昨天第二個示範案例觸發了CPU的警報,這是筆者特別設計的場景。今天打算針對昨天的告警事件,用故事的方式帶大家一起探索,如何在日常生活場警,透過可觀測性三本柱,來將事件抽絲剝繭後,找出問題的根因。
想像某個早晨,Sam正準備拿起水壺到茶水間裝熱水回來泡咖啡前,聽到了同事在談一個客訴事件。
Lala: 昨天好像有對接API的廠商在反應,有時候我們提供的API會有反應很久的狀況,聽說已經抱怨到業務去了。
Aries: 聽說負責人前兩天有過版,我這邊是沒有對kong做過一些調整,是不是跟過版有關係?
Lala: 可是也聽說資安在那次過版過程中,好像有被抱怨有些東西沒有通,看他們跟網管推來推去的,不曉得真正的原因是甚麼。最終也不知道怎樣解決,他們那塊一直很謎。
Aries: 反應很久是效能問題嗎?還是那時候防毒還是甚麼的在跑?或是甚麼排程讓那台機器運算效能滿載?
上面的故事不曉得身為工程師的讀者有沒有很熟悉?
這真的是很常發生的場景,如果沒有足夠的資訊,只能依賴看有沒有哪一位救世主可以挺身而出,根據蛛絲馬跡當一個福爾摩斯,最終找出那位兇手,才能把問題解決掉。
不過既然這個系列文已經將可觀測性實踐主要的三本柱都建設完成,今天就跟著昨天的示範去追尋問題發生的根因。
剛剛聽完同事討論的內容後,Sam也加入了討論。
Sam: 昨天好像有發生CPU告警事件喔!不過時間不是很長,有一點斷斷續續的,要不要一起看看?
Aries: 我好像也有注意到那封郵件,不過我看很快就Resolved了,所以也沒深究。
Sam: 畢竟現在已經有客訴事件,這時候是絕佳時機進場探索問題的根因,如果是誤報可能要討論告警的閥值是不是要調整,以免造成雜訊影響我們。但如果是這次事件的正常反饋,那就可以一併找出問題所在,解決客訴。
Lala: 那讓我來翻出昨天那封告警郵件。

圖 17-1 告警信件
Sam: 的確是在一分鐘之內就結束了,不過grafana的警報有時候會根據設定,短時間內不會發出很多次同樣的告警資訊,讓我們把儀表板拉出來分析看看,在那個時間內是不是有異常資訊。
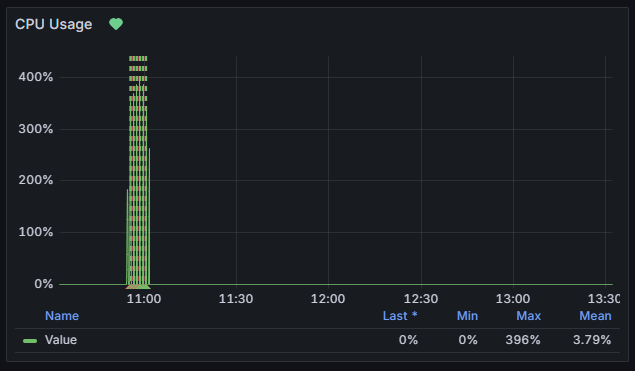
圖17-2 告警信件的儀錶板
Lala: 這裡的數值很奇怪,看起來這支API並不是常常被呼叫,但是每次被呼叫都會讓CPU飆到可以被告警的狀態,這是多次呼叫嗎?我們把時間集中在發生的區間,看更清楚些。
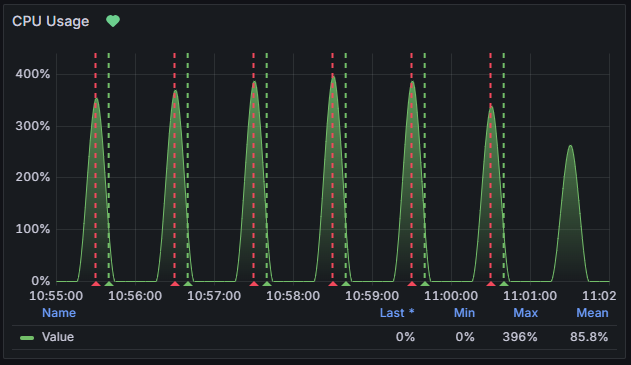
圖17-3 發生當下的細節
Aries: 看起來當下有比較高大概七個請求,其中達到閥值的有到六個,滿奇怪的。不過這到底大概代表著甚麼?當下CPU很忙?不過怎麼只會剛好與這個服務被請求有直接關係?
Sam: 我們可能要細查一下,先確認到底那個時段有多少個請求,也可以看一下是不是有特定延遲的問題。
Lala: 那下一步就是Jaeger了對嗎?
