資料庫大哉問已 MySQL 為主介紹了許多資料庫設計用到的技術,這些技術不限於 MySQL,能在大多資料庫系統中看到類似的身影。
為了用 Binary Search 查詢,大部分資料庫都需要維護一個有序結構,例如 BTree 或者有序陣列等。
MySQL & PostgreSQL & MongoDB 都用 BTree 作為索引結構,好處是查詢效能穩定,壞處是更新資料時要先找到資料位於哪個節點 (Page) 位置,並對節點上鎖後更新。
而 Cassandra & Clickhouse 等對寫入效能有要求的資料庫,就會使用有序陣列,將記憶體中的有序結構整個寫進一個不可變動的檔案,好處是寫入效能快,壞處是查詢效能不穩定,需要有另外的稀疏索引或 bloom filter 快速判斷哪個檔案有資料,還需要定期 Merge 多個檔案。
要維持有序結構同時要提升寫入效能,就需要在記憶體中完成寫入,例如 Cassandra & Clickhouse 都是在記憶體中維護 Skip List or AVL Tree 的有序結構,不斷寫入資料到一定的量後在整批寫進硬碟。
而為了確保資料不遺失,需要將資料先更新到 WAL 檔案中,WAL 就是很單純的 append only 結構,不需要是有序結構,可以是單純的 FIFO Queue 結構,而為避免瞬間大量寫入通常會有批量 fsync 機制,例如 MySQL 的 group commit 或者 Cassandra 可以設定多久執行一次 fsync。
大部分資料庫都使用 MVCC 機制來解決 Dirty Read 問題,只不過儲存不同版本的方式不同,例如 MySQL 是用 Undo Log,PostgreSQL 是 Heap 中儲存並用 xmin & xmax 欄位。
寫入高效的資料庫大部分都捨棄 B+Tree 結構,使用 Immutable File 的方式新增和更新資料,例如 Cassandra, Clickhouse & Elasticsearch 都是先在記憶體中累積一下資料後,把整批資料寫進 Immutable File。
而要將多個有序檔案 Merge 回一個檔案,可以使用 min heap,先從每個檔案拿出第一筆資料全部放進 min heap,pop min heap 找出最小 element,將最小 element 寫進新的檔案,同時去該 element 檔案中拿下一筆資料在放進 min heap,不斷重複該流程,直到 min heap 沒有資料。
假設 N 為總元素數,k 為檔案數,時間複雜度是 O(N log k),記憶體需求 O(k),只要存每個檔案當前指標的那筆資料即可。
當資料量變大,為每筆資料建立額外的索引結構不只會影響更新效能,同時將大量索引放進記憶體也會佔用太多空間,因此稀疏索引就是平衡查詢效能以及空間使用的關鍵技術。
MySQL Page 中的 page directory,Clickhouse 的索引都是稀疏索引。
MySQL & PostgreSQL 兩者皆是業界常用的資料庫,都提供了完整的功能,不過 PostgreSQL 確實比 MySQL 多一些實用功能,例如不同 index type,lock type 和豐富的 extension。
此外也可以看 Medium 上有一篇對兩個 DB 的效能比較 (https://rizqimulki.com/mysql-9-x-vs-postgresql-17-which-is-faster-9915918e1884)
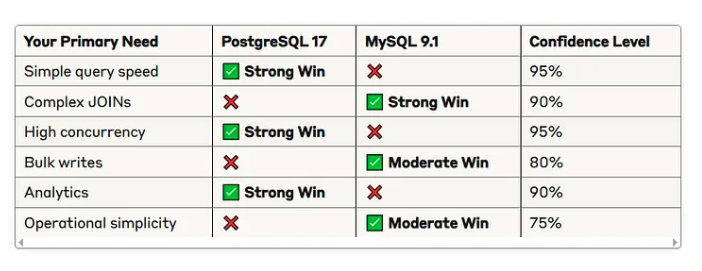
(來源:https://rizqimulki.com/mysql-9-x-vs-postgresql-17-which-is-faster-9915918e1884)
PG 在單筆查詢,高併發寫入效能較好,也符合其 Heap 跟 Lock 的設計,而 Analytics 效能也歸功於其 Parallel Query 功能,在 aggregation 時能更快 。
而 MySQL B+Tree 設計在範圍 & Join 多筆資料時效能更好,且 PG Bulk Write 時資料量較容易超過 Page 剩餘空間,無法觸發 HOT 導致造成大量 I/O 效能較差。
最後 MySQL default 設定就能有不錯的效能,且 Disk & CPU 消耗比 PG 少,因為 PG 有 MVCC 表膨脹跟 Vaccum 吃額外 CPU,且 PG 需要針對業務情境調整配置,例如 autovacuum 優化,以及使用 PG extension 或者 advance query 都要對 PG 底層理解才不易使用錯誤,因此 MySQL 操作相對簡單。
最後文章說,如果想要高併發和快速的單筆查詢,以及使用更多先進功能,首選肯定是 PG,反觀如果是維運單純成本考量就選 MySQL。
