Token、快取
OpenAI 的 GPT‑5 系列採用依 Token 計價的方式,不同階層的模型有不同價格。
以 GPT‑5 為例,官方定價頁指出:
若採用快速版 GPT‑5 mini:
更重要的是對「重複輸入 token」提供九折優惠──預先快取的輸入 token 僅收取原價的 10 %。
一個 Chat Completion 產生的費用可用以下公式估算:
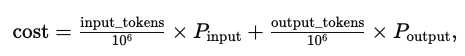
其中 P_input 與 P_output 分別為輸入與輸出百萬 token 的單價。
GPT‑5 支援上下文,輸入可達 272 k token、輸出可達 128 k token。這帶來龐大的記憶體與延遲成本。
根據 OpenAI 說明,為了減少延遲,GPT‑5 會使用「路由器」選擇不同的子模型,以兼顧快速回應與深入推理。
通常透過快取與動態批次,單次回應的延遲在數百毫秒至數秒之間,具體取決於輸入大小與負載。
假設我們在 Odoo CRM 模組中為每個客戶撰寫摘要,平均每個客戶紀錄含 1,200 字(約 1,600 token)。輸出摘要約 400 token。使用 GPT‑5 mini,成本計算如下:
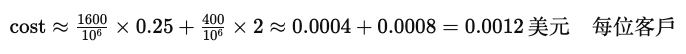
對於每天 1,000 名新客戶的系統,每日 LLM 成本約 1.2 美元。若採用標準 GPT‑5,成本約提高到 5 倍。這樣的分析能協助企業衡量雲端 LLM 與本地部署方案的經濟性。
即便單次呼叫費用不高,頻繁重複相似問題會迅速累積成本。OpenAI 的計價模型提供了 「已快取輸入 token 打 1 折」 的優惠。
快取策略的核心在於重用模型內部計算好的注意力鍵值(Key/Value)張量,可節省 90 % 的輸入成本和 85 % 的延遲。服務會為前置提示設定約 5 分鐘的生命週期,在此期間重複的前綴都可使用快取狀態。
我們可以在應用層自行實現快取。以下程式碼示範使用 Python 字典搭配 hashlib 建立 prompt 快取。若您的環境中部署了 Redis,可將字典替換為 Redis Client,並設定 TTL(時間有效期)。
import hashlib
import json
from typing import Dict
import openai # 假設已安裝 openai 套件
# 簡易快取,實際環境建議換成 redis.Redis()
response_cache: Dict[str, str] = {}
def gpt5_request(messages: list[dict], model: str = "gpt-5-mini") -> str:
"""查詢 GPT‑5,先檢查快取,若命中則直接回傳。"""
# 用 messages 內容生成雜湊作為 cache key
prompt_key = hashlib.md5(json.dumps(messages).encode("utf-8")).hexdigest()
if prompt_key in response_cache:
return response_cache[prompt_key] # 命中快取
# 未命中時呼叫 OpenAI API
completion = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0.3,
)
answer: str = completion["choices"][0]["message"]["content"]
# 儲存到快取,視需求設定過期時間
response_cache[prompt_key] = answer
return answer
# 使用範例
messages = [
{"role": "system", "content": "你是一個禮貌的客服專員。"},
{"role": "user", "content": "幫我總結客戶 A 的銷售記錄。"},
]
print(gpt5_request(messages))
💡 Gary’s Pro Tip|統一提示
快取命中率取決於 prompt 完全一致,即使多加一個空格都會被視為新的輸入。使用固定模板產生提示(如 Odoo CRM 摘要、合約分類),即可最大化重用率。建議將前置 prompt 和實際內容分開,使前置部分能持續快取。
雲端 GPT‑5 雖然方便,但每次呼叫都需要付費,且資料需上傳雲端。對於注重隱私或希望降低長期成本的企業,本地部署 LLM 是一個可行選項。
vLLM 是由 UC Berkeley 等機構推出的高效 LLM 服務引擎。它透過 PagedAttention 在 GPU 記憶體中以動態塊配置注意力矩陣,以及 Continuous Batching 動態併發請求,讓單張 GPU 可以同時處理大量請求,效能提升 2–4 倍。vLLM 還提供自動擴充、前綴快取等生產環境功能。
vLLM 支援多種硬體平台。在 GPU 版本的安裝指南中,官方要求 GPU cuda 版本不低於 7.0(如 V100、A100、L4 或 H100 等)。
另一種選擇是 Ollama 等個人級框架。模型大小與硬體需求成正比:
相比雲端服務,本地模型一次性硬體投入較高,但長期運行無額外呼叫費用,且資料完全留在企業內部。
大型模型能力強大,卻也伴隨高成本與延遲。我們可以用 Router Agent 來根據任務複雜度選擇不同的模型或工具處理請求。
將 Router 定義為系統的決策層,負責將使用者請求路由到正確的函式或服務,以提升效率與可擴展性。
Router 可使用多種技術,包括 Function Calling(功能呼叫)、意圖分類 以及純程式碼路由
Function Calling 讓 LLM 不是直接執行程式,而是回傳要調用的工具名稱與參數,客戶端再執行工具並將結果回傳模型。這樣的模式可對接多個外部 API(天氣查詢、資料庫搜尋等),同時避免 LLM 胡亂編造。
以下提供一個簡易 Router Agent 範例:
from typing import Literal
def classify_intent(question: str) -> Literal["crm_summary", "contract_classify", "other"]:
"""簡易分類器,可替換成更精密的本地模型 (如 3B 參數)。"""
q = question.lower()
if any(keyword in q for keyword in ["客戶", "crm", "銷售"]):
return "crm_summary"
if any(keyword in q for keyword in ["合約", "契約", "文件"]):
return "contract_classify"
return "other"
def router_agent(question: str) -> str:
"""根據分類結果選擇不同處理路徑。"""
intent = classify_intent(question)
if intent == "crm_summary":
# 使用本地快模型 (例如 GPT‑4all) 生成簡短摘要
return local_model_generate_summary(question)
elif intent == "contract_classify":
# 呼叫 tool‑calling 功能:查詢內部合約分類 API
return call_contract_classifier_api(question)
else:
# 複雜或未知問題交由 GPT‑5
return gpt5_request([
{"role": "system", "content": "你是一個專業的 Odoo 顧問。"},
{"role": "user", "content": question}
])
# 假定這些函式已實作
def local_model_generate_summary(question: str) -> str: ...
