大師的投影螢幕上顯示著一個複雜的系統架構圖。
洛基還沒坐下,就被這個圖吸引住了。圖上標示著多個表、多個索引、以及它們之間的關係,還有密密麻麻的容量配置數據和成本估算。
「這是什麼系統?」洛基問。
「星際協作平台,」大師說,「支援多個星球的科學家協同工作。我需要你幫我設計索引策略。」
洛基有點意外:「我?」
「這三天你學了索引的原理、GSI 的權衡、LSI 的限制,」大師說,「今天是實戰——把知識整合成完整的設計能力。」
他切換投影,顯示系統需求:
星際協作平台需求:
實體關係:
- 使用者(User)
- 專案(Project)
- 任務(Task)
- 文件(Document)
- 評論(Comment)
核心查詢:
1. 查詢使用者的所有專案(1000 QPS,Queries Per Second)
2. 查詢專案的所有任務(500 QPS)
3. 查詢任務的所有評論,按時間排序(200 QPS)
4. 查詢任務的所有評論,按讚數排序(50 QPS)
5. 查詢特定狀態的專案(100 QPS)
6. 查詢特定優先級的任務(80 QPS)
7. 查詢使用者建立的所有文件(30 QPS)
8. 查詢待審核的文件(每天 500 次)
洛基看著這些需求,感覺壓力驟增。這不是單一查詢的設計,而是整個系統的索引規劃。
「從哪裡開始?」洛基問。
大師微笑:「從主表設計開始。」
大師在白板上寫下:
步驟 1:識別核心查詢
步驟 2:設計主表 PK/SK
步驟 3:評估次要查詢
步驟 4:決定索引策略
「首先,」大師說,「八個查詢中,哪個是最核心的?」
洛基分析:「查詢 1,使用者的專案,1000 QPS 最高。」
「對,」大師說,「這決定了主表的 PK 設計。」
他開始在白板上設計:
// 主表設計方向 A:以使用者為中心
{
PK: 'USER#alice',
SK: 'PROJECT#SY210-03-15#project-001',
projectName: '火星地質研究',
status: 'ACTIVE',
priority: 'HIGH'
}
// 支援查詢:
// ✓ 查詢 1:使用者的專案(直接 Query)
// ✓ 查詢 2:專案的任務(需要考慮)
洛基問:「但查詢 2 也很重要,500 QPS。如果主表用 USER 作為 PK,要查『專案的任務』會很困難。」
「正確,」大師說,「這就是矛盾點。我們來看另一個方向。」
// 主表設計方向 B:以專案為中心
{
PK: 'PROJECT#project-001',
SK: 'TASK#SY210-03-15#task-001',
taskName: '採集樣本',
status: 'IN_PROGRESS',
priority: 'HIGH'
}
// 支援查詢:
// ✓ 查詢 2:專案的任務(直接 Query)
// ✗ 查詢 1:使用者的專案(需要 GSI)
洛基陷入思考:「方向 A 優化查詢 1,方向 B 優化查詢 2。但查詢 1 的 QPS 更高...」
「所以?」大師問。
「選擇方向 A,」洛基說,「用主表支援最高頻的查詢,用 GSI 支援次高頻的查詢。」
大師點頭:「這就是第一個原則——主表優先支援最高頻查詢。」
但洛基發現問題:「如果主表用 PK: USER#alice,那專案資料、任務資料、文件資料都要放在同一個表嗎?」
「對,」大師說,「這就是 Single Table Design 的核心——用 SK 區分不同實體。」
他展示完整設計:
// 單表設計:所有實體放在同一個表
// 使用者的專案
{
PK: 'USER#alice',
SK: 'PROJECT#SY210-03-15#project-001',
type: 'Project',
projectName: '火星地質研究',
status: 'ACTIVE'
}
// 使用者的文件
{
PK: 'USER#alice',
SK: 'DOCUMENT#SY210-03-16#doc-001',
type: 'Document',
docName: '研究報告',
reviewStatus: 'PENDING'
}
// 專案的任務
{
PK: 'PROJECT#project-001',
SK: 'TASK#SY210-03-15#task-001',
type: 'Task',
taskName: '採集樣本',
assignedTo: 'USER#bob',
priority: 'HIGH'
}
// 任務的評論
{
PK: 'TASK#task-001',
SK: 'COMMENT#SY210-03-16#14:30#comment-001',
type: 'Comment',
content: '樣本已採集',
author: 'USER#bob',
likes: 5
}
洛基看著這個設計:「所以不同實體用不同的 PK 前綴,但都在同一個表裡。」
「對,」大師說,「這樣可以用 PK 來高效查詢。現在來看查詢支援狀況。」
查詢支援分析:
✓ 查詢 1:USER#alice → 所有 PROJECT#* (主表 Query)
✓ 查詢 2:PROJECT#001 → 所有 TASK#* (主表 Query)
✓ 查詢 3:TASK#001 → 所有 COMMENT#*,按時間排序
(SK 已按時間排序,主表 Query)
✗ 查詢 4:TASK#001 → 所有 COMMENT#*,按讚數排序
(需要索引)
✗ 查詢 5:查詢特定狀態的專案
(status 不在 PK/SK)
