前面有說到,Grafana最大的強項就是漂亮的dashboard,要從頭自己做一個dashboard其實真的很難,第一個議題就是到底這個dashboard要看甚麼?
筆者前面有講到,這些dashboard儀錶板看起來真的很帥氣,但到底哪些需要被呈現在儀表板上?這時候其實我們要思考一下,到底哪一些資訊是內部資訊人員(或長官)真正關心的事務,哪些狀態會真正的影響到系統的維運?進而會需要在警報響起時,維運人員會進場確認,並將問題解決後,可以讓維運不至於陷入危險狀態而可以持續維運。
不過自己要從頭開始設計一個儀表板其實非常不容易,因為Grafana基本上可以接到非常多的資料源,例如:
prometheus:這次筆者就是透過grafana來介接到prometheus這個資料來源,如果要自己客製儀表板,那筆者就需要學會使用 PromQL(Prometheus Query Language),這是一種專門用來查詢時序資料的語言,可以進行聚合、過濾、計算等操作。Elasticsearch:使用 Lucene 查詢語法或 Elasticsearch Query DSL,這些語法適合搜尋與分析全文索引資料。SQL Server:使用標準 SQL 查詢語言,適合進行結構化資料的查詢、過濾與彙總。SQL是筆者在以前寫程式時,就學會的一種語言,但其他的都沒碰過啊!!!!!
幸好,筆者在接觸Grafana時,接觸到了 Grafana 官方 Dashboard 市集 ,只要搜尋關鍵字,就能找到適合自己服務的 Dashboard,直接匯入後即可快速開始監控,
如果讀者直接殺到Grafana 官方 Dashboard 市集,打入Kong official關鍵字,會跑出一大堆的Kong official dashboard,筆者最近在寫文章也才赫然發現,原來有這麼多的官方釋出的儀表板喔?那到底要用哪一個?
看心情,喜歡就好。
上面那句話其實有一點任性,但是其實的確是如此,筆者查過了Kong官方回覆有說過,針對不同情境可能會有不同的儀表板(參考Kong 官方回覆),因此這次筆者特別找到在prometheus plugin頁面中的建議,採用了編號7424的儀錶板來做為示範。
請讀者在啟動Grafana,登入後點選由上角的Import Dashboard(參考圖16-1)。
