
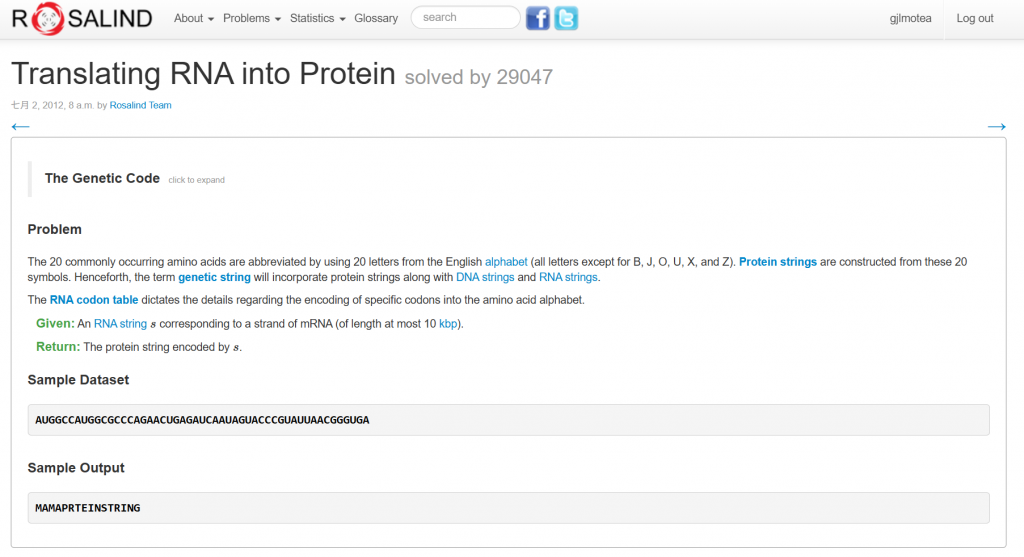
題目連結:https://rosalind.info/problems/prot/
密碼子為三個鹼基一組的序列
就像把一段RNA序列拆包、逐個decode成對應的蛋白質字母
就像ASCII Code把數字對應到英文字母一樣
任三個 腺嘌呤(Adenine, A)、鳥嘌呤(Guanine, G)、胞嘧啶(Cytosine, C)、胸腺嘧啶(Thymine, T)就可以對應到一種胺基酸,胺基酸則用一個字母的英文代號表示
可以參考 小弟部落格文章
輸入
AUGGCCAUGGCGCCCAGAACUGAGAUCAAUAGUACCCGUAUUAACGGGUGA
輸出
MAMAPRTEINSTRING
首先就是要建立出密碼子對應表
codon_table = {
"UUU": "F", "CUU": "L", "AUU": "I", "GUU": "V",
"UUC": "F", "CUC": "L", "AUC": "I", "GUC": "V",
"UUA": "L", "CUA": "L", "AUA": "I", "GUA": "V",
"UUG": "L", "CUG": "L", "AUG": "M", "GUG": "V",
"UCU": "S", "CCU": "P", "ACU": "T", "GCU": "A",
"UCC": "S", "CCC": "P", "ACC": "T", "GCC": "A",
"UCA": "S", "CCA": "P", "ACA": "T", "GCA": "A",
"UCG": "S", "CCG": "P", "ACG": "T", "GCG": "A",
"UAU": "Y", "CAU": "H", "AAU": "N", "GAU": "D",
"UAC": "Y", "CAC": "H", "AAC": "N", "GAC": "D",
"UAA": "Stop", "CAA": "Q", "AAA": "K", "GAA": "E",
"UAG": "Stop", "CAG": "Q", "AAG": "K", "GAG": "E",
"UGU": "C", "CGU": "R", "AGU": "S", "GGU": "G",
"UGC": "C", "CGC": "R", "AGC": "S", "GGC": "G",
"UGA": "Stop", "CGA": "R", "AGA": "R", "GGA": "G",
"UGG": "W", "CGG": "R", "AGG": "R", "GGG": "G"
}
print(codon_table)
# 印出有哪幾種value可能性
s = set(codon_table.values())
print(s)
print(len(s)) # 21 => 20種蛋白質 + 訊號STOP
簡單來說,建立字典後,就能三個核苷酸對應一個密碼子了
程式碼:
codon_table = {
"UUU": "F", "CUU": "L", "AUU": "I", "GUU": "V",
"UUC": "F", "CUC": "L", "AUC": "I", "GUC": "V",
"UUA": "L", "CUA": "L", "AUA": "I", "GUA": "V",
"UUG": "L", "CUG": "L", "AUG": "M", "GUG": "V",
"UCU": "S", "CCU": "P", "ACU": "T", "GCU": "A",
"UCC": "S", "CCC": "P", "ACC": "T", "GCC": "A",
"UCA": "S", "CCA": "P", "ACA": "T", "GCA": "A",
"UCG": "S", "CCG": "P", "ACG": "T", "GCG": "A",
"UAU": "Y", "CAU": "H", "AAU": "N", "GAU": "D",
