在設計複雜的 AI 系統或對話代理時,上下文容量是個需要考量的問題,因為即便我們精心設計了即時、持久、外部三層上下文架構,依然受限於上下文視窗 (context window) 的大小。所以我們在設計上下文架構時,要思考如何在這樣的限制下,精準選擇最關鍵的資訊
我們會從以下三個面向來討論介紹:
模型在單次請求中所能處理的上下文,包含了我們輸入的提示詞、附加的背景資料,以及模型自身要生成的回覆。這些內容加起來後的總和,被限制在一個最大的 token 數量內,一旦超過這個上限,系統便可能觸發截斷或是遺忘最早的資訊,甚至直接回報錯誤。
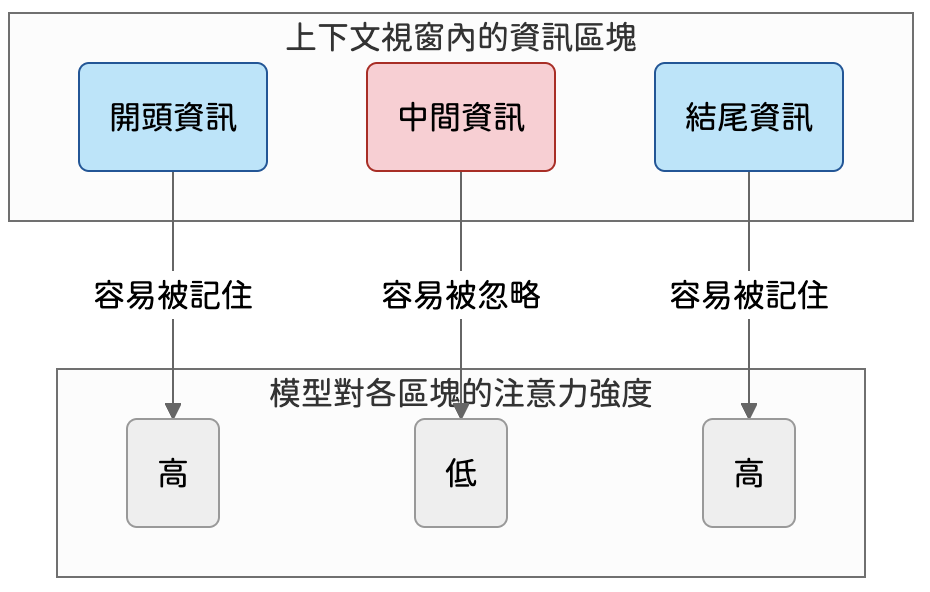
而 Token 的限制也會帶來一些實務上的不便,例如長上下文的內容,模型很容易遺忘中間的部分。這就像我們在聽一場長篇演講時,最容易記住開頭的引言和結尾的結論,中間的細節則相對模糊。同樣的道理,模型在解碼過程中的注意力偏差,使得位於提示詞開頭與結尾的內容,更容易被看見。
另外,上下文如果愈長,處理所需的運算資源與時間延遲也愈高。即使模型支援極大的上下文視窗,例如有百萬 token 的 Gemini 模型,在每次互動中都用滿也未必符合成本效益。這也是為什麼許多研究致力於壓縮提示詞或優化 token,目標是在不犧牲品質的前提下,用最少的 token 完成任務。
正因為上下文不是愈多愈好,所以千萬記得不要為了省 token 而將多筆資料或多個任務一次性的放入上下文中,這樣可能導致不同個案之間的資訊相互干擾
面對容量限制,我們必須學會取捨。關鍵不在於提供最多的資訊,而在於提供最對的資訊,與其直接將長篇大論的原始文件塞入,不如先進行預處理。可以先將冗長文本進行摘要,建立一個濃縮版本;或是直接抽取其中的關鍵句、專有名詞、或結構化數據
再來要能區分高價值與低價值的資訊,例如在做一個競品分析的上下文時,「競品近三個月的官方新聞稿重點」與「使用者在社群媒體上的負面評論摘要」應該比「五年前的品牌宣傳文案」更具高價值。
高價值的資訊,指的是對當前任務有直接幫助的資料、記憶或相關的搜尋結果,但要放到上下文中,還要再做一次關聯性的篩選,選擇分數最高、最相關的 N 個片段,因為過多的片段反而會造成干擾;低價值則是重複的內容、不重要的年份資訊,或是沒有實質幫助的註釋 ... 等。
最後就是反覆提到的結構化格式,如 Markdown、JSON、YAML,使用這些格式會優於長篇敘述文,因為模型更能精準的理解欄位與值的關係
為了讓有限的上下文空間發揮最大功能,我們可以設計一套動態的優先級排序機制與資訊壓縮的策略。例如替不同來源的上下文元素,建立一套重要性的分級標準,當空間不足時,就先捨棄優先級最低的內容,以下分級標準,數字愈小的愈重要:
除了做優先級的排序外,我們也可以用設計過的壓縮方法,把大段的內容轉換為更精煉簡潔的摘要,確保有限的上下文空間能發揮最大效,以下是幾種常見的壓縮方式:
把以下 1000 字文本濃縮成 200 字精華摘要,保留最重要的三個觀點。
``
以下分享幾個實用的提示詞設計範例,主要分享如何在上下文容量受限時,可以使用上述的方式做調整
背景:系統從知識庫中搜尋了五篇相關的市場分析報告原文
# 背景資料
[貼上數段搜尋到的原文]
# 任務指令
請嚴格遵照下面兩個步驟:
步驟 1:將上述五篇背景資料,分別濃縮成一段不超過 50 字的關鍵句摘要。
步驟 2:根據你在步驟 1 產出的五句關鍵句摘要,撰寫一篇 300 字的回答,該回答需明確指出這些資料對於「未來市場機會」的三點核心啟示。
背景:提供多段按相關性排序的背景資料。
# 背景資料
[貼上五段按相關性排序的資料,第一段最相關,第五段次之]
# 任務指令
請基於這五段資料撰寫一篇 400 字的分析報告。
在撰寫過程中,請確保報告內容至少要包含第一段與第五段的資訊。如果空間不足,你可以選擇性地刪除第二、三、四段中最不相關的段落,然後再重新組織你的分析。
背景:系統整合了來自不同層級的資訊
# 資訊清單
- 持久記憶摘要:使用者是一位金融分析師,偏好簡潔、數據驅動的報告風格,先前曾多次詢問關於區塊鏈技術的應用
- 即時對話上下文:使用者剛剛提問:「請幫我分析一下 XYZ 公司的潛力。」
- 外部檢索資料:[此處貼上三篇關於 XYZ 公司最新的財經新聞段落]
# 任務指令
請整合以上三種資訊,為這位使用者生成一段 250 字的專業分析報告。報告中若引用外部檢索資料,請用括號標註來源。如果預期輸出會超過 token 上限,你可以優先濃縮「外部檢索資料」的內容。
Token 的限制是每個模型不可違背的規則,所以我們要學會取捨,判斷哪些內容要保留、哪些要捨棄。這篇文章跟大家分享可以結合摘要、壓縮與優先級排序等方法,讓我們在有限的 context window 中確保模型總是能看到最有用的資訊。
以上有任何問題,歡迎留言討論


 iThome鐵人賽
iThome鐵人賽