在前一篇文章上下文工程在多模態 AI 的應用中,提到的重點是如何為多模態模型建立一個穩定、結構化的工程藍圖。並介紹如何透過層級化設計、模態權重與顯式標記等方法,來確保圖片、文字、聲音等不同來源的資訊能夠相互協作。
但這只是解決了輸入層面的問題,我們可以保證 AI 在執行任務時不會出錯,卻無法保證 AI 可以 100% 理解我們的內容,大家有想過這個問題嗎?即使模型能辨識出獨立的物件、聽清楚詞彙,但他是否真正看懂這些元素組合起來的情境與意圖?
這正是多模態面臨的問題之一,辨識相對容易,但理解極為困難
所以我們可以用上下文工程將不同的模態資料拼湊在一起,並設計一個能讓模型對齊語義的環境,讓模型了解圖片、文字、影片 ... 並非獨立的資料來源,而是同一件事物的不同面向
我們時常誤以為能夠描述圖片、生成配音的多模態 AI,已經具備了人類般的理解能力。但實際上,這些能力的本質大多仍停留在分模態生成的階段,也就是讓視覺模型處理視覺、語言模型處理語言,缺點是少了跨模態的深層意圖連結
假設我們今天上傳了一個穿著白袍的人的照片,並提問:「他正在做什麼?」
此時 AI 模型可能會回答:「他是一位醫生,正在為病人看診。」
正常邏輯下,穿白袍的可能是醫生,所以這個回答在辨識上是準確的。但如果這張照片的背景是一個攝影棚,那麼這個答案在理解上就完全錯了。這個問題是因為模型看對了物件,卻理解錯了情境
這種現象被稱為語義錯位。它源於模型缺乏一個能整合所有模態、形成整體世界觀的統一語境
語義對齊的核心概念是讓不同模態的資料,在模型的內部表徵中共享同一個語意空間
舉例來說,文字中的紅色這個詞彙,與圖片中的一片紅色像素區域,對人類而言是完全等價的概念。但對 AI 而言,它們原本分屬於兩個截然不同的資料領域:一個是 token,另一個是 pixel。
要讓模型真正理解紅色就是紅色,就必須透過訓練,讓代表這兩種不同來源的向量在同一個高維語義空間中彼此靠近。
現代的多模態模型,如 CLIP、BLIP、ALIGN、Flamingo 及 Gemini 系列,大多是透過對比學習來做到。簡單來說,模型在訓練過程中會學習到「當我看到這片像素分佈時,我應該將它與這段文字描述聯繫起來。」,這個過程也讓模型具備了在圖像和文字之間互相翻譯語義的能力
語義錨點是將抽象的非文字模態轉譯回語言,來鞏固模型的理解,當 AI 觀看圖片或聆聽聲音時,如果能立刻用語言為其命名或描述,它就能在後續的複雜推理中,牢牢抓住這條語義連結
聲音 → 轉譯為 → 金屬摩擦聲
圖像 → 轉譯為 → 玻璃窗上的雨滴
影片片段 → 轉譯為 → 人物走進昏暗房間的過程
這些文字描述就是語義索引,他讓模型在後續的資訊檢索或推理過程中,能夠以語言作為核心,串接起不同模態的事件片段。
我們可以設計一個提示,引導模型主動建立這種語義地圖:
你是一位專業的影片分析師。你將會收到一段影片及相關的文字描述,請幫我建立一個語義錨點表
輸出格式必須為 JSON 陣列,格式如下:
JSON
[
