今天對Florence-2有更多的認識。
Florence-2 旨在實現廣泛的感知能力,涵蓋了不同層次的理解。這些任務可分為三大類:
-圖像級理解任務 (Image-level understanding tasks):捕捉高層語義,透過語言描述提供對圖像的全面理解。範例任務包括圖像分類 (image classification)、圖像標註 (captioning)(包括簡要、詳細和更詳細的描述)和視覺問答 (visual question answering, VQA)**。
-區域/像素級識別任務 (Region/pixel-level recognition tasks):促進圖像中詳細物件和實體的定位,捕捉物件及其空間語境之間的關係。範例任務包括物件檢測 (object detection)、分割 (segmentation)(例如指稱分割 referring expression segmentation、實例分割 instance segmentation、語義分割 semantic segmentation)、指稱表達理解 (referring expression comprehension)、視覺定位 (visual grounding)、區域提議 (regional proposal) 和文字檢測與識別 (text detection and recognition)**。
-細粒度視覺-語義對齊任務 (Fine-grained visual-semantic alignment tasks)**:需要對文字和圖像進行細粒度理解,涉及定位與文本短語(如物件、屬性或關係)相對應的圖像區域。
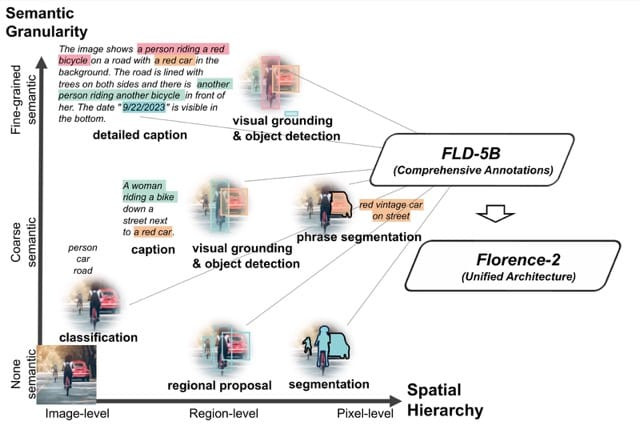
圖片來源:https://arxiv.org/pdf/2311.06242
訓練模型使用 FLD-5B 資料集,圖片來自流行的資料集,如 ImageNet-22k、Object 365、Open Images、Conceptual Captions 和 LAION,資料集中的註解大多是合成的,這意味著它們是自動產生的,而不是人工標註的。研究人員藉鏡其他視覺模型的優勢,不同模型可能擅長於某一方面,例如只會製作邊界框或只會進行圖像分割,他們利用這些任務專門模型提取了其中的一些特徵,並為每張圖片添加了標註。然後訓練模型,使其不僅能為每張圖片預測其中一項特徵,還能預測超過 10 種不同的任務。
圖片來源:https://arxiv.org/pdf/2311.06242
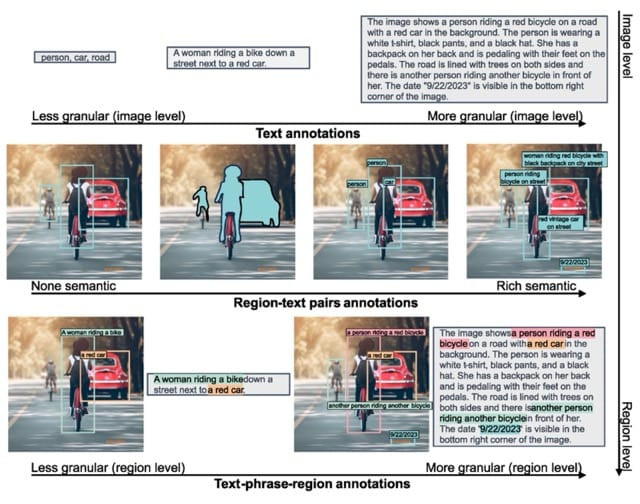
FLD-5B 資料集包括不同類型的標註:文字描述(text annotations)、區域-文本對(region-text pairs),以及文本-短語-區域的組合text-phrase-region triplets)每種類型都有不同的粒度。資料集透過自動化流程構建,利用專用模型(如 SAM、Grounding DINO)生成初始標註;再進行情境過濾與質量提升;最後透過 Florence‑2 自身的不斷迭代生成及改善標註。資料集共計 5 億段文字描述(text annotations)、1.3 億個區域-文本對(text-region annotations)及3.6 億個文本-短語-區域 triplets(text‑phrase‑region annotations)
圖片來源:https://arxiv.org/pdf/2311.06242
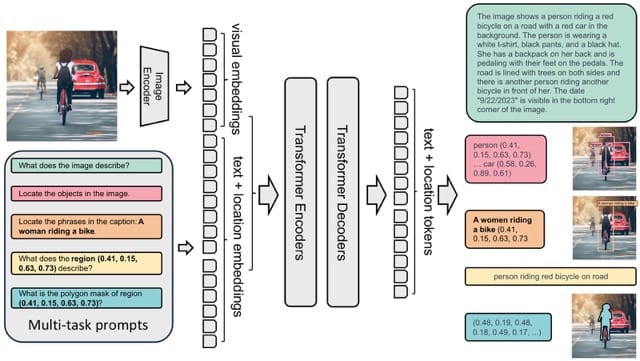
Florence-2 模型透過在 FLD-5B 資料集上進行全面的 多任務學習 進行預訓練,旨在學習通用的圖像表示。
統一架構(Unified Architecture):
模型組件(Model Components):
任務公式化(Task Formulation):
模型規模(Model Scaling):

