隨著 GPT、Gemini 與 Claude 等強大多模態模型的普及,AI 已經從一個單純的文字處理系統,進化為能夠同時看圖、聽聲、理解影片的智慧代理。這項進化帶來了前所未有的機會,也引出了一個核心挑戰:當不同模態的資訊同時存在於上下文中,我們該如何設計互動模式,才能讓模型看懂整體,而不搞混部分?
在傳統的提示工程中,我們操作的上下文幾乎全是文字。但在多模態系統中,上下文的概念已擴展成一個複雜的資料流,而在這個資料流中,我們可能同時輸入一張產品圖片、一段簡報文案、一段主持人的講稿音訊,甚至還包含從外部 API 獲取的結構化數據。
模型的任務是將這些資訊建立連結、推斷潛在意圖,最終生成準確的回應
以下舉一個實際的例子:
請根據這張包裝圖和商品說明,幫我寫一句符合品牌精神的廣告文案
這個指令的背後,上下文其實隱含了三個層次的資訊:
模型除了要了解圖片的內容,還要理解整個任務的語境,我們要確保模型能正確理解每個資訊片段的角色與其彼此之間的關聯
在設計多模態上下文時,最常見的錯誤是將所有資訊平鋪直敘地丟給模型。例如,直接把圖片描述、產品文案、音訊轉錄稿逐段串接起來。這種做法會導致幾個嚴重問題:
為了解決這個問題,我們可以採用層級化的上下文設計,將不同類型的資訊放置在結構清晰的區塊中。這就像是為 AI 提供一份附有章節與標題的報告,而不是一堆未經整理的筆記:
[System]
// 在此定義模型的角色、整體任務邊界與基本原則
// 例如:你是一位專業的產品文案專家
[Context]
// 提供背景資訊,摘要說明各個模態資料的來源與用途
// 例如:以下是關於一款新上市飲料的相關資料
[Modal Inputs]
// 將不同模態的資料明確標示並分開呈現
- Image: [商品包裝照片]
- Text: [產品描述文字]
- Audio: [廣告配音樣本的轉錄稿]
[Instruction]
// 提出具體、清晰的任務指令與輸出格式要求
// 例如:請撰寫一句 15 字以內的廣告標語,風格需活潑有趣
這種結構化的設計,能讓模型清楚辨識各資訊的邊界與層級,從而避免不同模態的資訊在解讀時互相干擾
多模態模型最強大的能力在於跨模態推理,但這也正是最容易出錯的地方。如果上下文設計不當,不同模態的資訊就可能從協作者變成競爭者,以下是常見的干擾情境:
此時,我們可以設定權重或標記來解決這個問題
在系統提示詞中,明確設定不同模態的優先層級,指導模型在面對資訊衝突時的決策路徑,例如以下兩個範例:
範例 A:以文字為準
[System]
