在軟體開發的世界裡,常常會聽到**「雜湊」、「編碼」**這些名詞。剛開始學習時,我也曾把它們和「加密」搞混在一起,結果越查越糊塗。
今天的文章,我會用最簡單的方式帶大家快速入門 Hash 與 Base62 編碼,並聊聊它們在實際應用中,為什麼會這麼重要。
雜湊(Hash),或稱為散列,是一種將任意大小的輸入資料轉換成一個固定大小的Hash Value雜湊值或Hash Code雜湊碼的過程,簡單來說就是把任意長度的資料轉換成固定長度的「指紋」。例如一個檔案、一串文字、或任何數據皆可以執行。
這個轉換過程是由一個特殊的演算法完成的,這個演算法就稱為雜湊函式(Hash Function)。
轉換流程大概會長這樣:
1.輸入 (Input/Key):任意長度的資料。
2.雜湊函式 (Hash Function):執行轉換的演算法(如 MD5, SHA-256)。
3.輸出 (Output/Hash Value):固定長度的字串或數字。
而且不論我們輸入一個單詞或一本小說,使用同一個雜湊函式,得到的雜湊值長度都會是固定的(例如 256 位元)。
一個設計良好的雜湊函式通常具備很多特性,今天我們先來講其中最重要的三種特性:
1.Determinism 確定性
概念:相同的輸入,永遠產生相同的雜湊值。
如果每次雜湊同一個密碼或檔案都得到不同的結果,我們就無法進行比對或驗證。
2.Pre-image Resistance 不可逆性
概念:雜湊過程是單向的,從最終的雜湊值,幾乎不可能反推出原始輸入資料。
系統可以比對我們輸入密碼的雜湊值,而不用擔心儲存的資料(雜湊值)洩露後會暴露原始密碼,這是密碼儲存的關鍵安全保障。
3.Collision Resistance 抗碰撞性
概念:找到兩個不同的輸入資料,但它們卻產生相同雜湊值的情況,是計算上幾乎不可能的事。
如果某人偷偷修改了一個檔案(不同的輸入),但卻能輕易找到一個與原檔案雜湊值相同的雜湊值,那麼雜湊就失去了驗證資料沒有被竄改的能力。
雜湊的應用非常廣泛,在資訊科學的世界中到處都能看到它的身影,像是:
我們使用 Python 內建的 hashlib 函式庫,示範最常用的 **SHA-256 **雜湊演算法。
import hashlib
def calculate_sha256_hash(data):
"""
計算輸入資料的 SHA-256 雜湊值
"""
sha256 = hashlib.sha256()
sha256.update(data.encode('utf-8'))
return sha256.hexdigest()
# 範例輸入
text_a = "Hello, Hash World!"
text_b = "Hello, Hash World!"
text_c = "Hello, hash World!" # 改變一個字母的大小寫
# 執行雜湊計算
hash_a = calculate_sha256_hash(text_a)
hash_b = calculate_sha256_hash(text_b)
hash_c = calculate_sha256_hash(text_c)
print(f"輸入 A: '{text_a}'")
print(f"雜湊 A: {hash_a}")
print("-" * 20)
print(f"輸入 B: '{text_b}'")
print(f"雜湊 B: {hash_b}")
print("結果:A 和 B 的雜湊值完全相同(確定性)")
print("-" * 20)
print(f"輸入 C: '{text_c}'")
print(f"雜湊 C: {hash_c}")
print("結果:僅改變一個字母,雜湊值卻完全不同(雪崩效應)")
print("-" * 20)
# 雜湊值長度(SHA-256 固定為 64 個 16 進位字元)
print(f"雜湊值長度: {len(hash_a)} 個字元")
執行結果: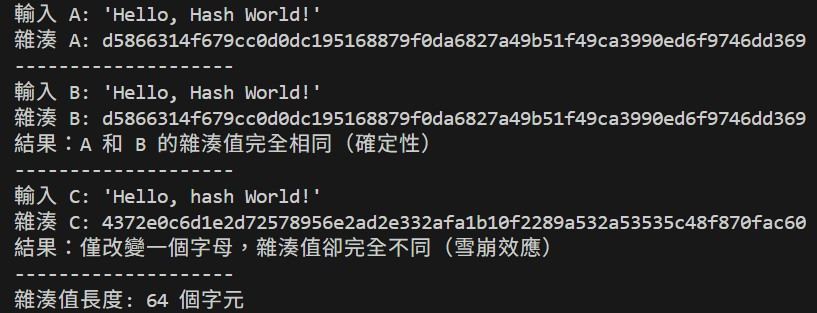
從結果中我們可以看到:
Base62 編碼是一種將數字或二進制資料轉換為由 62 個特定字元組成的字串表示形式的編碼方式,名稱由來是因為Base62 由 62 個字元所組成:
Base62 屬於編碼,而不是加密,以下是兩者的比較表格:
| 比較面向 | 編碼 (Encoding) | 加密 (Encryption) |
|---|---|---|
| 目的 | 確保資料能在不同系統中正確儲存與傳輸,例如 Base64、URL Encoding | 保護資料機密,確保只有授權者能解讀,例如 AES、RSA |
| 安全性 | 無安全性,只要知道規則就能還原 | 高安全性,必須持有密鑰才能解密 |
| 特性 | 可逆、效率高,重點在「資料正確傳遞」 | 可逆(需密鑰)、計算複雜,重點在「資料保密性」 |
提醒:Base62 只是將一個大數字或資料用更緊湊、URL-安全的字元集重新表示,它不具備任何保密或安全功能。
Base62 的主要優勢在於其**「URL 友好」和「緊湊性」**:
Base62 的 62 個字元都屬於標準的字母和數字,不包含像 Base64 常用的 +、/ 或補位符號 = 等特殊字元。這些特殊字元在 URL 傳輸中容易引起歧義或需要額外的 URL 編碼,Base62 則能完美避免此問題。
這是 Base62 最常見的應用。一個龐大的資料庫 ID(例如 64 位元的整數)透過 Base62 編碼後,可以轉換成一個更短且人類可讀的字串,從而大幅縮短網址長度。
Base62 雖然沒有 Base64 轉換效率高,但在將純數字 ID 轉換為字串時,能比十進位或十六進位佔用更少的字元空間。
Base62 的編碼原理與我們將十進位數字轉換為二進位、八進位或十六進位的原理完全相同,只不過這裡的基數是 62。
1.定義字元集
確定 62 個字元的順序,例如:"0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"。
2.將輸入資料轉換為Integer
如果輸入是文字或二進制資料,需要先轉換成一個可以被處理的大整數。
3.除法取餘
將該大整數不斷地除以 62 (基數),每次除法的餘數 (Remainder) 對應到字元集中的一個字元,最後將這些字元逆序組合起來,就是 Base62 的結果。
4.解碼流程
解碼是反向操作,將 Base62 字串視為一個 62 進位數。從左到右遍歷字串,將當前字元在字元集中的索引值,根據位置決定來乘以 62 的次方,然後累加得到原始的十進位數。
以下使用 Python 實作將一個整數 ID 進行 Base62 編碼與解碼:
import string
BASE62_ALPHABET = string.digits + string.ascii_lowercase + string.ascii_uppercase
BASE = len(BASE62_ALPHABET) # 基數為 62
def encode(num: int) -> str:
"""
將一個十進位整數編碼為 Base62 字串 (十進位轉六十二進位)
"""
if num == 0:
return BASE62_ALPHABET[0] # 處理 0 的特殊情況
encoded = []
while num > 0:
# num 除以 62,得到商 (num) 和餘數 (rem)
num, rem = divmod(num, BASE)
encoded.append(BASE62_ALPHABET[rem])
# 餘數是反向取出的,所以需要反轉字串
return "".join(reversed(encoded))
def decode(encoded_str: str) -> int:
"""
將 Base62 字串解碼回十進位整數 (六十二進位轉十進位)
"""
num = 0
# 建立字元到其索引值的對應 (用於加速查找)
char_map = {char: i for i, char in enumerate(BASE62_ALPHABET)}
# 從左到右遍歷 Base62 字串
for char in encoded_str:
# 原理: num = num * base + char_value
# 每次進位都乘以 62
char_value = char_map[char]
num = num * BASE + char_value
return num
original_id = 987654321012345 # 數據庫 ID
print(f"原始 ID: {original_id}")
# 1. 執行編碼
short_code = encode(original_id)
print(f"Base62 編碼結果: {short_code}")
print(f"長度從 {len(str(original_id))} 縮短為 {len(short_code)}")
# 2. 執行解碼
decoded_id = decode(short_code)
print(f"Base62 解碼結果: {decoded_id}")
# 3. 驗證結果
print(f"驗證是否還原成功: {original_id == decoded_id}")
執行結果: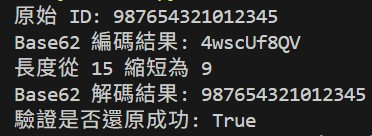
在短網址服務中,最核心的問題就是:如何把一個超長的 URL,轉換成短小且唯一的代碼?
這時候,我們可以結合 Hash 與 Base62 來達到目標,過程大致如下:
1.Hash 處理
先對長網址做 Hash,確保每個網址能對應出一個相對「唯一」的數值,例如使用 MD5、SHA-256 等演算法。
2.取部分數值
完整的 Hash 太長,我們只需要取一部分,避免過度冗長。
3.Base62 編碼
將數值再透過 Base62 轉換成短字串,這樣可以有效壓縮字串長度,並確保生成的短碼適合放進網址中。
4.資料庫映射
把這個短碼存進資料庫,對應到原始網址。使用者透過短網址存取時,就能快速找到對應的長網址並跳轉。
這其實就是第 25 天短網址小程式背後的原理延伸,只是多了 Hash → Base62 → 儲存/查詢 這一整套流程。


 iThome鐵人賽
iThome鐵人賽