RAG(Retrieval-Augmented Generation)是一種結合檢索與生成的架構,旨在讓大型語言模型(LLM)在回答時依賴外部知識庫以提高準確性。
流程分三階段:
1.檢索器:將使用者問題轉換為向量並在索引中找出相似文件或章節
2.擴充上下文:把檢索到的片段與問題一起組成prompt
3.生成器:由 LLM 根據擴充後的上下文生成回應。主要優點包括減少幻覺、知識可即時更新、便於專業領域應用
RAG的常見挑戰有檢索品質(召回與精準度)、片段切分策略、延遲與成本管理,以及如何處理相互矛盾或過時的資料。實務建議:使用向量索引(如FAISS)、對文件做適當chunking、加入檢索結果來源提示,以及設定驗證機制以追蹤與更新知識來源。
RAG對於客服、法務、醫療與企業內部問答等需要可靠依據的場景特別有用,評估時可採用回答正確率、依據使用率與人工審核回饋優化。
colab簡易實作:
1.安裝套件,把RAG需要的工具裝起來
套件作用:
faiss-cpu:向量資料庫,用來做相似度搜尋
sentence-transformers:Embedding模型來源,把文字變成向量
transformers:用來載入LLM(Qwen)與做text-generation
2.載入Embedding & LLM模型,簡單來說就是準備好大腦(Qwen)和資料搜尋的眼睛(Embedding)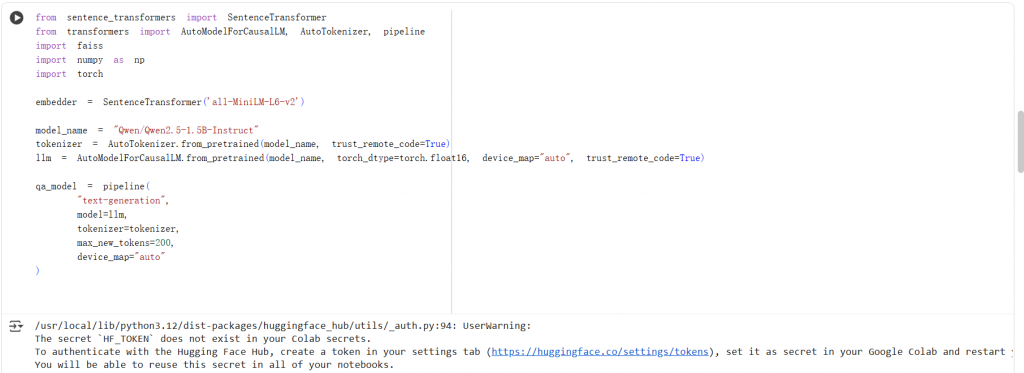
3.建立知識庫
4.建立向量資料庫,讓RAG的「資料搜尋引擎」建起來
encode(documents):把每一段文件轉成向量
faiss.IndexFlatL2(...):建立以L2距離為基礎的搜尋器
index.add(...):把所有向量塞進向量資料庫
5.定義RAG查詢函式
index.search(...)會回傳距離(D)和索引(I),I[0] 裡面就是最相關段落documents 的索引,而[documents[i] for i in I[0]]就是把對應的段落拿出來,由於只要最相關的那個,設top_k=1即可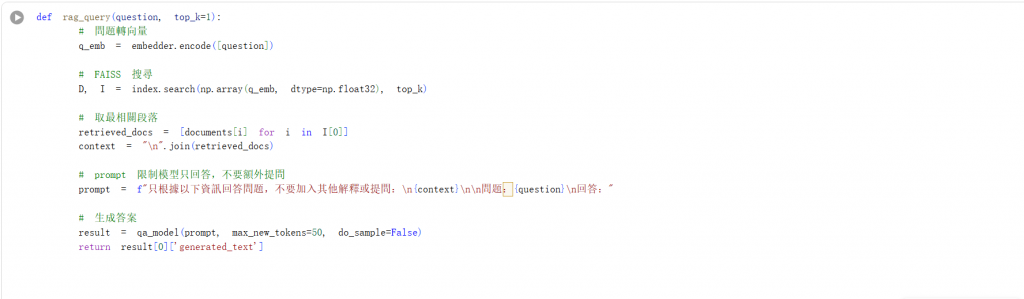
6.輸出結果


 iThome鐵人賽
iThome鐵人賽