
文章搜尋是經典系統設計題,常見文字查詢有 Regex 跟 SQL Like,然而 Regex 效能差,SQL Like 不夠精準,例如 LIKE %dog% 會回 hotdog。Full Text Search Engine 能提供高效且精準的文字查詢,而 ElasticSearch (ES) 是主流的 Full Text Search Engine 之一。
ES 底層的 Lucene 採用 Inverted Index 作為索引結構,將文章單字取出 (aka Tokenization),每個單字作為 Key 儲存在 Inverted Index,Value 為文章 ID 用於快速找出文章內容,例如 "I like dogs" 會取出 "I", "like" & "dog" 三個單字,Tokenization 過程不單只是取出單字,還會還原詞幹 (e.g dogs => dog) 跟移除 stop word (e.g a or the)。
假設 Inverted Index 是 HashMap 結構,就能以 O(1) 時間複雜度透過單字快速查詢文章內容,且不會有 dog 查到 hotdog 的問題!
假設有三個文章分別有 predict,prepare & prevent 單字,用 hashmap 實作 Inverted Index,Key 會儲存三個單字並重複儲存 pre 這個字段,若資料量不大重複儲存不是問題,但實務上如 FB 系統會有大量文章,且 Inverted Index 結構還要儲存在記憶體中,因此節省儲存空間變得非常重要!
使用 Trie 字典樹可將 common prefix 抽出來共同儲存,例如 predict,prepare & prevent 將 pre 獨立建立一個節點,pre 節點底下在建立 dict,pare & vent 三個子節點,以此形成樹狀結構。
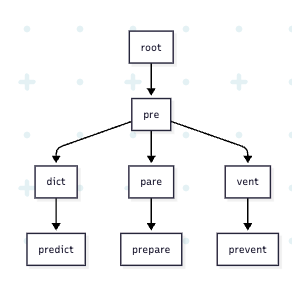
(作者產圖)
但 Trie 還不夠節省,因為只共用了 common prefix,很多英文單字還有 common suffix,例如 education & information,因此 Lucene 用 FST (Finite State Transducer) 結構,將 Trie 樹結構變成狀態機的 Graph 結構,例如 unreadable & unbelievable 會有相同的 un 節點,隨後 un 節點的下一個狀態可以是 read 或 believ 節點,最後統一到 able 狀態節點。
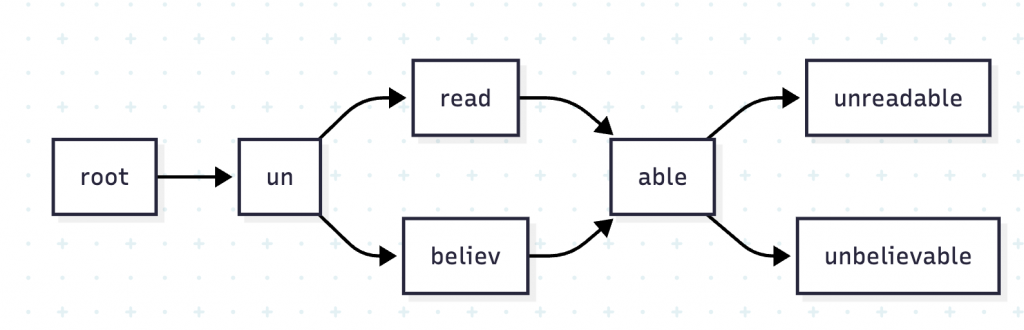
(作者產圖)
雖然 FST 能節省 Key 的儲存空間,但往 FST Graph 結構插入新單字,需要經過 Prefix & Suffix 比對跟 Traversal 整個 Graph,相較於 HashMap 平均 O(1) 的插入,FST 的插入時間為 Graph 的深度 (i.e 單字的長度),因此 Lucene 採用 Segment 分段儲存,插入資料先儲存在記憶體中,累積一定的量後整批存入硬碟,存入後不可修改,每個 Segment 有獨立的 Inverted Index 和對應的文檔資料。
Segment 分段好處是每插入時,只需維護一部分的 Inverted Index,新增單字進索引的時間較快,但缺點是查詢時要經過每個 Segment,Segment 數量多會增加隨機 I/O 次數,因此 ES 會定期 Merge Segment,將多個小 Segment 合併。
一個 Segment 有多個檔案,透過這些檔案組合出完整的 Full Text Search Engine 功能,首先是儲存文檔內容的檔案:
透過 fdt + fdx 就能用 document id 快速找出文檔內容。
而 FST 結構的 Inverted Index 儲存在:
整個查詢過程為:
社群網站的文章不僅要文字匹配,還需要在特定社團或者用戶底下搜尋,除了搜尋文章也要能搜尋文章底下的留言,因此查詢是多條件且資料關聯為多層結構的。
首先 ES 使用並行查詢 + 取交集的方式實現多條件查詢,例如 "apple" AND "dog" 查詢會分別查符合 "apple" 的 document ids 跟 "dog" 的 document ids,隨後使用 Leap Frog 算法取交集。由於 doc 檔案中 document ids 是有序的,可用 Leap Frog 算法的 two pointer 方式取交集,
if A pointer < B pointer A 往前,反之 B 往前,如果 A == B 則紀錄交集並繼續往前,Leap Frog 好處是不需要額外 HashMap 儲存,節省空間。
除了多條件查詢,ES 也支援多層結構儲存能加速查詢,例如用 Nested 結構儲存 (e.g { "user": "David", "posts": ["..", "..."] } ),Lucene 會自動將 Nested 結構攤平拆成多個 Document 放在相同硬碟區塊中並用隱藏的 field 關聯,查詢相同 parent 的 document 時能避免隨機 I/O,同時資料會一起被放進快取中也能提高快取命中率,但 Nested 結構無法單獨新增 post,需要先讀取整批資料後覆蓋,或建立相同的 user 但不同 posts 的 document。
除了 Nested 結構,也可直接建立一個 parent document 與多個 child document ,並在 child document 儲存 parent document id 建立一對多關聯,查詢時可用 has_parent 語法,例如查詢所有動物相關社團中跟貓有關的貼文,雖然 has_parent 查詢效能較差,但 parent & child 分開儲存空間使用率較高且可單獨新增 child,不需要每個 child 都額外儲存 parent document 的資訊。
實務上兩個策略可以混用,例如不常發文用戶用 Nested 結構儲存,提高查詢效率,但高頻發文用戶用 parent-child 建立關聯。

 iThome鐵人賽
iThome鐵人賽