Sam: Bingo。
由於基本上確定,在某個時間內發生了一些狀況,因此準備透過三本柱的trace來進行該時段內的追蹤。因此三個人打開了Jaeger,準備對該時段的追蹤資訊進行判讀。
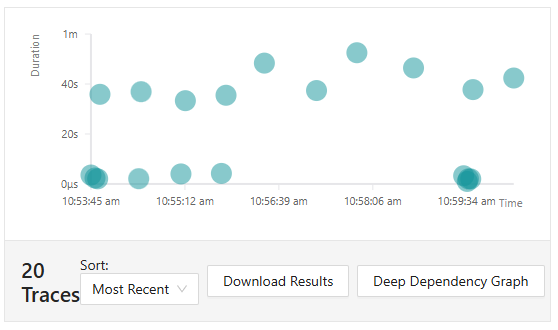
圖17-4 Jaeger的資訊
Lala: 酷欸這個圖。
Sam: 看起來最少有20個請求以上,但分布的狀況也很特別,因為明明就同樣的請求,內容有所不同才導致執行區間有這麼大的差異?還是說引入參數不同造成後端需要處理不同的運算嗎?
Aries: 抓兩筆請求資料來看一下好了,比對看看引入參數有沒有太多差異。
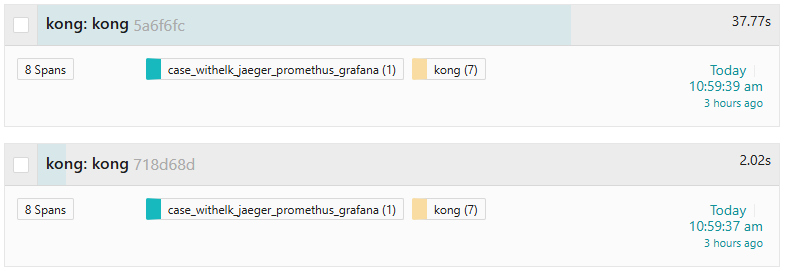
圖17-5 找兩筆關鍵資料比對
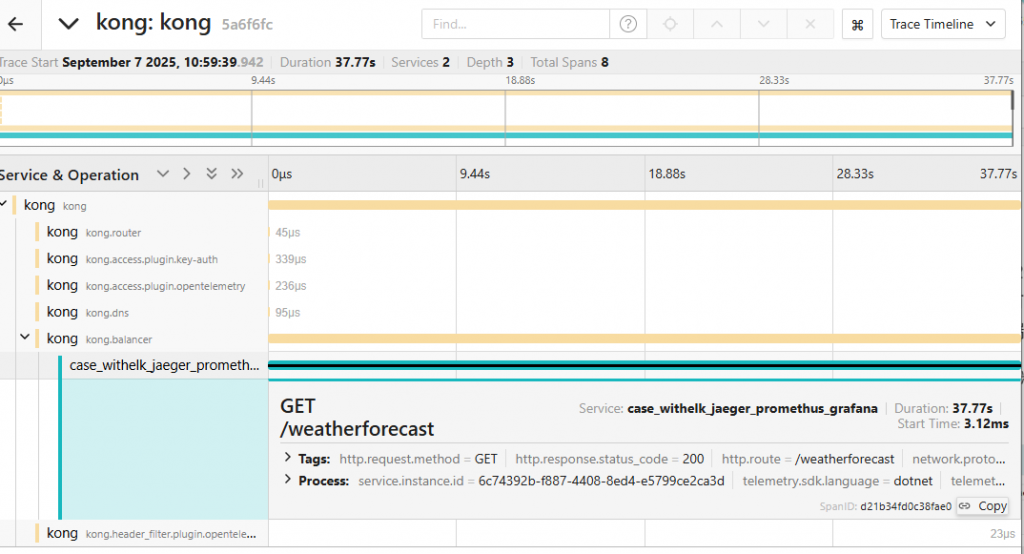
圖17-6 比較長的請求
Lala: 看起來請求內容都是一樣的阿,都是GET,但卻有的執行時間高達幾十秒,快的則在一兩秒內就結束了,這到底問題在哪啊?