圖16-1 Import dashboard
接下來參考圖16-2,將7424的編號填入Find and import dashboards for common application at gragana.com/dashoards的下方輸入欄位,並點選Load。
圖16-2 Import dashboard
接著,請在畫面中選擇Prometheus的資料來源後,按下Import。
圖16-3 匯入儀錶板
剛匯入的時候,可以注意到圖16-4,雖說有帥氣的儀表板,但是目前因為剛開啟服務而已,尚未有任何流量發生,因此並沒有資料出現。不過讀者也不須著急,可以在Grafana 官方 Dashboard 市集再找找有關於API Provider的相關儀表板。待整個監控儀表板都建立後,再來進行實驗確認,這些儀表板是否適用。
圖16-4 沒有資料的儀表板
過去如果要在Grafana 官方 Dashboard 市集找適合的儀表板,就是透過search的方式去挑選。不過筆者這次試圖去搜尋時,發現了Grafana提供了全新的AI 功能。因此筆者也就試著去與AI 對話,來找看看有沒有推薦的儀表板可以使用。
圖16-5 很AI的搜尋
最後筆者在看了AI幾個推薦之後,選擇了第二個 ASP.NET OTEL Metrics(19896),因為這次的鐵人賽示範專案,就是使用OTEL Collector作為metric的collector。
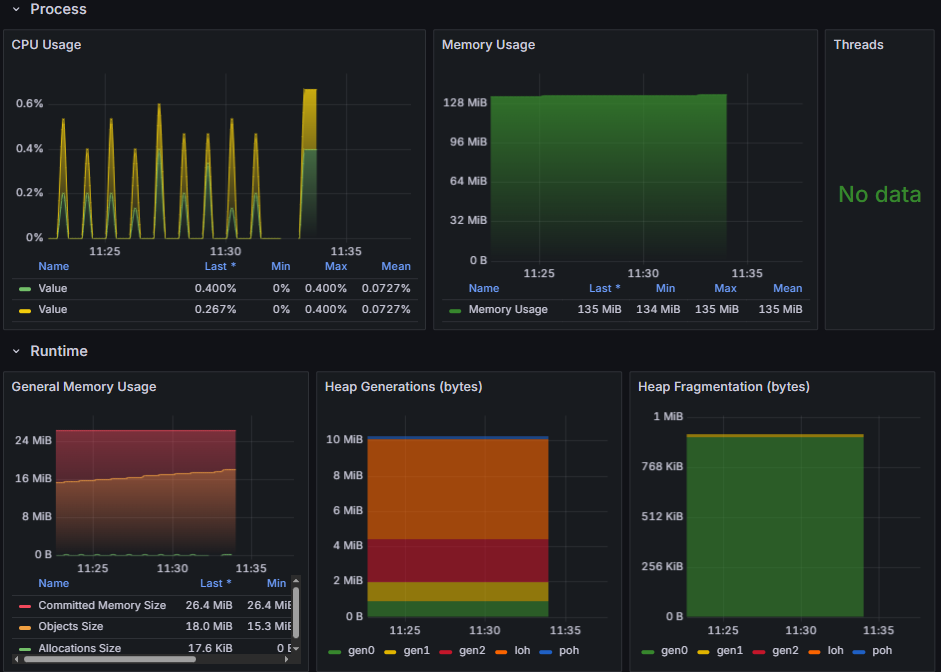
圖16-6 ASP.NET OTEL Metrics
好,儀表板也很帥,同樣的也可以看到指標都有在動了。
由於monitor除了儀錶板外,還與告警有很重要的關係,因此這次的範例程式中,在docker-compose.yaml的檔案中,有以下設定區塊。Grafana支援非常多種其他的告警方式,例如teams、line notify(但這筆者記得line已經不提供服務了)以及Google chat。這個設定的區塊是透過gmail的方式發出告警,這是最簡單的一種設定方式。
environment:
- GF_SMTP_ENABLED=true
- GF_SMTP_HOST=smtp.gmail.com:587
