫法一
compose(map(prop('email')), filter(propEq('role', 'admin')))
// 寫法二
compose(map(getEmail), filter(isAdmin))
第一種寫法雖然技術上是 Point-Free,但仍然需要讀者去理解 prop 和 propEq 的用途。第二種寫法顯然更清晰,因為 getEmail 和 isAdmin 這兩個名稱封裝了商業意圖 。因此 Point-Free 實際上是強迫我們精於命名。組合函式的可讀性,直接反映了其構成單元函式的品質。
一個經驗法則是,如果一個函數組合鏈超過了三到四個函式,就應該考慮將其拆分,或為了清晰起見,在某個複雜步驟中有策略地重新引入一個命名參數(即回退到 Pointful 風格)。適度的 Point-Free 是關鍵。
難以除錯是 Point-Free 在實踐中最大的痛點。當一個錯誤發生在 pipe 或 compose 的深處時,除錯會變得異常困難。因為堆疊追蹤(stack trace)通常只會指向 pipe、map、reduce 等工具函式的內部,而不是我們自己編寫的商業邏輯。
不過應對的策略我們並不陌生。如同上一篇「函數組合」文章中介紹的 trace 函式,我們可用 tap 或 trace 這類輔助工具,在不中斷資料流的情況下,像安裝偵錯窗口一樣窺探管線中每個步驟的資料狀態,讓除錯變得可控。此外,將複雜的組合函式包裹在一個具名函式中,也能為堆疊追蹤建立更清晰的框架,是另一種有效的策略。
為了讓文章中的 Point-Free 範例能夠實際運行,這裡提供一個所有提及的輔助函式的簡易實作。在實務應用上,通常會用像 Ramda 或 Lodash/fp 這樣的函式庫,它們會有更完整且經過效能優化的版本。
// 一個簡易的 curry 函式,讓函式可以被部分應用
const curry = (fn) => {
const arity = fn.length;
return function curried(...args) {
if (args.length >= arity) {
return fn(...args);
}
return (...nextArgs) => curried(...args,...nextArgs);
};
};
// pipe 函式,由左至右組合函式
const pipe = (...fns) => (initialVal) => fns.reduce((val, fn) => fn(val), initialVal);
// 接收一個謂詞函式,回傳其相反邏輯的函式
const not = (predicate) => (...args) =>!predicate(...args);
// 判斷數字是否為偶數
const isEven = (n) => n % 2 === 0;
// 取得陣列或字串的第一個元素
const head = (list) => list[0];
// 柯里化的 prop,用於取得物件屬性
const prop = curry((key, obj) => obj[key]);
// --- 實戰演練函式 (Slug 範例) ---
// 為了能直接傳入 pipe,我們將 String.prototype 上的方法包裝成獨立函式
const toLowerCase = (str) => str.toLowerCase();
const trim = (str) => str.trim();
// 建立一個柯里化的 replace 函式,以便預先設定好要取代的內容
const replace = curry((pattern, replacement, str) => str.replace(pattern, replacement));
Point-Free 不是目標,而是良好函數分解與組合後自然呈現的結果。
以幾個列點來總結今天的文章。
getEmail 比 prop('e') 更清楚。user => user.email 提取成 getEmail,就是進入 Point-Free 的第一步。
