圖片來源:Knowledge Graph or Vector Database… Which is Better? By Adam Lucek
相比起傳統的向量檢索,現在有知識圖譜、Raptor等技術。
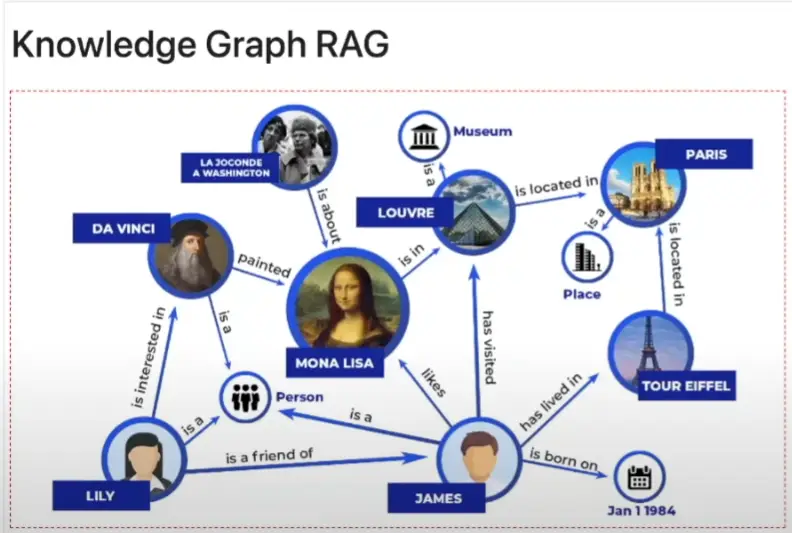
利用知識圖譜(Knowledge Graphs, KGs)和大型語言模型(Large Language Models, LLMs)可以克服傳統檢索增強生成(Retrieval Augmented Generation, RAG)系統的限制,從而創建出更為複雜且高效的知識檢索系統,這種方法通常被稱為「知識圖譜 RAG」(Knowledge Graph RAG)或 Graph RAG。
以下是關於如何利用這兩種技術來構建複雜知識檢索系統的詳細步驟和核心機制:
知識圖譜是一種知識庫,它使用圖結構數據模型或拓撲來表示和操作數據。
知識圖譜的關鍵組成部分:
• 實體 (點,Entities): 實體是知識圖譜中的節點(Nodes),是從文本塊中提取出的獨特對象、人物、地點、事件或概念。
• 關係 (邊,Relationships): 關係是圖中的邊,是連接兩個實體(節點)之間的具體聯繫。
• 社群 (集群,Communities): 社群是透過層次社群檢測(通常使用 Leiden 演算法等)識別出的相關實體及其關係的集群。社群有助於從非常廣泛的頂層概念到非常詳細的底層局部集群,提供不同層次的細節粒度。
克服傳統 RAG 的限制:
傳統 RAG 主要依賴於將文檔分割成文本塊,然後使用嵌入模型存儲在向量資料庫中,透過語義相似性來檢索相關塊。然而,這種方法在知識庫擴大或複雜性增加時,單純基於語義相似性的檢索會錯失數據中的聯繫或更廣泛的主題。
知識圖譜 RAG 透過結構化、層次化的方法來組織資訊,從而解決了這個限制。這種結構化方式能夠模仿人類的認知方式,將資訊理解為相互關聯的概念,而不僅僅是孤立的事實。
傳統上,知識圖譜的創建和策展是一個資源密集型的過程,需要手動構建或將傳統關係型資料庫轉換為圖結構。然而,大型語言模型的出現,使得從非結構化文本(如 Word 文件、PDF、部落格文章等)自動創建圖結構表示成為可能。
以 Microsoft 的開源工具 Graph RAG 為例,其數據流創建流程如下:
知識圖譜結構允許系統利用實體之間的連接和社群分組,實現比傳統語義檢索更精準、更具情境感知的檢索。Graph RAG 引入了三種主要的檢索類型:
A. 局部檢索 (Local Search)
局部檢索是更具體、顆粒化的回應方式。
• 流程: 首先,它使用語義搜索查詢圖譜中的實體(節點),這些節點已被嵌入到向量資料庫中。
• 圖遍歷: 檢索到的實體作為圖上的入口點。系統從這些入口點開始遍歷圖譜,提取與之相連的原始文本塊、相關的社群報告、其他實體及其關係。
• 優勢: 這些豐富的資訊隨後會被組合成上下文,提供給 LLM,即使在傳統 RAG 難以處理的相似資訊中,也能提供更精準的細節。
B. 全域檢索 (Global Search)
全域檢索專注於處理關於廣泛主題和思想的查詢,這是傳統 RAG 難以做到的。
• 流程: 給定查詢,系統會使用嵌入的社群報告(這些報告是高層次主題的摘要)來檢索最相似的報告。
• LLM 提煉: LLM 隨後會從這些檢索到的報告中提取關鍵點,並根據與查詢的相關性進行評分。
• Map-Reduce 排序: 系統會使用類似 Map-Reduce 的方法,過濾掉不相關的點,只保留最重要的點作為最終上下文,然後由 LLM 產生一個廣泛的回應。
C. 漂移檢索 (Drift Search - Dynamic Reasoning in Inference with Flexible Traversal)
漂移檢索是微軟引入的一種新穎方法,結合了全域和局部搜索的優勢,並加入了引導式探索。
• 初始步驟(全域): 使用假設文件嵌入(HDE)方法,根據查詢生成一個假設文件。系統使用這個假設文件來檢索最相似的社群報告(從全域層面開始)。
• 問題生成與局部搜索: 系統根據這些報告生成一個初步答案和後續問題。
• 精煉循環(局部): 針對每一個後續問題,系統會切換到局部檢索(Local Search)。每次局部檢索都會產生一個中間回應和新的後續問題。
• 優勢: 這個循環(Pseudo refinement Loop)透過生成後續問題來引導探索,從而擴大數據收集範圍。它結合了社群層次的知識和詳細的實體關係數據,能夠提供兼具廣泛背景和具體細節的、高度具體的回應。
GraphRAG是微軟開源的圖像RAG模組化工具,他主要使用到Leiden演算法(Louvain 演算法進階版),以下會簡單介紹一下從Louvain到Leiden的歷史。
在許多複雜網路中,節點(nodes)傾向於聚集成相對密集的群體,這些群體通常被稱為 社群(communities)。
這種模組化(modular)結構在分析之前往往是未知的,因此偵測社群結構成為一個重要問題。
1.1 模組化(Modularity)方法
最知名的社群偵測方法之一稱為 模組化(Modularity)最大化法。
此方法試圖最大化社群內實際邊數與隨機期望邊數的差異。