- GF_SMTP_USER=xxxx@gmail.com
- GF_SMTP_PASSWORD=你的應用程式密碼
- GF_SMTP_FROM_ADDRESS=xxxx@gmail.com
- GF_SMTP_FROM_NAME=Grafana
- GF_SMTP_SKIP_VERIFY=true
上面的設定檔中有一段是GF_SMTP_PASSWORD,這不是指Gmail的密碼,而是在Google 帳戶登入後,上方搜尋欄可以找到應用程式密碼的選項。這是用來建立與這個帳號註冊的APP 密碼,類似於微軟EntraID中的應用程式註冊,透過這種方式就可以追蹤在這帳戶下,各式各樣被註冊的應用程式密碼以及活動狀態。這是相較於直接將使用者帳號密碼註冊出去,還要來的安全許多的方式。

圖16-7 Google 帳戶-應用程式密碼
讀者可以先到Google 帳戶-找到應用程式密碼,貼入本次示範的docker-compose.yaml區塊中,接著在把整個服務重啟,再來就能試試看告警服務的測試是否有效了。
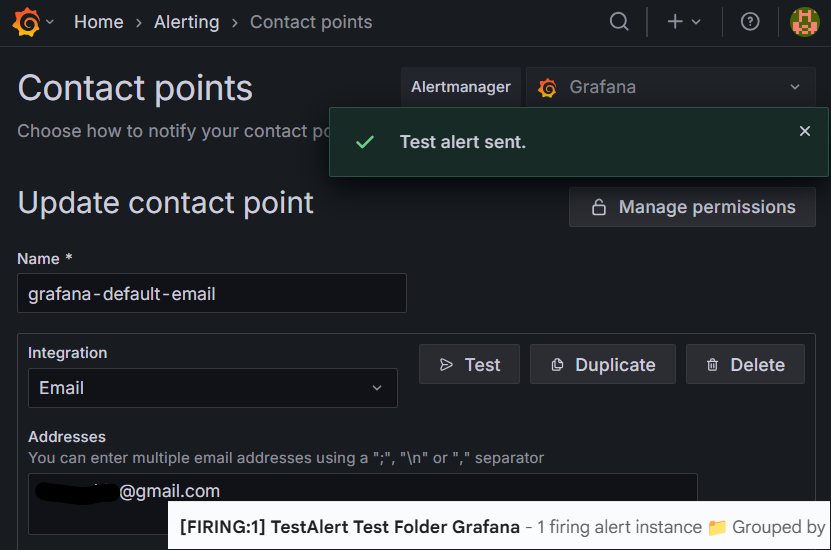
圖16-8 告警發送成功
告警的設定筆者想了很久,發現其實非常不容易在一篇文章中講清楚,因此這邊就用口述,以及提供該Alert rules的匯出檔,如果讀者有興趣玩看看,可以參考筆者匯出的設定檔到自製的Grafana中進行實驗。
檔案皆在示範目錄下:ironman2025\case_ELK_Jaeger_Promethus_Grafana
modify-export-4xx.yaml
kong offical的儀錶板上,modify-export-CPU 70%.yaml
API Provider儀錶板,透過查詢會計算指定服務(exported_job 與 exported_instance)在 user 狀態下的 CPU 使用率變化速率。這段非常簡單,筆者使用Postman連續30次發送沒有攜帶apikey的請求,這就類似模擬使用者對於api有試圖進行不合法的請求,進而可以發出告警後,提醒管理人員進場處理。
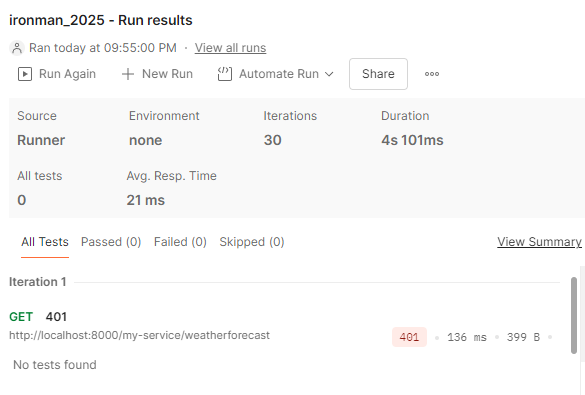
圖16-9 30次 不合法401請求
