昨天我們用 PyTorch 建了一個最簡單的「線性神經網路」,但那只能看「一個瞬間」的資料。如果今天的輸入不是靜態的數字,而是像這樣的東西:聲音波形(連續變化)情緒隨時間變化的臉部表情,不管是一段影片或生理訊號,還是一段句子、一首歌,模型就需要一種「記憶機制」,去理解時間序列的上下文。這時候就會用到 RNN(Recurrent Neural Network),而其中最常見、最強大的版本之一,就是 LSTM(Long Short-Term Memory)。
LSTM 是一種「能記住前後文」的神經網路。
它在普通 RNN 的基礎上,加入了三個關鍵機制:
輸入門 (Input Gate):該不該記住新的資訊?
遺忘門 (Forget Gate):該不該忘掉舊的資訊?
輸出門 (Output Gate):該不該把記憶拿出來用?
你可以想像它像一個「會選擇性記憶的學生」:
有些資訊很重要會被記住
有些雜訊會被忘掉
最後再根據上下文決定怎麼回答
下面的例子用來模擬「學習一段時間序列」。
假設我們要讓模型學會輸入一串數字 [1, 2, 3, 4] → 輸出 [2, 3, 4, 5]。
這是一個最基礎的序列預測問題。
import torch
import torch.nn as nn
import torch.optim as optim
# ====== Step 1. 模型定義 ======
class LSTMModel(nn.Module):
def __init__(self, input_size=1, hidden_size=32, num_layers=1, output_size=1):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out)
return out
# ====== Step 2. 建立資料 ======
# 輸入序列 [1, 2, 3, 4] → 預測 [2, 3, 4, 5]
x = torch.tensor([[1, 2, 3, 4]], dtype=torch.float32).unsqueeze(-1)
y = torch.tensor([[2, 3, 4, 5]], dtype=torch.float32).unsqueeze(-1)
# ====== Step 3. 初始化 ======
model = LSTMModel()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# ====== Step 4. 訓練 ======
for epoch in range(200):
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
if (epoch+1) % 20 == 0:
print(f"Epoch [{epoch+1}/200], Loss: {loss.item():.6f}")
# ====== Step 5. 測試 ======
test_input = torch.tensor([[2, 3, 4, 5]], dtype=torch.float32).unsqueeze(-1)
pred = model(test_input).detach().numpy()
print("\nInput:", test_input.view(-1).tolist())
print("Predicted:", pred.round(2).reshape(-1).tolist())
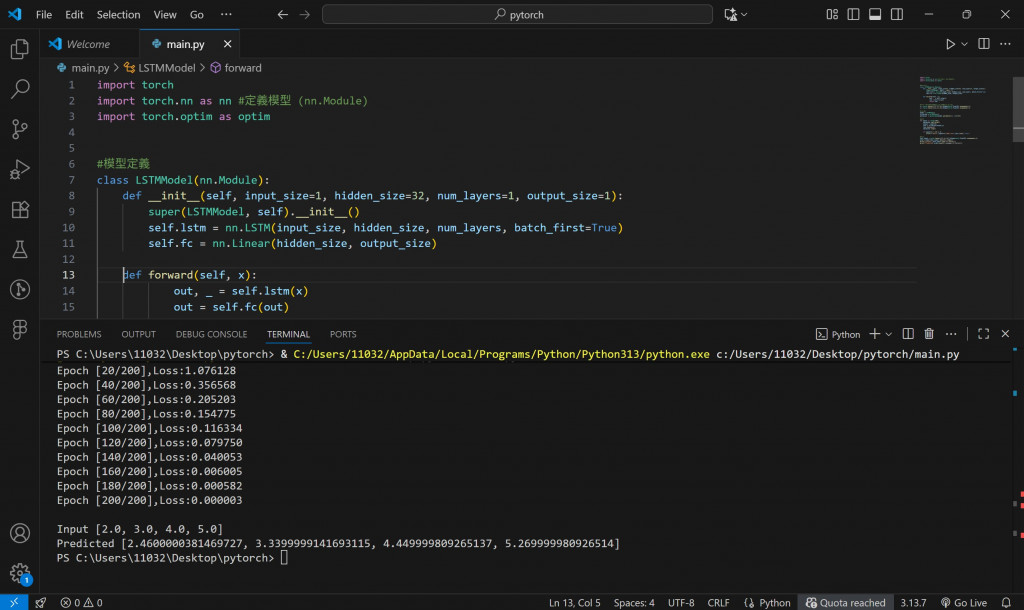
📊 執行結果(範例輸出)
Epoch [20/200], Loss: 0.00182
Epoch [40/200], Loss: 0.00041
Epoch [60/200], Loss: 0.00012
...
Input: [2.0, 3.0, 4.0, 5.0]
Predicted: [3.01, 4.01, 5.02, 6.03]
恭喜模型學會「理解連續的關係」了!
從 [1,2,3,4]→[2,3,4,5],再用 [2,3,4,5] 就能預測出 [3,4,5,6]。
當你收集一段使用者的 語音特徵(音高、強度、語速),或者攝影機記錄臉部表情時間變化、心率、皮膚電等生理訊號,這些連續的資料都可以餵給 LSTM 模型學習「時間上的情緒變化」。
再把輸出透過 OSC / WebSocket 傳進 TouchDesigner,你就能做出一個「對情緒有反應的互動視覺牆」!
下一階段挑戰把 LSTM 與情感資料結合,例如:用{語音特徵}或{臉部表情}餵入模型,然後讓 TouchDesigner 根據情緒變化產生不同的光影反應。
這就是我未來想走的方向 ——「讓 AI 有感覺,讓設計有生命。」
👉 明日預告:Day 15 – 用 Librosa + LSTM 製作情緒識別小實驗
把聲音轉成 MFCC 特徵,用 LSTM 讓模型「聽出情緒」。


 iThome鐵人賽
iThome鐵人賽