做專案真的很容易一頭熱,往下鑽就忘了重新審視整體情況。
開始前,重新檢視一下目前進度。
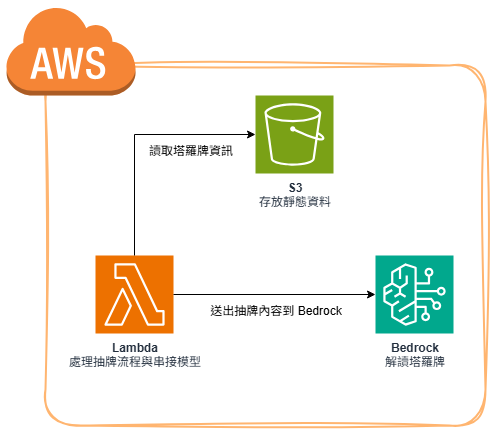
功能設計
目前已經完成了
✓ 從 S3 讀取塔羅牌資料
✓ 洗牌
✓ 串接 Bedrock
接下來要做的就是把每個完成的步驟串接起來,調整成需要的功能。
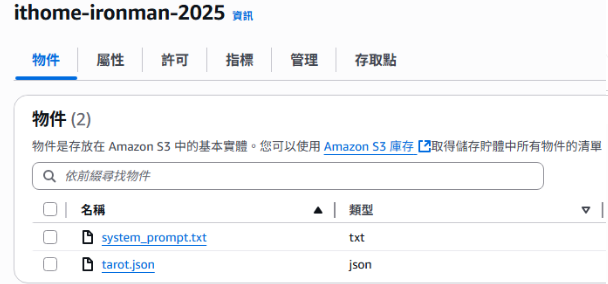
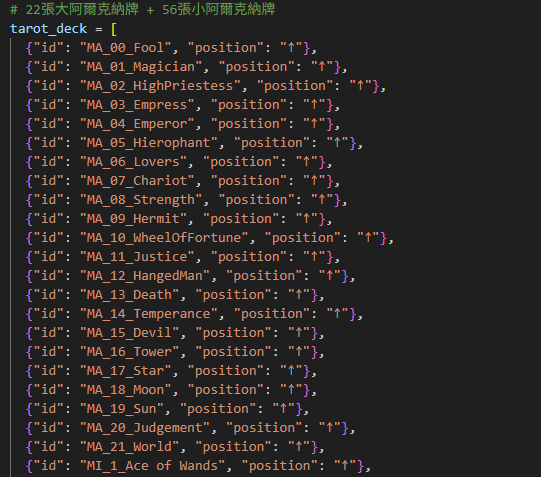
S3 中準備好了塔羅牌的文字檔(tarot.json),格式如下:
{
"id": "塔羅牌的ID",
"name_zh": "中文名稱",
"upright_meta": { "keywords": ["正位關鍵詞"] },
"reversed_meta": { "keywords": ["逆位關鍵詞"] },
"story": "牌面敘述及故事背景"
}
另外也準備了 system_prompt,用來設定占卜師的個性、解牌邏輯和對應語氣。
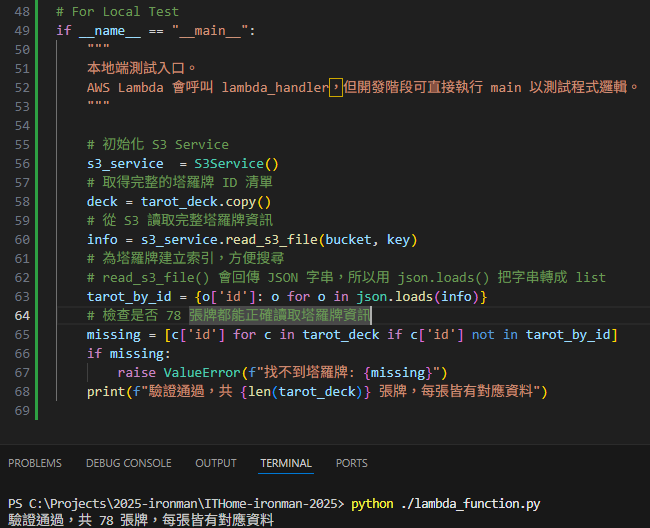
# For Local Test
if __name__ == "__main__":
"""
本地端測試入口。
AWS Lambda 會呼叫 lambda_handler,但開發階段可直接執行 main 以測試程式邏輯。
"""
# 初始化 S3 Service
s3_service = S3Service()
# 取得完整的塔羅牌 ID 清單
deck = tarot_deck.copy()
# 從 S3 讀取完整塔羅牌資訊
info = s3_service.read_s3_file(bucket, key)
# 為塔羅牌建立索引,方便搜尋
# read_s3_file() 會回傳 JSON 字串,所以用 json.loads() 把字串轉成 list
tarot_by_id = {o['id']: o for o in json.loads(info)}
# 檢查是否 78 張牌都能正確讀取塔羅牌資訊
missing = [c['id'] for c in tarot_deck if c['id'] not in tarot_by_id]
if missing:
raise ValueError(f"找不到塔羅牌: {missing}")
print(f"驗證通過,共 {len(tarot_deck)} 張牌,每張皆有對應資料")
cards.py?直接把塔羅牌資料整合進程式不是更方便?
能不能整,當然可以。
但在實務上這麼做,很可能會讓後續維護變得麻煩。
這樣的分層,就像把「資料層」與「邏輯層」拆開一樣,
未來若要更換占卜素材或擴充牌義,也能更容易測試和維護。
除了分離資料與邏輯外,這樣的架構也能讓 Lambda 更輕量。
每次部署時只需要上傳主要程式碼,不必重新打包龐大的資料檔案。
將塔羅牌的資料存在 S3,還能讓它變成共用的素材,就算要擴充更多服務或功能,也能很方便的直接讀取,保證資料的泛用和一致性。