{
"scene": "開場",
"image_anchor": "辦公室內景,光線明亮",
"audio_anchor": "輕快的背景鍵盤敲擊聲",
"text_anchor": "主持人的開場歡迎詞"
},
{
"scene": "結尾",
"image_anchor": "產品 LOGO 動畫展示",
"audio_anchor": "品牌主題音樂逐漸減弱",
"text_anchor": "主持人的感謝與行動呼籲"
}
]
這樣的結構化輸出可以讓模型進行對齊語義地圖的工作。後續無論是進行問答、搜尋還是內容生成,模型都能夠準確的知道哪一段模態對應哪一個語義
根據我們在多模態系統的實作經驗,可以將語義對齊的策略,由淺入深分為三個層次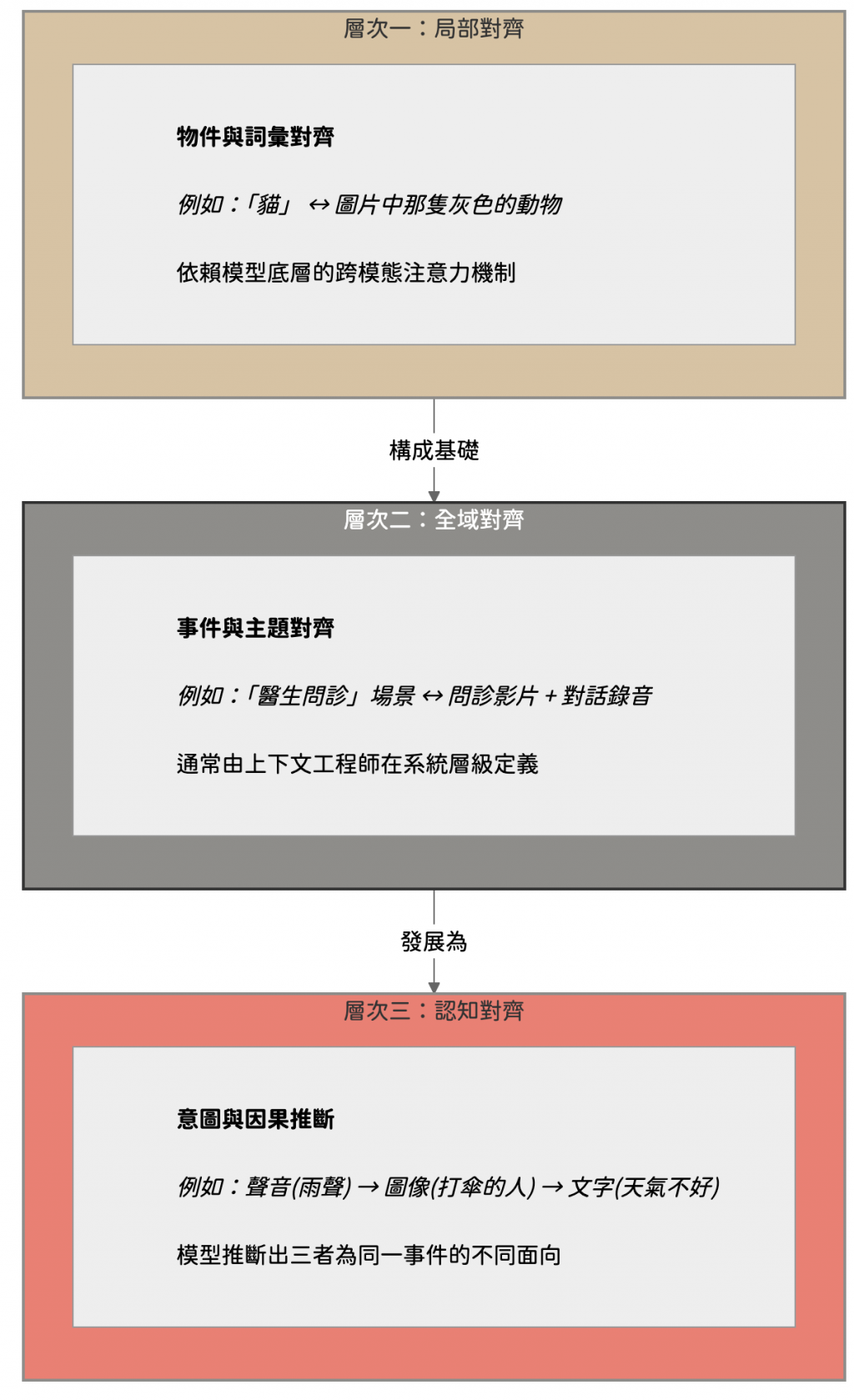
局部對齊可以讓模型知道圖片中的這個物件要對應到文字裡的那個詞彙
例如,將圖片中一隻灰色動物的像素區域與文字中的貓這個詞彙建立連結,這通常依賴模型底層的跨模態注意力機制自動完成
全域要求不同模態的資料,能夠共享事件或主題層級的語義。例如,模型需要理解一段問診場景的影片和一段醫病對話的錄音,共同指向醫生與病人對話這個核心事件
這一層的對齊往往無法單靠模型自動完成,而是上下文工程師最需要透過結構化設計 (例如使用相同的 scene_id) 來人工介入
認知對齊是最厲害的對齊,他讓模型能夠跨越模態的邊界,去理解抽象的意圖或因果關係
假設現在模型接收到三個獨立的資訊:下雨的聲音、行人撐傘的圖片、以及今天天氣不好的文字,認知對齊就能讓模型推理出這三個並非獨立的事件,而是同一情境下的不同觀點
這需要模型在語義空間中具備強大的抽象連結與推理能力,而上下文設計的角色,就是提供足夠的結構與約束,來引導模型形成這種高階推理
我們在實際應用上,最大的問題就是記憶長度與同步對齊
這又要回到模型那個不可撼動的限制:Token。通常影片、高解析度圖片與長音訊,若直接轉換會佔用巨額的 Token,遠超出現有模型的上下文視窗限制。我們可以採用分層處理的方式,先讓模型為每一小段模態生成精簡的語義摘要,再將這些摘要的摘要整合成一個全局記憶,這樣就能在有限的 Token 內保留核心的語義脈絡,也能處理超長的時間序列資料。
另外,不同模態的時間軸不一定能完美對齊,比如背景音樂可能比對應的畫面更早或更晚出現,所以我們可以建立時間錨點,就是在處理資料時,給每個模態片段打上精確的時間戳,並與語義連結。
[t=00:12] 圖像:人物微笑
[t=00:12] 音訊:輕快音樂響起
[t=00:13] 文字:字幕『開始介紹新產品』
我們的目標,不是訓練出一個圖像模型 + 語音模型 + 文字模型的組合體,我們需要的一直都是可以理解語義的整合式 AI,讓他們理解我們人類複雜意圖與真正的認知
這意味著,我們的挑戰不僅在於提升模型效能,而在於設計出能對齊語境、推理過程與人類心智的架構


 iThome鐵人賽
iThome鐵人賽