不過,很多人常說能選 PG 就不要選 MySQL,大多時候我其實也偏好 PG 多一點,因為 MySQL 併發效能真的比較差,且 PG 比較多有趣功能可以玩。
但也可看一些反面案例。
例如 uber 2016 的文章 (https://www.uber.com/en-TW/blog/postgres-to-mysql-migration/) 說他們從 PG 換回 MySQL。
主要原因是 PG MVCC 機制寫入有大量 I/O 以及早期 PG 的 master slave 架構,是直接用 WAL 作為 slave 同步資料源,由於 WAL 是用 Page 格式,會導致傳輸資料量大,跨 data center 同步資料會很花錢,而且 Master & Slave 版本要一樣不方便升級。
不過 PG 10 支援 Logical Replication 可解決 uber 文章中提到的 replication 問題,但 uber 還提到其他問題,例如 PG 大多時候會用 kernel cache,比較少用 shared buffers,因此會有頻繁的 context switch (kernel space <=> user space) 切換。
另外 PG MVCC 設計其實為人詬病許久,例如 https://www.cs.cmu.edu/~pavlo/blog/2023/04/the-part-of-postgresql-we-hate-the-most.html 也是在說表膨脹和 Vacuum 管理,因此要用 PG 需要對其底層有深度理解,才能充分發揮其優勢,並享受他各種炫砲功能。
幾年前 MongoDB 因為他的 Scalability 聲名大噪,NoSQL + Sharding 功能被很多工程師推崇,但當時很多人也忽略 MongoDB 為了 Scalability 犧牲了什麼。
例如早期 MongoDB 的寫入不會立刻執行 fsync 代表寫入只放在記憶體,過一段時間後才同步到硬碟,效能很快,但犧牲 Durability,此外就是 Write & Read Concern 預設配置會導致跨 DB 的 Dirty Read 現象,以及跨 Sharding 資料會有一致性問題等。
雖然說許多問題發生機率不高,發生時也不一定會很嚴重,但反過來思考,真實業務要用到 Sharding 分散式資料庫技術的時候也不多,很多大公司還是 PG & MySQL 用得好好的,不過像 Google 要處理 PB 級資料還是會用到分散式資料庫,但他們也有能力開發自己的分散式資料庫 (BigQuery)。
那 MongoDB 真的毫無用處嗎?其實 document 儲存還是滿好用的,雖然 PG & MySQL json type 支援越來越好,但對於 ACID 沒嚴格要求,需要 schema free 且資料量大的場景 MongoDB 還是很適合的,例如遊戲 & IOT 等系統的日誌收集。
https://discord.com/blog/how-discord-stores-billions-of-messages
Discord 早期為了開發快速使用 MongoDB 儲存訊息,但隨著訊息量變大,單台 MongoDB 查詢效能出現問題:
最終導致 Cache 容易 miss,查詢造成 Disk I/O 因此變慢。
為解決這個問題,Discord 需要能輕易水平擴展,自動 fail over,好管理的資料庫。
雖然 MongoDB 也有 sharding 水平擴展功能,但需依賴獨立的 config server 維護 sharding metadata,且一個 sharding 只有一個 master 負責寫。
而 Cassandra 透過 gossip 交換 sharding metadata 給所有資料庫,且一個 sharding 有多個 master, scalability 機制更完善,availability 也更好。
此外 Cassandra 使用稀疏索引 (e.g bloom filter),即便單 shard 資料量很大,也可將大量 index 放進記憶體,能提供更穩定地查詢效能。
Cassandra 缺點是沒有嚴格的 Isolation,且為 AP 系統,採用 eventual consistency,併發 read-before-write 高機率會有 write skew,因此預設所有寫入 (insert or update) 都是 upsert 才能確保相同 key 不會重複寫入,且採用 Last Write Wins 機制透過 timestamp 決定資料最後版本。
而 upsert + Last Write Wins 機制在分散式併發下會有一些問題,例如同時對 user 執行:
db a 執行 transaction a
update users set name = 'vic' where id = 1
db b 執行 transaction b
update users set age = 20 where id = 1