"UAC": "Y", "CAC": "H", "AAC": "N", "GAC": "D",
"UAA": "Stop", "CAA": "Q", "AAA": "K", "GAA": "E",
"UAG": "Stop", "CAG": "Q", "AAG": "K", "GAG": "E",
"UGU": "C", "CGU": "R", "AGU": "S", "GGU": "G",
"UGC": "C", "CGC": "R", "AGC": "S", "GGC": "G",
"UGA": "Stop", "CGA": "R", "AGA": "R", "GGA": "G",
"UGG": "W", "CGG": "R", "AGG": "R", "GGG": "G"
}
s = "AUGGCCAUGGCGCCCAGAACUGAGAUCAAUAGUACCCGUAUUAACGGGUGA"
for i in range(len(s)//3):
codon = s[i*3:(i+1)*3]
if codon in codon_table:
if codon_table[codon] == "Stop": # 遇到Stop codon就要停止輸出囉
break
else:
print(codon_table[codon], end="")
codon_table = {
"UUU": "F", "CUU": "L", "AUU": "I", "GUU": "V",
"UUC": "F", "CUC": "L", "AUC": "I", "GUC": "V",
"UUA": "L", "CUA": "L", "AUA": "I", "GUA": "V",
"UUG": "L", "CUG": "L", "AUG": "M", "GUG": "V",
"UCU": "S", "CCU": "P", "ACU": "T", "GCU": "A",
"UCC": "S", "CCC": "P", "ACC": "T", "GCC": "A",
"UCA": "S", "CCA": "P", "ACA": "T", "GCA": "A",
"UCG": "S", "CCG": "P", "ACG": "T", "GCG": "A",
"UAU": "Y", "CAU": "H", "AAU": "N", "GAU": "D",
"UAC": "Y", "CAC": "H", "AAC": "N", "GAC": "D",
"UAA": "Stop", "CAA": "Q", "AAA": "K", "GAA": "E",
"UAG": "Stop", "CAG": "Q", "AAG": "K", "GAG": "E",
"UGU": "C", "CGU": "R", "AGU": "S", "GGU": "G",
"UGC": "C", "CGC": "R", "AGC": "S", "GGC": "G",
"UGA": "Stop", "CGA": "R", "AGA": "R", "GGA": "G",
"UGG": "W", "CGG": "R", "AGG": "R", "GGG": "G"
}
def translate_rna(rna: str) -> str:
protein = ""
for i in range(0, len(rna), 3):
codon = rna[i:i + 3]
amino = codon_table.get(codon) # 若table找不到則返回None
if amino == "Stop":
break
protein += amino or "" # 避免TypeError,字串無法與None做組合
return protein
s = "AUGGCCAUGGCGCCCAGAACUGAGAUCAAUAGUACCCGUAUUAACGGGUGA"
print(translate_rna(s))
大公告成!
