
SUM, AVG, COUNT 等聚合語法用於多筆資料計算,如果財務要 SUM 一整年訂單的獲利,資料量大時,堪比 Full Table Scan,MySQL 或 PostgreSQL (PG) 可能執行了一個小時都沒有結果,且會佔用大量 CPU 影響其他功能。
因此有了 OLAP(Online Analytical Processing)專門設計來支援分析性查詢的資料庫系統,而 ClickHouse 就是知名的 OLAP DB 之一,而 MySQL & PG 則是 OLTP(Online Transaction Processing)用來處理併發 Transaction 的資料庫。
MySQL & PG 為 row-based 儲存,所有欄位儲存在同一個地方,例如 [id|price|amount, id|price|amount],聚合欄位 (e.g SUM(amount)) 時,若該欄位沒有 index,就需讀取資料所有欄位後再做計算,如果欄位和聚合筆數多,I/O 的量會很大,且大部分的欄位都用不到,使用效率很差。
ClickHouse 為 column-based 儲存,不同欄位儲存在不同地方,例如 [id,id] & [price,price] & [amount,amount],類似不同 column 儲存在不同陣列結構的 Table,SUM(amount) 時只讀 amount 資料,即便欄位多也不影響,I/O 量小很多,使用效率高!
此外 ClickHouse 插入一筆資料時,所有欄位一定會佔一個空間,即便該欄位為 NULL,這樣當每個欄位存在不同的陣列時,同一筆資料在不同陣列的 index 一定一樣,因此可透過 index 重組回一筆資料,Group By 並聚合多欄位時就不用擔心了!
雖然 I/O 量小,但 SUM 一百萬筆資料一筆筆加也要很久,因此 ClickHouse 使用 SIMD(Single Instruction Multiple Data)CPU 指令優化聚合計算。一般 CPU 處理指令時,會將資料跟指令從記憶體載入暫存器,再交由 ALU 元件處理,產生結果後寫回記憶體。
使用 SIMD 時 CPU 須具備向量暫存器與向量 ALU,與一般暫存器一次只儲存單一資料不同,向量暫存器是儲存一個向量,類似一個陣列,而向量 ALU 能處理向量的運算,例如同時將兩個向量中的所有對應的資料相加。
ClickHouse 在聚合運算中會將資料組成向量,在使用 SIMD 指令載入資料到向量暫存器並進行多向量 (e.g 8 個 amount 為一個向量)計算,這種平行計算方式大幅減少 CPU 指令數與時鐘週期。例如一般 CPU 指令 SUM 一百萬筆資料要執行一百萬次加法,若使用 SIMD 一次處理長度為 8 的向量,總體 CPU 執行次數可降低至原本的 1/8。
