 在做語音辨識、音樂分類、甚至情感計算(Affective Computing)的時候,「音訊特徵」是核心。
在做語音辨識、音樂分類、甚至情感計算(Affective Computing)的時候,「音訊特徵」是核心。
光有一段 .wav 聲音檔,電腦其實「聽不懂」,我們需要把聲音轉換成數字特徵,再交給模型去學習。
今天就用 Python 的 Librosa 套件,帶大家實作一個最經典的特徵:MFCC 梅爾頻率倒譜係數。
模仿人耳聽覺機制:MFCC 把頻率轉換到「梅爾刻度」(Mel scale),更接近人耳對音高的感知。
語音 & 音樂通吃:Google 語音辨識、Shazam 音樂比對,背後都有 MFCC 的影子。
低維卻有效:一般取前 13 維 MFCC,就足以代表一段聲音的 timbre(音色特徵)。
在 Python 3.9+ 都能用,請先安裝這幾個套件:
pip install librosa matplotlib soundfile
librosa:音訊處理核心
matplotlib:視覺化
soundfile:讀寫 .wav 音檔
這個程式會:
嘗試讀入 sample_audio.wav
如果檔案不存在,就自動生成一段 440Hz 測試音
萃取 13 維 MFCC 視覺化結果
import os
import numpy as np
import librosa
import librosa.display
import soundfile as sf
import matplotlib.pyplot as plt
# --- 檔案設定 ---
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(BASE_DIR, "sample_audio.wav")
sr = 16000 # 常見語音取樣率
# --- 若檔案不存在,自動產生一段 3 秒測試音 ---
if not os.path.exists(file_path):
print("[提示] 找不到 sample_audio.wav,將自動產生 3 秒 440Hz 測試音。")
duration = 3.0
t = np.linspace(0, duration, int(sr * duration), endpoint=False)
y = 0.2 * np.sin(2 * np.pi * 440 * t) * np.exp(-t/3.0) # 衰減避免太刺耳
sf.write(file_path, y, sr)
# --- 讀檔 ---
y, sr = librosa.load(file_path, sr=sr)
print(f"訊號長度: {len(y)}, 取樣率: {sr}")
# --- 萃取 13 維 MFCC ---
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
print("MFCC 形狀:", mfccs.shape) # (13, time_frames)
# --- 視覺化 ---
plt.figure(figsize=(10, 4))
librosa.display.specshow(mfccs, x_axis='time')
plt.colorbar()
plt.title("MFCC 特徵 (13 維)")
plt.tight_layout()
plt.show()
執行結果
終端機輸出
MFCC 形狀: (13, 94)
代表我們取到了 13 維 MFCC,時間軸上有 94 個 frame。
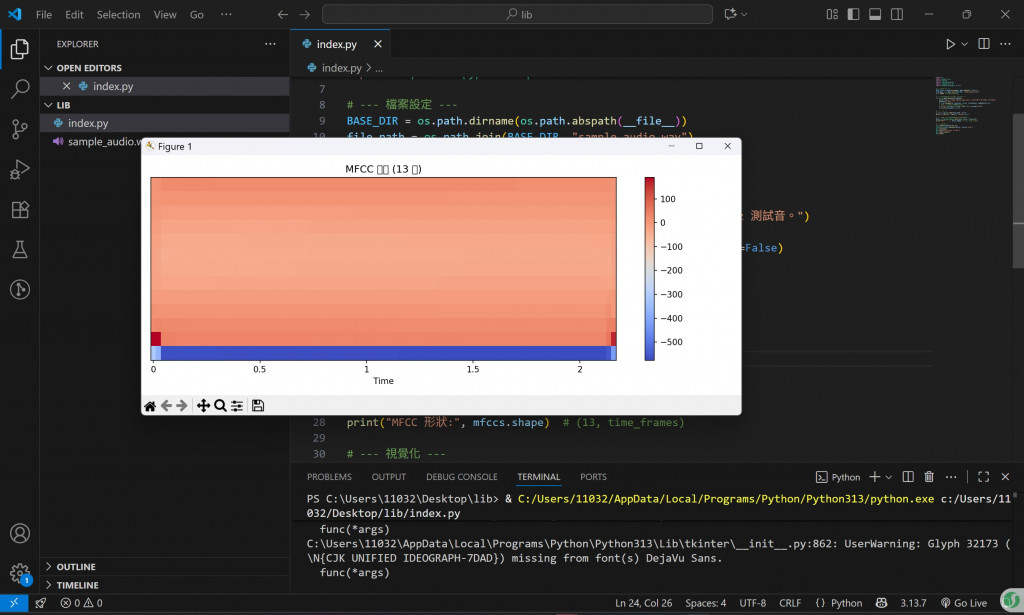
視覺化圖
一張橫軸是時間、縱軸是 MFCC 維度的「熱度圖」。不同顏色代表特徵值大小,這就是可以送進機器學習 / 深度學習模型的輸入。
語音情緒辨識:搭配 RNN / CNN,把開心、生氣、悲傷訓練出來。
音樂風格分類:用 MFCC + RandomForest 區分搖滾、古典、爵士。
動態互動:把聲音強度、特徵對應到 TouchDesigner / Processing,做成互動裝置。
聲音必須轉成特徵,電腦才能理解。Librosa 幫我們把這件事變得簡單。從 wav 到 MFCC,只要幾行程式碼,就能開始探索聲音背後的數據世界。下一步,我們可以試試錄自己的聲音,跑 MFCC,看看不同情緒的聲音,圖像特徵有什麼差異!


 iThome鐵人賽
iThome鐵人賽