Sam: 很棒,因為至少我們可以確認,該API的確在那個時間區段的有一半筆數的請求,回應時間非常的長。而且也因為kong當時也有開可觀測性的plugin,因此也能判斷的出來,時間延遲並不是在kong,而確定是在後端發出告警的application。
Aries: 再來就是Log了。
Lala: 讓我們先把執行時間超過30000 ms的條件輸入,並且把執行時間鎖定在我們追蹤到的時間區間內。OK,調出來了,都有記錄到。
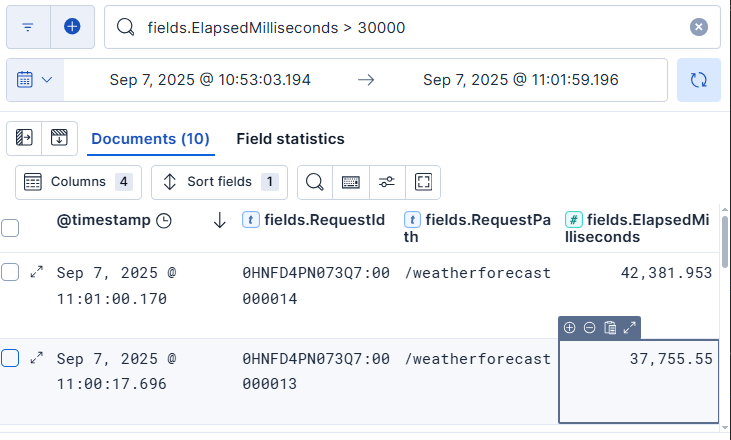
圖17-7 執行時間超過30000 ms的日誌
Aries: 那就抓執行時間 37,755,55那筆好了,把那筆的RequestId:0HNFD4PN073Q7:00000013作為搜尋條件,然後把fields.ElapsedMilliseconds > 30000的條件拿掉,因為那是請求最後計算的欄位,該次請求其他日誌資訊不會有該欄。
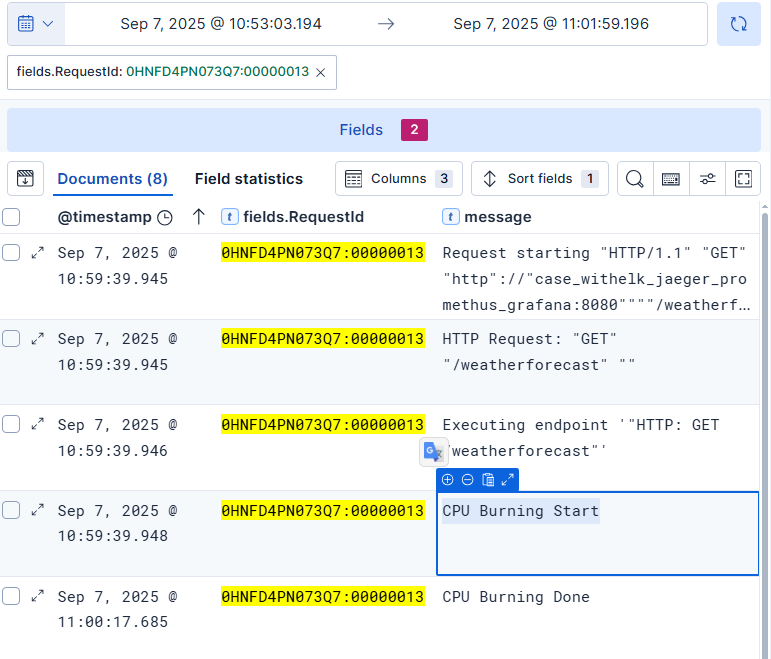
圖17-8 RequestId:0HNFD4PN073Q7:00000013
Lala: 等等,那是甚麼?為什麼在日誌中有一段CPU Bruning Start與CPU Burning Done?而且那個執行期間還花了近乎40秒,這不就表示在那區間內有非常忙碌的運算在進行?
Sam: 跟其他筆時間執行比較段的日誌來看,並沒有這一段log,看起來原因找到了,可以通報該系統開發人員進場,確定一下到底這段日誌的目的是甚麼。
上面那個故事,是基於筆者在這次的示範中特別撰寫的程式碼,問題其實是在程式碼中多了一下的內容:
// 平均每三次有一次執行 CPU 狂飆
if (Random.Shared.Next(0, 3) == 0)
{
// 執行 1000 次的 while 迴圈,模擬 CPU 狂飆
int count = 0;
Log.Information("CPU Burning Start");
while (count < 1000)
{
// 做一些無意義的運算
double x = 0;
for (int i = 0; i < 10000000; i++)
{
x += Math.Sqrt(i);
}
count++;
}
Log.Information("CPU Burning Done");
}
else
{
// 原本的隨機等待 1~10 秒
var delaySeconds = Random.Shared.Next(1, 10);
await Task.Delay(delaySeconds * 1000);
}
目的是為了營造出特殊的事件觸發告警,並利用三本柱的各個特性去找出問題可能的所在。這些都是為了讓資料不斷的被蒐集,在特殊狀況發生當下,可有根據資料有所本的去找出真正的根因。
前幾天建置基礎設施,其實筆者撰寫的有一點乏力,因為基礎設施的建置說明寫起來略為無聊。
但基礎設施基本上已經建立完成,未來後面的鐵人賽,都會盡量利用各種不同的場景與故事,來讓讀者了解各種場景與應對的措施。
明天見~