從圖16-10可以注意到,Kong 會即時監控到這些 401 狀態的請求。
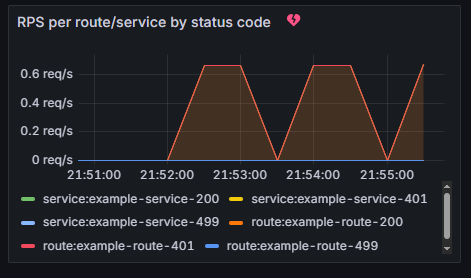
圖16-10 Kong監控到的狀態
當觸發告警條件時,Grafana 會在儀表板上顯示警示訊息,如圖16-11 所示。
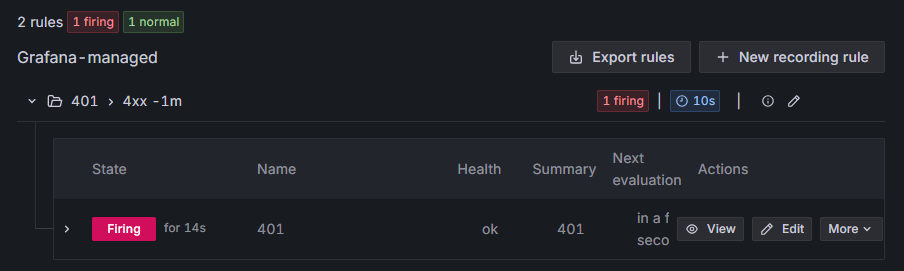
圖16-11 觸發告警條件
同時,系統也會自動寄送告警信件到管理人員信箱,通知有異常行為發生(圖16-12)。
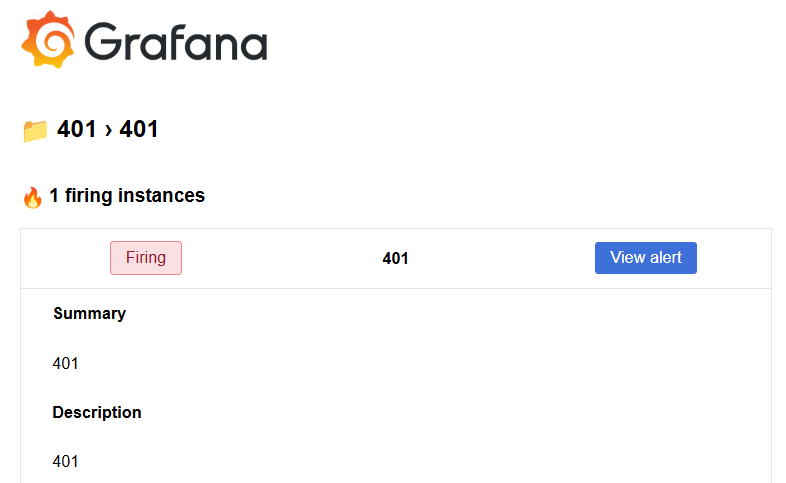
圖16-12 收到告警信件
值得注意的是,這些不合法請求並不會影響到後端 API 的正常運作,系統依然可以穩定服務其他合法用戶(圖16-13)。
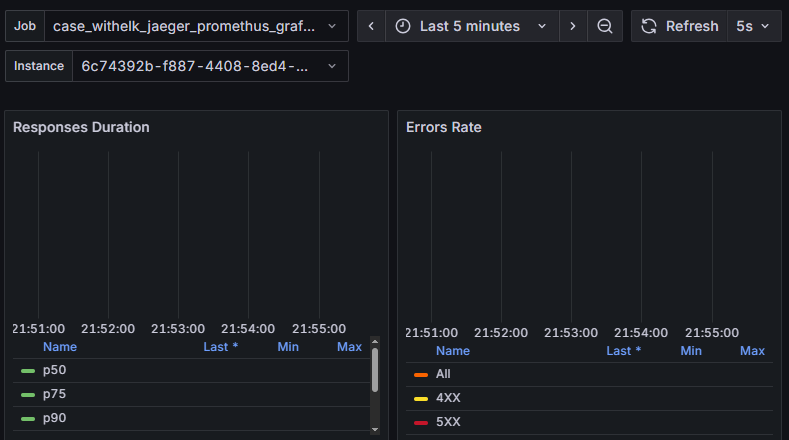
圖16-13 後端API 無影響
接下來,筆者針對後端的API也進行了一段監控,是根據上面範例設定中來監控API CPU如果超過70%,就會發生告警。實務上筆者這樣的設定其實太過嚴苛,不過這是為了鐵人賽的文章示範所做的,讀者如果要應用到工作上,請思考如何設定才可以符合工作需求。
這次對於程式的部分,為了這個實驗稍微做了一些調整,這邊就先不說明,先針對告警是否有發出通知來進行實驗。
同樣的,使用postman來進行實驗,這次就僅發送攜帶正確的apikey的請求執行20次。可以參考圖16-14,可以注意到有一個特點,那就是明明都得到了200的回應,但有些請求回應會在1-2秒,有一些卻會高達30-40秒。
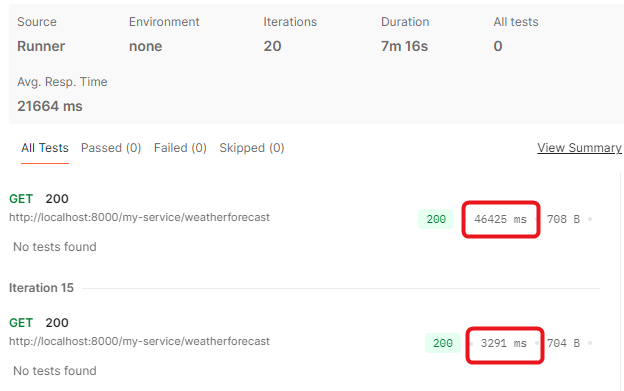
圖 16-14 很奇怪的執行時間落差
接下來來看各個儀表板與告警,首先先注意到圖16-15,左邊是kong協助代理所耗費的時間,而右邊卻是整個請求的執行時間。這個段落就可以注意到有發生延遲,但不是被發生在kong,因此會需要進一步關注原因。
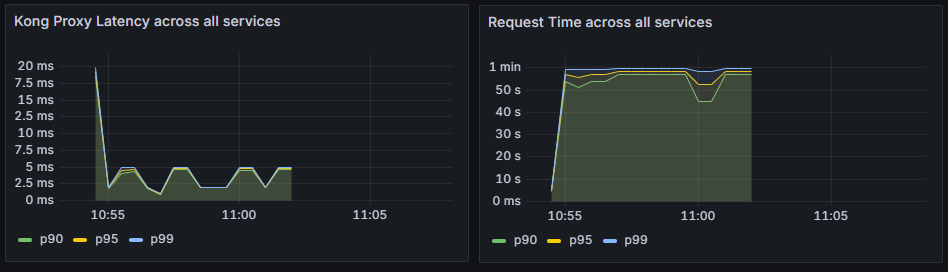
圖16-15 Kong 與 API之間的執行時間落差
接下來,注意到圖16-16與圖16-17,可以看到這次要驗證的CPU使用率超過70%的警報被觸發了。當然也收到了通知信件,要求管理人員進場處理。

