
今天要實作的內容是 Generation pipeline 的部分,就是怎麼將提問跟 RAG 檢索到的資料全部丟到 LLM 給他做回應。
因為這邊後面的實作內容我檔案和昨天的檔案其實我是分開來的,所以可能還是會提及一點點昨天的內容,所以這邊再補充昨天的內容,維度只跟「檢索」有關:建索引跟查詢都要用同一個嵌入模型(同一個名稱),這樣向量的維度與語意空間才會一致,所以建議大家不要亂改嵌入模型。
至於 LLM 要用哪個不重要,因為他只負責生成答案,跟維度無關。
在開始之前我們需要先下載好要使用的模型,這邊是在 使用 Ollama 的 mistral,所以需要再命令提示字元輸入:
ollama run mistral
如果你對他聊天有回應就是完成了。
1. 連結 Chroma & 設定嵌入模型(之前實作過的)
# 連結 Chroma,要跟之前設定的一樣
client = chromadb.PersistentClient(path="./law_db")
coll = client.get_or_create_collection("laws")
# 設定嵌入模型
embed_model = SentenceTransformer("paraphrase-multilingual-MiniLM-L12-v2")
2. 將查詢轉成向量(之前實作過的)
def embed(texts):
vec = embed_model.encode(texts, convert_to_numpy=True, normalize_embeddings=True)
return vec.tolist()
怕上次沒有說明很清楚這邊再繼續解釋明白點,這邊是把每句文字編成一個 384 維的向量(這邊的維度是由嵌入模型決定的),並做 L2 正規化;最後回傳 list[list[float]] 讓 Chroma 使用。
3. 相似檢索(Top-k) (之前實作過的)
def search_chunks(query, k=4):
# 獲取先前轉成向量的查詢
q_vec = embed([query])
# 執行查詢,找最相似的 k 筆
res = coll.query(
query_embeddings=q_vec,
n_results=k,
include=["documents", "metadatas", "distances"],
)
# 因為 Chroma 支援一次丟多個查詢,回傳會是「每個查詢一個清單」的巢狀結構。
# 這裡只丟 1 個查詢,所以拿第 0 個即可
docs = res["documents"][0]
metas = res["metadatas"][0]
dists = res["distances"][0]
# 回傳 items:每一筆都有 章名、條號、距離、文字,方便下一步組 Prompt
items = []
for doc, meta, dist in zip(docs, metas, dists):
items.append({
"chapter": meta.get("chapter", ""),
"section_id": meta.get("section_id", ""),
"distance": float(dist),
"text": doc
})
return items
因為不想要弄得太複雜、太難解釋,這邊只考慮你只提問一個問題的情況。
def build_prompt(query, hits):
blocks = []
# 取得欄位數值,做基本處理
for i, h in enumerate(hits, 1):
chapter = h.get("chapter", "")
section = h.get("section_id", "")
distance = float(h.get("distance", 0.0))
text = (h.get("text", "") or "").replace("\n", " ")
header = f"[{i}] {chapter} | {section} | 距離={distance:.4f}" # (來源+分數)
body = f"```text\n{text}\n```" # 內文
blocks.append(header + "\n" + body)
context = "\n\n".join(blocks) if blocks else "(本次查無相關段落)"
prompt = textwrap.dedent(f"""
你是一位專業的台灣資安法規顧問。可以參考相關文件內容回答;
若文件中沒有明確資訊,請回答「文件中沒有相關內容」,不要亂猜。
回答請用中文條列式,並在每條末尾標註對應來源索引。
【相關文件內容】
{context}
【問題】
{query}
""").strip()
return prompt
這邊稍微解釋一下裡面的功能:
後面的 prompt 我們就有定義他的角色身分,他需要的參照內容有甚麼,我們丟問題給他後又有甚麼回應限制,這部分的話其實不一定要照著我的格式來寫,但大致可以參考一下,多嘗試提問才是重點。
def ask_ollama(prompt, llm_model="mistral"):
resp = requests.post(
"http://localhost:11434/api/generate",
json={"model": llm_model, "prompt": prompt, "stream": False},
timeout=120
)
return resp.json().get("response", "").strip()
在這個階段會指定要用的 LLM。用 Ollama 的話,請先把模型拉好並啟動服務(ollama run mistral 會自動下載並啟動)。模型大小要自行評估:檔案太大會佔用磁碟與記憶體;如果是一般筆電,建議先用 7B~8B 級的量化模型。
若想讓中文表達更自然,也可改成 qwen2.5:7b 或 llama3.1:8b 等;不過是否產生幻覺主要還是取決於引用內容 + 提示詞限制 + temperature,不是只靠換模型。
Ollama 通常都是使用 http://localhost:11434/api/generate 這是 Ollama 本機伺服器的預設 API 端點(port 11434),他會用 POST 送 JSON。
timeout 是設定這是 HTTP 客戶端的等待上限(用 requests 設的),超過就丟出超時錯誤。stream=False 會一次性拿到完整回覆。
這些設定完提問後會解析回來的 JSON,抓出模型產生的主體文字在 response 欄位,並用 strip() 去頭尾的空白。
query = "什麼是關鍵基礎設施?"