如果原本資料為 users (id=1, name=null, age=null),db b 執行後 users 變成 (id=1, name=null, age=20),然後接收到 db a 同步 (id=1, name=vic, age=null),但因為 timestamp db a 可能落後 1ms 導致被忽略,最後資料在 db b 就會變成 (id=1, name=null, age=20) 欄位遺失的狀況。
因此 Cassandra 建議 update 都要帶所有欄位,不過 discord 還踩到另一個問題是,delete & update 同時發生,由於 update 是 upsert 就會導致被刪除的紀錄又跑出來了,因此要額外用 author_id 是否為 null 判斷資料是否可用。
另外是 Cassandra delete 資料不會馬上刪除而是標記成 tombstone,查詢是要跳過 tombstone 資料,且資料是已 column 為單位儲存,一個 cell 為 partition_key + clustering key + column_data,如果將太多 column 更新為 null 會產生大量 tombstone 影響查詢效能,因此雖然 Cassandra 建議 update 要帶所有欄位,但 Discord 做法是只帶入 non-null 欄位並用 author_id 判斷資料是否可用。
最後 Discord 遷移到 Cassandra 後發現寫入穩定在 0.5ms 而查詢穩定在 5ms 以下,即便是查詢很久以前的訊息效能也很穩定,此時他們已經處理幾億筆的訊息了。
不過值得注意的是,某天他們發現 Cassandra 頻繁出現 10 秒的 GC STW ,原因是某個頻道訊息被刪除只剩一條訊息,但是刪除的訊息還是 tombstone 狀態,導致即便讀取一條訊息還是要載入大量 tombstone 到記憶體,觸發 Java GC 需要刪除大量 object 導致 STW 變很久,因此他們也在考慮換成 Scylla 。
最後雖然 B+Tree 提供不錯的查詢效能,但不同查詢情境還是需要不同資料庫,例如
使用這些資料庫,不代表要捨棄 OLTP (e.g MySQL or PostgreSQL) ,而是透過 CDC 機制將 OLTP 的資料同步到 Elasticsearch or Clickhouse。
常見 CDC 工具像是 Debezium,是透過實作 Kafka connector 將資料 (e.g MySQL binlog) publish 到 Kafka Topic,隨後可透過 spark or flink 將 streaming data 批次寫入到 Elasticsearch or Clickhouse。
在選型資料庫時,大部分情境挑 MySQL or PostgreSQL 肯定沒問題,即便資料量越來越大,也可透過冷熱數據分隔方式,將冷數據 (e.g 三年前的訂單紀錄) 用 iceberg format 儲存到 AWS S3。
遇到查詢效能問題,可用 Redis 解決,如果是寫入效能,可用 Kafka 異步解決,不過加 Redis & Kafka 都要處理一致性問題。
另外 CDC 個人覺得是滿重要的基礎建設,因為冷熱數據分隔,或建立 data warehouse,使用 elasticsearch or clickhouse,CQRS pattern 都會需要 CDC 。
參考 Discord 情境,如果遇到查詢很隨機 (e.g 查詢一年前訊息) 且資料量很大,那分散式資料庫就需要考慮,但也要考量業務情境對 ACID 的要求,因為分散式架構下 ACID 實現會更困難。
雖然 MySQL or PostgreSQL 原生不支援 sharding,但也有 shardingsphere 能把你的 MySQL or PG 變成分散式資料庫,並管理分散式 transaction & sharding。
最後分享一個影片 https://www.youtube.com/watch?v=b2F-DItXtZs ,有時候效能不是絕對的指標,必須知道為了效能我們犧牲了什麼。
希望大家看完這個系列都有學到新東西,也懇請大家能花 1min 填回饋表單 https://forms.gle/rwEuAGELK5MHbwAC8 給我一些建議幫助我在寫作的路上更精進!
About Me
歡迎大家追蹤我的 Thread,平常會在上面分享技術文章
https://www.threads.com/@chill.vic.22
雖然 B+Tree 提供不錯的查詢效能,但不能查詢情境還是需要不同資料庫
typo 但不同查詢情境
CQRD pattern 都會需要 CDC 。
typo CQRS pattern
最後一天還有各種公司的資料庫案例
感謝分享!
感謝抓錯字~~


 iThome鐵人賽
iThome鐵人賽