1.2 模組化最佳化的難題
最佳化模組化屬於 NP-hard 問題,因此出現了多種啟發式演算法,例如:
其中最受歡迎的就是 Louvain 演算法,以作者所在城市比利時 Louvain 命名。
多項比較研究指出:
Louvain 是目前速度最快、表現最優的演算法之一;
在社群偵測領域被大量引用並廣泛使用。
1.3 Louvain 的廣義形式
雖然 Louvain 最初是為模組化設計的,它也能用於其他品質函數。
一個常見替代方案是 Constant Potts Model(CPM),能克服模組化的一些限制。

解析度越高 → 更多社群;解析度越低 → 更少社群。
與模組化中的解析度參數概念相同。
1.4 Louvain 的主要缺陷
這篇論文證明,無論在模組化或 CPM 下,Louvain 都存在重大問題:
它可能生成任意程度連結不良的社群,甚至不連通。
這個問題獨立於著名的「解析度限制(resolution limit)」問題。
我們將在第二章詳細分析。
為解決此缺陷,這篇論文提出新演算法 Leiden,其特點包括:
整合多種改進方法(Smart Local Move、Fast Local Move、Random Neighbour Move);
產生的社群保證內部連通;
在迭代後收斂至局部最優且穩定的劃分;
執行速度比 Louvain 更快;
提供形式化的品質上界保證;
在多個基準與真實網路上驗證其優越性。
知識圖譜 RAG 系統的複雜性雖然帶來更高的實施和維護成本,以及更高的運算開銷,但其效益顯著:
• 更好的上下文保留: 圖譜 RAG 保留了非結構化知識中的結構關係和層次結構,相較於分塊方法,能更好地保留上下文和資訊之間的關係。
• 複雜推理能力: 透過圖遍歷,Graph RAG 能夠實現更好的多跳推理(multihop reasoning),連接分散在文檔中的多個事實。
• 回答品質提升: 由於可以存取相關資訊的連接,Graph RAG 往往能產生更完整、更連貫的回應。
知識圖譜和傳統嵌入與檢索方法並非相互替代,而是可以互補使用,將您的系統從簡單的概念驗證提升到更高層次。
Raptor 方法共有三個主要步驟。
這些步驟旨在將長上下文的特性帶入 RAG 應用中:
1. 文件層級嵌入(Embedding at the document level) Raptor 不像傳統做法那樣將文件進行分塊(chunking documents),而是直接在文件層級進行嵌入。
2. 叢集分組與高層次摘要(Grouping and high-level summaries) 系統接著將相似的文件分組為叢集(clusters),以形成高層次摘要(high level summaries)。
3. 遞迴形成文件樹(Recursive formation of a documentary) 這是一個遞迴的過程,目的是形成他們所稱的「文件樹」(a documentary)。
這種方法繞過了傳統的文本分割(traditional text splitting),讓使用者不必絞盡腦汁尋找最佳的分塊策略(optimal chunking strategy)。這個「文件樹」(documentary)具備階層結構,使得檢索過程能夠同時參考高層次概念 以及這些個別文件中更細節的資料(more granular details)。
1. 使用長上下文模型的技術限制
在使用長上下文模型時,仍然存在許多挑戰:
2. 檢索和準確性方面的潛在問題
儘管長上下文模型(例如 Google Gemini Pro 1.5 或開源的大型世界模型)聲稱可以處理一百萬個 token 的文件,並且在「針在乾草堆」(needle and the Hast has)測試中的結果看起來非常有希望,但在實際的 RAG 應用中,仍可能出現資訊檢索問題:
參考連結
From Louvain to Leiden |From Medium
From Louvain to Leiden: guaranteeing well-connected communities|Arxiv
Is Tree-based RAG Struggling? Not with Knowledge Graphs!|Youtube
Knowledge Graph or Vector Database… Which is Better? By Adam Lucek|Youtube


 iThome鐵人賽
iThome鐵人賽