hits = search_chunks(query, k=4)
prompt = build_prompt(query, hits)
answer = ask_ollama(prompt, llm_model="mistral")
print(answer)
這邊圖片太小我很抱歉 TT
這樣就完成了我們的 RAG 系統,其實我自己也有用同樣的模型然後直接進行提問,這邊可以給大家看一下他的回應。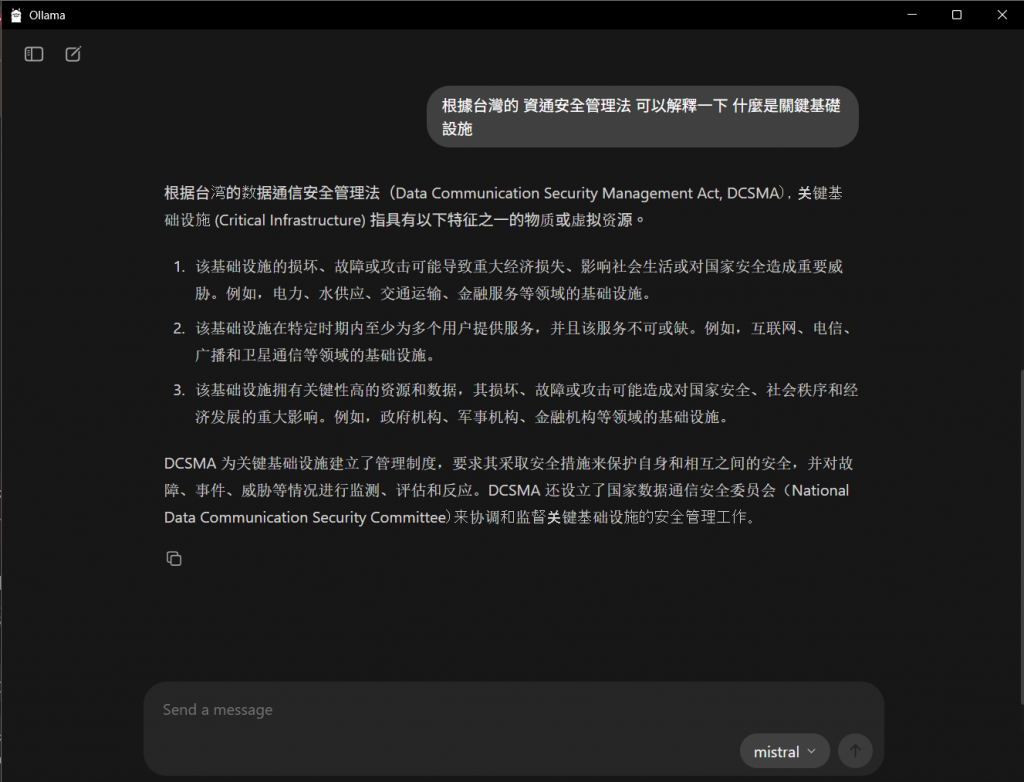
可以很明顯地看到他對於這方面的知識確實是不足的,如果沒有給他參考資料,他就會開始胡言亂語。
今天的部分就到這邊,明天可能會想談談關於 RAG 相關的議題,或是繼續其他方面的研究,先到這啦~

 iThome鐵人賽
iThome鐵人賽