def call_contract_classifier_api(question: str) -> str: ...
💡 Gary’s Pro Tip|清楚定義路由準則
Router 需有明確規則區分「簡單任務」與「複雜任務」。若過度依賴 Function Calling 路由,會造成延遲與資源消耗,並且很難調試;適當使用意圖分類或純程式碼路由可避免這些問題。
若要將 LLM 與 Odoo 整合,我們可在 Odoo 中建立 FastAPI 端點。OCA 的 fastapi module 允許在 Odoo 內部用 Pydantic 自動驗證輸入/輸出、產生 Swagger 文件。下列範例定義了一個端點,讀取 CRM 線索後呼叫 Router Agent,並回傳摘要:
# models/fastapi_endpoint.py
from odoo import fields, models
from ..router import router # 假定 router 在上例定義
class FastapiEndpoint(models.Model):
_inherit = "fastapi.endpoint"
app: str = fields.Selection(selection_add=[("crm_router", "CRM Router")], ondelete={"crm_router": "cascade"})
def _get_fastapi_routers(self):
if self.app == "crm_router":
return [router]
return super()._get_fastapi_routers()
# router.py
from fastapi import APIRouter, Depends
from odoo.addons.fastapi.dependencies import odoo_env
from odoo.api import Environment
from pydantic import BaseModel
router = APIRouter()
class LeadSummaryRequest(BaseModel):
lead_id: int
@router.post("/crm/summary")
async def crm_summary(req: LeadSummaryRequest, env: Environment = Depends(odoo_env)) -> dict:
# 取得線索資料
lead = env['crm.lead'].sudo().browse(req.lead_id)
question = f"請總結以下客戶資訊:名稱:{lead.name},備註:{lead.description}"
answer = router_agent(question)
return {"summary": answer}
透過上述實作,企業可在 Odoo 後端直接呼叫 LLM 完成客戶摘要或合約分類,並透過 Router Agent 自動選擇最合適的模型或工具。
以下圖示從 Odoo 使用者發出請求到 LLM 返回結果的整體流程。圖中包含快取層、本地模型 API、Router Agent 及雲端 GPT‑5。
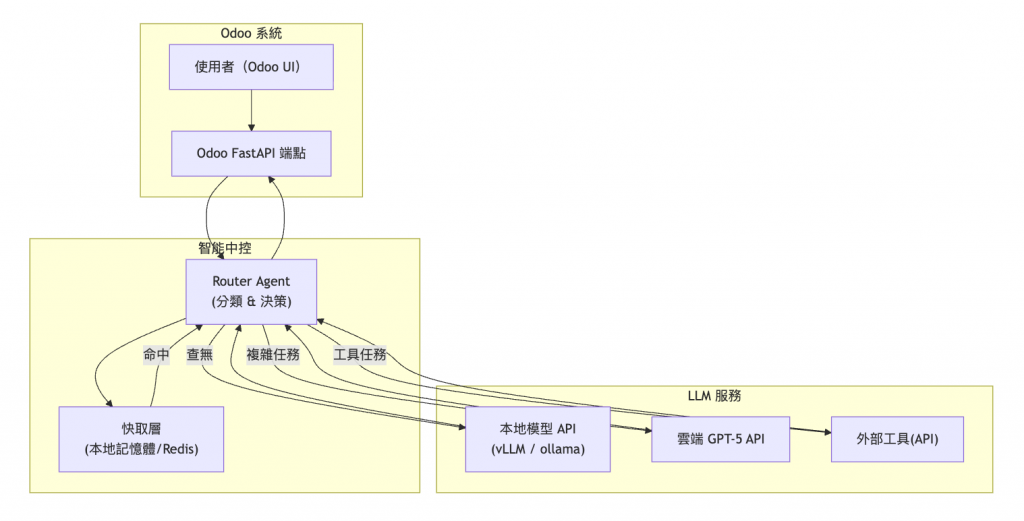
在如今生成式 AI 非常火熱的情況下,成本估與部署就是一門很重要的學問:
透過以上策略,您可以在 Odoo 中有效整合大模型,既享受 GPT‑5 的強大能力,又能控制成本與效能,真正達到「效能與成本雙重優化」。