快速篩選資料需要 Binary Search 和有序結構,但 ClickHouse 用陣列結構儲存資料,每次插入要維持陣列有序代價很高,要花 LogN 時間查詢插入位置,還要搬移後面所有資料,因此 ClickHouse 使用 MergeTree 結構,插入資料先放在記憶體累計一定的量後,排序並整批插入硬碟,硬碟插入結構為 part,每次硬碟插入都產生新的 part,MergeTree 保證 part 裡資料是有序的,但跨 part 的資料非有序。
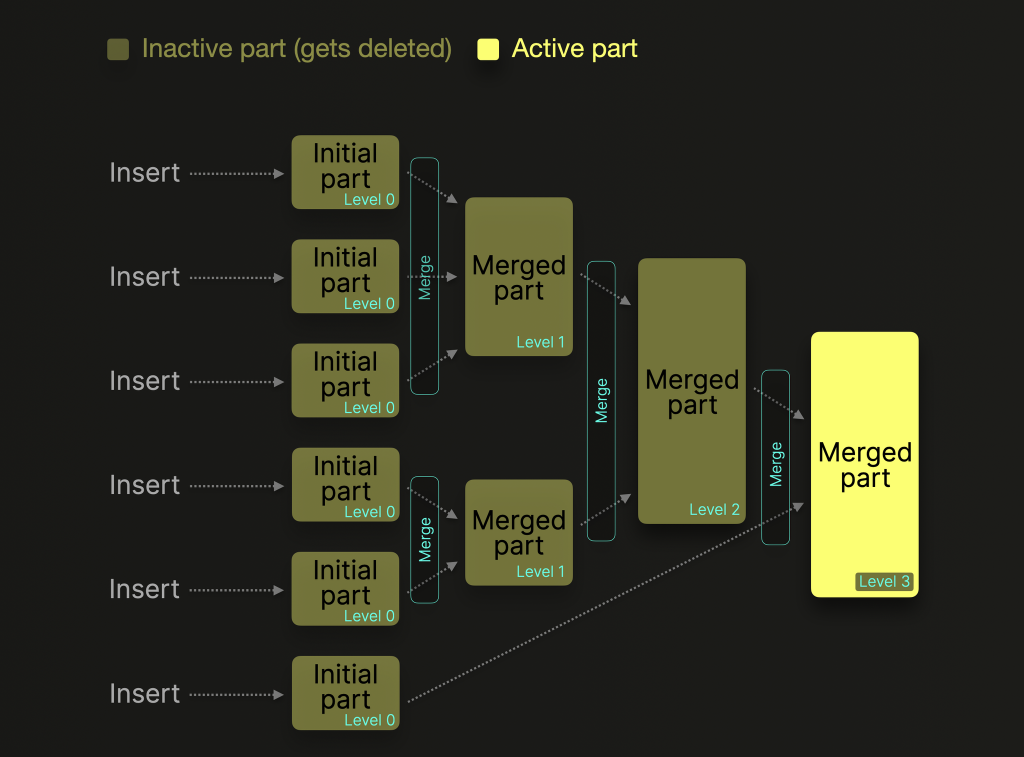
(圖來源;https://clickhouse.com/docs/merges)
part 跟 Cassandra SSTable 類似,也會定期把多個 part merge 起來,而 一個 part 由多個 bin 檔和 mark 檔組成,每個欄位會有各自的 bin & mark:
MergeTree 的好處是記憶體排序比硬碟排序效率高,且一次只需排序並移動少量資料,不需要排序並移動所有資料,ClickHouse 會在 background 定期 Merge 多個 part 為一個有序的 part,減少查詢時的跨 part 掃描次數。
MySQL 與 PG 索引設計是為了精確定位資料位置,因此每筆資料通常都有對應的索引。而 ClickHouse 的索引目的是為了跳過不相關的資料區段,找到正確區段做聚合,因此採用稀疏索引,一段資料對應一筆索引。
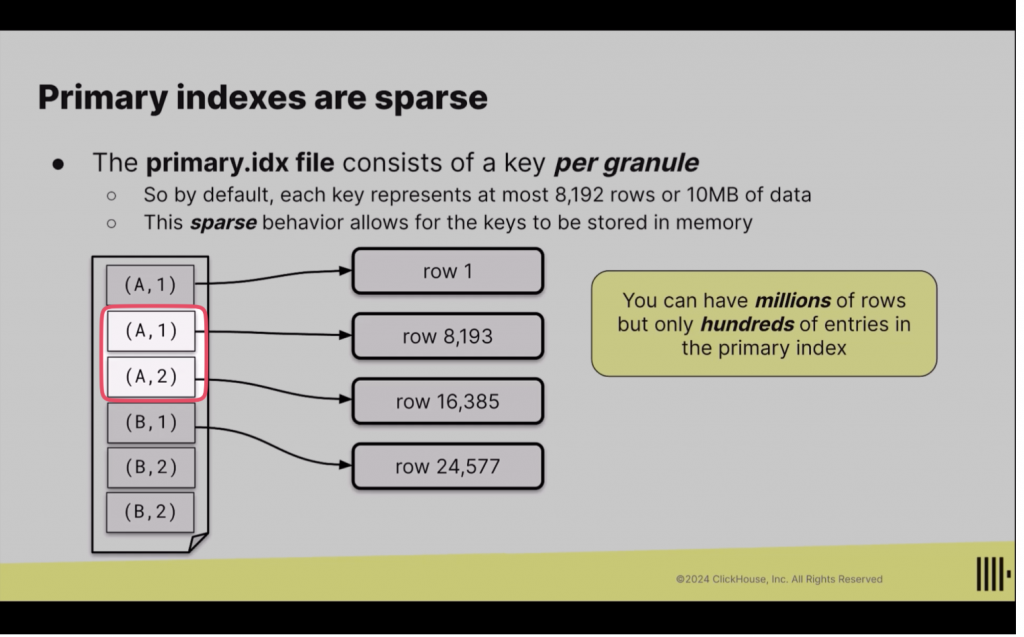
(圖來源:https://pjchender.dev/database/database-clickhouse-getting-started/)
例如 Primary Key Index 紀錄不同區段的陣列起始 index,像是紀錄 pk=100 起始位置為 70 和 pk=150 為 90,查詢 pk BETWEEN 120 AND 140 資料,就會從陣列 index 70 位置往後查詢。
索引可以設定 granule 值,代表多少筆資料為一個區段,預設為 8192 rows,Primary Key Index 在 part 中為 primary.idx 檔案,可用 primary.idx 中的陣列 index 去不同欄位的 mark 檔找出 file offset 後過濾 bin 檔中的資料。
bin 檔資料只照 primary key 排序,非 primary key 欄位因為欄位順序不等於陣列順序,無法建立稀疏索引去執行 Binary Search,若要額外建立依照其他欄位排序的資料陣列,資料量會變大也會影響插入效能,因此 ClickHouse 提供多種的 Skip Index ,用於判斷是否可跳過該區段,而不是進行 Binary Search。
追到最新版了
總共會有幾篇啊
感謝大大支持,還剩下 elasticsearch & redis & vector db 各一篇,跟最後一篇大總結!
大大覺得這個系列對你有幫助嗎?有學到新東西嗎?
以上是我最有感的內容
希望你可以拿到冠軍

 iThome鐵人賽
iThome鐵人賽