在所有提供的資訊中,請以 [Text Context] 的文字描述為主要依據,圖像僅作為視覺風格的輔助參考
範例 B:以圖像為準
[System]
若圖片內容與文字描述不一致,請優先採信圖片中呈現的視覺資訊
這種方式能有效避免模型在處理衝突時陷入隨機選擇的困境,讓其行為更具可預測性
第二種是使用明確的標籤將不同模態的上下文清楚地區隔開來,並引導模型進行比較或分析:
範例:分析差異
[Image Context]: 圖片中展示的是一個綠色玻璃瓶,瓶身標有「MUKI SPACE*」字樣
[Text Context]: 商品官方說明提到,此產品為「草本能量飲,採用藍色鋁罐包裝」。
[Task]: 請根據以上資訊,明確指出圖片與文字描述之間的差異之處。
讓我們以一個常見的應用場景來展示多模態上下文工程的完整流程
假設我們要開發一個功能,讓使用者可以上傳商品圖片,並提問:這支牙膏和我昨天拍的那支有什麼不同
這個看似簡單的問題,背後需要一個縝密的工程流程來支撐。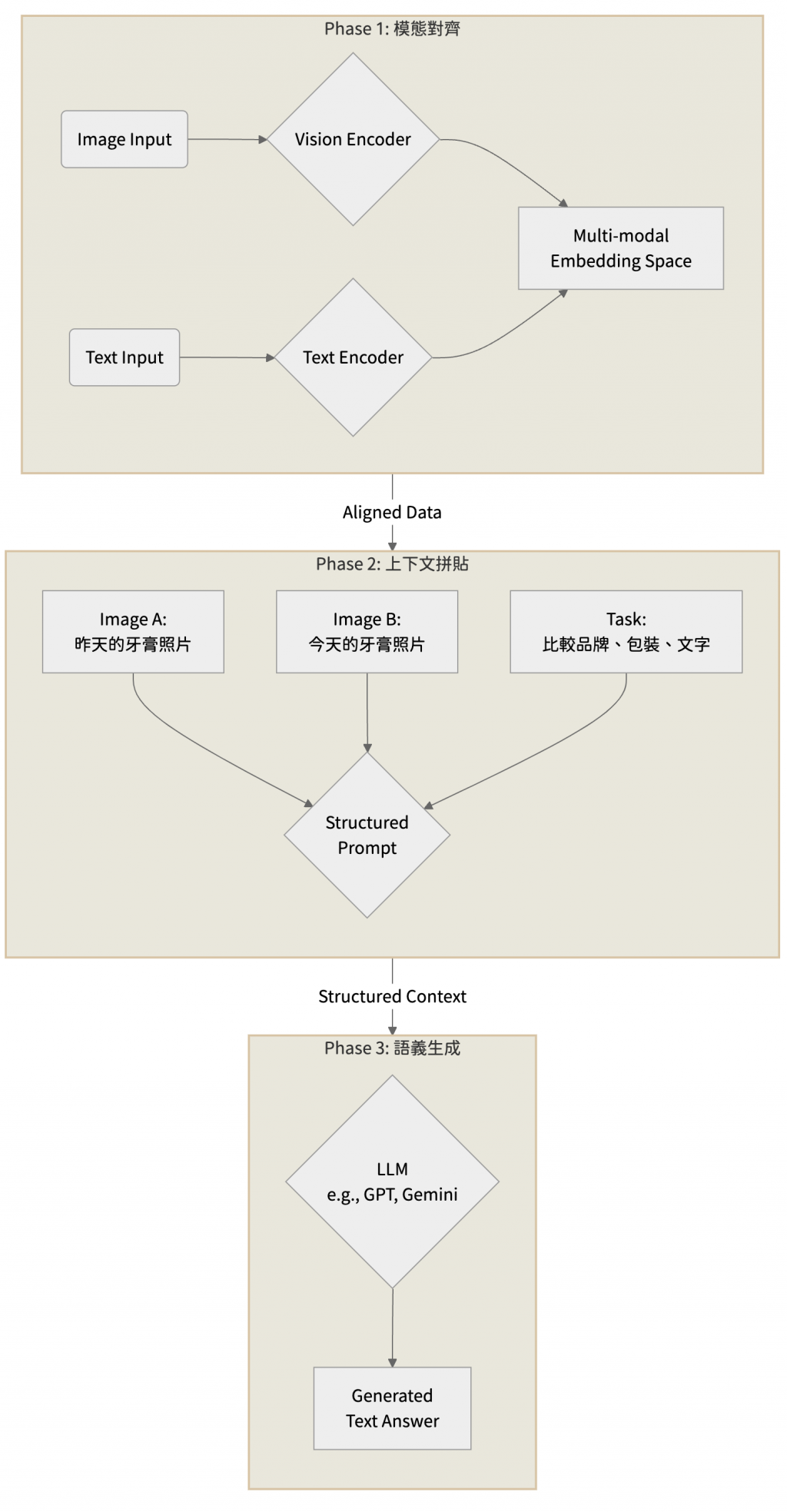
模態對齊的目標是將不同模態的原始資料轉換為 AI 能夠理解的向量,並將它們映射到同一個語義空間中。
建立一個結構化的提示,將對齊後的資料與明確的任務指令組合起來:
[Image A]: [昨天的牙膏照片向量]
[Image B]: [今天上傳的牙膏照片向量]
[Task]: 請詳細比較這兩張圖片中牙膏的品牌、包裝顏色、以及瓶身標示的文字差異。
最後,將這個結構化的上下文傳遞給生成模型。模型會基於這個上下文生成最終的文字回答,並確保其結論來自提供的視覺與文字內容
在多輪對話中,多模態的上下文管理變得更加複雜。使用者可能在對話的不同階段提供不同模態的資訊。
如果沒有一個良好的記憶機制,模型很容易混淆哪張圖對應哪段文字,我們可以給歷史對話建立一個索引,當使用者進行新的對話或問題時,模型就能根據這些索引檢索到相對應的歷史上下文,確保對話的連貫性
| 索引 (Index) | 類型 (Type) | 內容摘要 (Summary) | 唯一識別碼 (Link ID) |
|---|---|---|---|
| 1 | image |
牙膏圖片 (白色包裝) | img_a |
| 2 | text |
商品描述 (Herbal Fresh 藍色) | txt_b |
| 3 | query |
這兩者是同一款產品嗎? | q_c |
以上有任何問題,都歡迎留言討論


 iThome鐵人賽
iThome鐵人賽