早安!
昨天我們講到了RNN, 是可以讓模型有短期記憶的架構,但因為它在處理長距離依賴時仍有一些限制,所以後來又出現了 Bi-directional RNN、LSTM 等架構,讓模型能記住更長期的資訊。不過這些模型在處理資料時,必須「逐步」輸入(也就是一個時間步一個詞),無法同時看到整個句子,這讓訓練速度變慢、也容易出現「長距離資訊被稀釋」的問題。因此之後就有一個新的架構出來啦!那就是Transformer!
所以今天就要來跟大家介紹為什麼這個架構比之前的來得好,有或者說這個架構比之前的模型框架多了什麼以至於發展至今,這還是一個非常熱門的架構,現在提到AI 就會令人聯想到的GPT 背後跟transformer架構也有很大的關係👀 所以就別再廢話,趕快來看一下變形金剛吧!
在 Transformer 中,注意力機制可以說是它的靈魂,那什麼是注意力機制呢?
這個機制可以讓模型動態的關注輸入序列的不同部分,他的核心概念是能夠讓模型在處理每個詞語時,根據整個句子的上下文來重新表示每個詞的方式,主要會計算當前詞跟句中所有詞(包括自己)之間的關聯性(相似性),這些關聯性會轉換成一組權重,代表每個詞對該詞的重要程度。然後,根據這些權重,將所有詞的向量進行加權平均,產生該詞的一種新的表示,最後就可以得到一組包含上下文資訊的詞向量。
舉例還說,今天模型看到了一個句子:「我喜歡吃布丁」
當模型在處理「吃」這個詞時,它會:
比較「吃」與「我」的關聯 → 權重可能較低
比較「吃」與「喜歡」的關聯 → 權重中等
比較「吃」與「布丁」的關聯 → 權重最高(因為「吃」最常搭配「布丁」)
於是模型會更「注意」到「布丁」這個詞,
最終生成一個新的「吃」的向量,裡面蘊含了「吃布丁」的語意關係。
這樣的機制我們就稱為 Self-Attention(自注意力),
意思是模型自己在句子內部就能學會「誰跟誰有關」。
在說注意力時,會用到三個重要參數:
舉個例子來說,在你在某個平台輸入的關鍵字就是 Q(Query),系統裡每篇文章的標題或描述是 K(Key),而最終搜尋結果,也就是你真正取回的內容,就是 V(Value)。
模型會比較 Query 和每個 Key 的相似程度,分數越高的內容就被「注意」得越多。
在 Transformer 裡,當模型收到一串輸入後,每個詞都會先經過線性轉換,接著被映射成三組向量:Q、K、V。接著,模型就會拿每個詞的 Query 去和其他詞的 Key 做「相似度比較」。
這個相似度越高,代表這兩個詞的關聯越強。
具體計算方式:

另一個在Transformer 架構中很重要的東西就是Encoder–Decoder,應該說整個Transformer 架構就是由encoder與decoder 組成
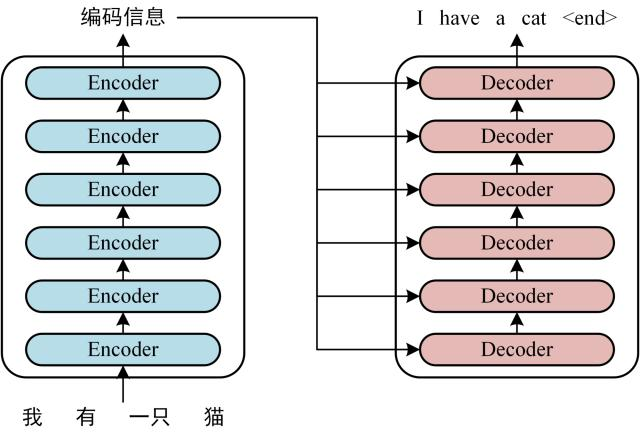
Encoder(編碼器):讀取輸入句子、理解意思,會根據輸入的特徵以向量的形式表示
Decoder(解碼器):會根據encoder 輸入的特徵還有其他輸入生成出要輸出的序列
其中 Encoder 與 Decoder 在運作時,都會用到剛剛提到的 Attention 機制
Encoder–Decoder 架構特別適合「序列到序列」(seq2seq)的任務,也就是給定一段輸入,要輸出另一段序列,但這段輸出可能與原本的input 一樣長,也有可能不一樣。例如在做翻譯、摘要時的任務就很適合,像是上面的參考圖就是一個用此架構做翻譯任務的例子。
但這兩個部分其實也是可以獨立做使用的,像是單獨的Encoder-only models會適用於需要理解輸入的任務,例如命名實體識別(NER),那Decoder-only 就是適用於生成任務,像今天大家熟知的 GPT,就是基於 Decoder-only 架構!
好啦!今天的 Transformer 我們就先淺淺地介紹到這邊~
其實它裡面還有許多複雜的數學與運算細節,不過我們的重點主要是搞懂它的核心概念、
以及它解決過去模型的哪些問題,更深入的部分大家有興趣也可以再去專研專研!
主要講這些也是因為跟目前很紅的GPT 有關,而明天開始,我們就要正式進入 GPT 的世界了,所以想說還是淺淺的跟大家科普一下!那我們明天見嚕!