圖16-16 被觸發的CPU警報
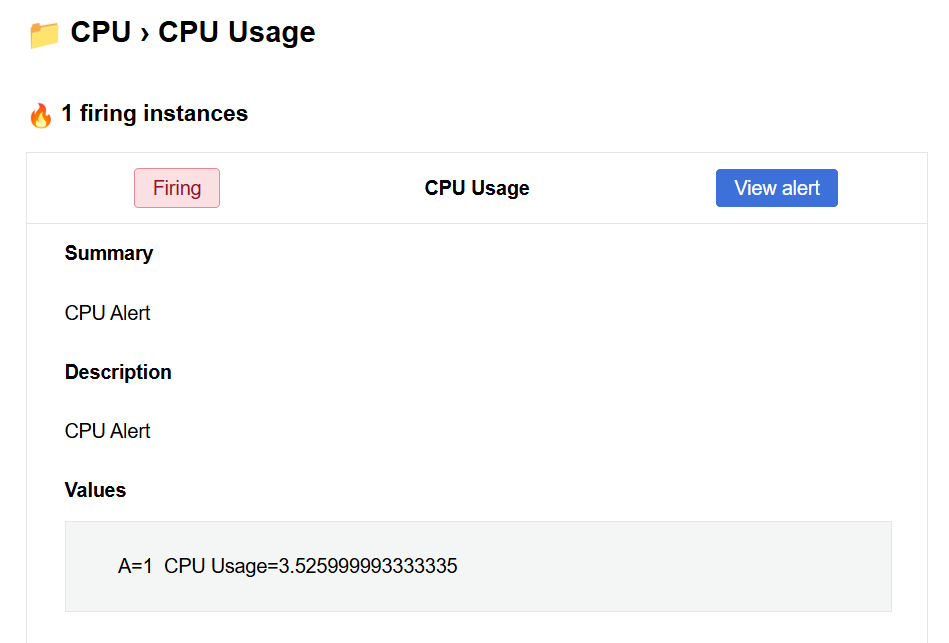
圖16-17 警報信件
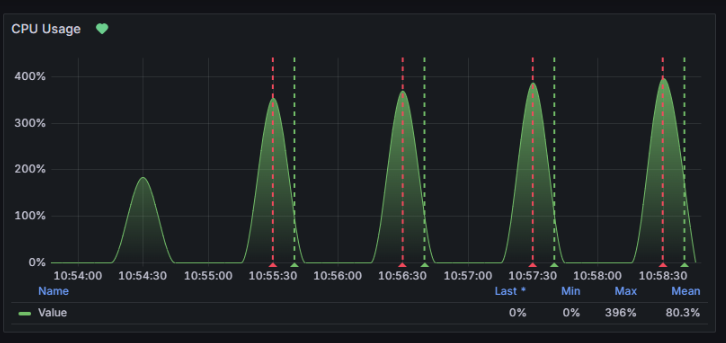
圖16-18 CPU的儀表板
接下來看到圖16-18,可以注意到在執行的過程中,CPU有過不正常的波動,有一些曾經飆升到近400%(筆者電腦4core)也因為這個行為,有觸發了這次設定的告警。
今天一共做了兩個示範,分別說明一下觀察到的重點。
第一個示範就很棒呈現了,基於kong作為API Gateway 保護後端API 服務的一個經典案例。同前面所提到的,API 與網頁最大的不同就是,大多數的網頁系統都是基於消費者或是使用者,在訪談以及系統分析時,已經會將認證授權作為硬性需求被設計在系統中。
但API在初始設計時,特別是如果要在每一個服務每一隻API下都做自己的認證授權的功能,除了造成重工問題外,也很容易就忘記在設計甚至測試階段將安全授權的部分設計進續。
這時候透過一個API Gateway 就能夠基本的協助認證與授權,阻擋在外圍而不影響後端API。並且藉由kong能夠與告警系統的結合,可以快速地發現問題,要求管理人員進場處理。
監控與告警並不會只存在gateway閘道上,應該是要去思考,在各個四散的服務中,哪一些是營運人員關注的重點。讀者可以思考看看,通常在事故發生的當下,第一時間的判斷是首要的重點。但如果監控、告警與追蹤資訊不足的前提,是不是都是透過組織中某些通靈者來進行第一時間的判斷。
筆者也做過這個通靈者的角色,但其實那只是基於經驗與知識去做猜測,並沒有足夠的資訊來指出就是這個問題。不過維運也很現實,需要持續維運的前提,就需要進行一些判斷後,在時間內下決定,最終觀察結果。
猜中了是神,猜錯了就....繼續猜到對。因為被維運的系統是中立的,不會因為乖乖就恢復正常,但這也是身為資訊人員最喜歡的邏輯。
今天的文章寫出了,如何在體系中完善monitor的各個服務要素。但別忘了,故事還沒完,不是監控出來就可以搞定整件事情,最終還是要找到根因進而進場協助開發人員修復。
但今天寫得夠多了,明天來針對今天的Case 2來查找問題,進而解決根因。
明天見。