✗ 查詢 6:查詢特定優先級的任務
(priority 不在 PK/SK)
✓ 查詢 7:USER#alice → 所有 DOCUMENT#* (主表 Query)
✗ 查詢 8:查詢待審核的文件
(reviewStatus 不在 PK/SK)
「主表支援了 5 個查詢,」洛基說,「還有 3 個需要索引。」
「很好,」大師說,「現在來設計索引策略。」
大師在白板上寫下分析框架:
索引需求分析:
查詢 4:按讚數排序評論(50 QPS)
├─ 特性:同一任務範圍內,不同排序
├─ 候選:LSI 或 GSI
├─ LSI 評估:
│ ✓ 相同 PK (TASK#xxx)
│ ✓ 只是改變排序(按 likes)
│ ✓ 資料量:平均 50 評論/任務 × 2KB = 100KB(遠低於 10GB)
│ ✓ 需求明確(按讚數排序不會變)
│ → LSI 適合
│
└─ LSI 設計:
{
PK: 'TASK#task-001',
LSK: 'LIKES#0005#COMMENT#comment-001' // 補零確保排序
}
查詢 5:按狀態查專案(100 QPS)
├─ 特性:新查詢維度(不同 PK)
├─ 只能用 GSI
├─ 問題:status 是低基數屬性(ACTIVE, COMPLETED, ARCHIVED)
├─ 風險:熱分區
└─ 解決方案:複合 PK
查詢 6:按優先級查任務(80 QPS)
├─ 特性:新查詢維度
├─ 只能用 GSI
├─ 問題:priority 是低基數屬性(HIGH, MEDIUM, LOW)
└─ 解決方案:複合 PK
查詢 8:查待審核文件(500 次/天 = 0.006 QPS)
├─ 特性:極低頻查詢
├─ 候選方案:
│ 1. GSI
│ 2. Scan + Filter
│ 3. 應用層處理
└─ 成本分析決定
洛基看著這個分析,問:「查詢 8 這麼低頻,應該不需要 GSI 吧?」
大師說:「讓我們算一下。」
大師展示計算過程:
// 查詢 8:待審核文件(500 次/天)
// 資料估算
const documentStats = {
總文件數: 100000,
待審核比例: '5%',
待審核文件數: 5000,
單筆大小: '3KB'
};
// 方案 A:Scan + FilterExpression
const scanCost = {
每次Scan: '100,000 items × 3KB = 300,000 KB',
RCU計算: '300,000 KB / 4KB = 75,000 RCU',
每日成本: '75,000 RCU × 500 次 = 37,500,000 RCU/天',
月成本_OnDemand: '37.5M × 30 / 1M × $0.25 = $281/月',
備註: '即使只回傳 5000 筆,仍要掃描全表'
};
// 方案 B:GSI (KEYS_ONLY)
const gsiCost = {
投影: 'KEYS_ONLY',
RCU需求: '500 次/天 / 86400 ≈ 0.006 QPS → 1 RCU provisioned',
WCU需求: '假設每天新增 100 文件 → 1 WCU provisioned',
月成本: '1 RCU × $0.00013/小時 × 24 × 30 = $0.09',
儲存成本: '100,000 × 100 bytes (KEYS_ONLY) = 10MB × $0.25/GB = $0.003',
總成本: '$0.09/月'
};
// 決策
const decision = {
結論: '建立 GSI',
原因: 'Scan 成本 $281 >> GSI 成本 $0.09',
關鍵: '低頻不代表便宜,資料量才是關鍵'
};
洛基恍然大悟:「所以即使查詢頻率很低,如果資料量大,Scan 還是很貴。」
「正確,」大師說,「這就是第23天學到的——判斷要綜合考慮頻率和資料量。」
大師繼續:「查詢 8 還有另一個優化空間——稀疏索引。」
洛基好奇:「什麼是稀疏索引?」
大師解釋:「GSI 的一個特性——只有包含索引鍵屬性的項目,才會出現在 GSI 中。」
他展示設計:
// 主表:所有文件
{
PK: 'USER#alice',
SK: 'DOCUMENT#SY210-03-16#doc-001',
docName: '研究報告',
reviewStatus: 'APPROVED'
// 沒有 GSI_ReviewPK 屬性
}
{
PK: 'USER#bob',
SK: 'DOCUMENT#SY210-03-17#doc-002',
docName: '實驗數據',
reviewStatus: 'PENDING',
GSI_ReviewPK: 'REVIEW#PENDING', // ← 只有待審核文件有這個屬性
GSI_ReviewSK: 'DOCUMENT#SY210-03-17#doc-002'
}
// GSI_ReviewIndex:只包含待審核文件
// - 100,000 個文件
// - 只有 5,000 個(5%)有 GSI_ReviewPK
// - GSI 只存 5,000 筆,不是 100,000 筆
洛基理解了:「所以 GSI 的大小比主表小很多?」
「對,」大師說,「這就是稀疏索引的優勢。」
// 稀疏索引的成本優勢
const sparseIndexBenefit = {
主表大小: '100,000 items × 3KB = 300MB',
密集索引: {
描述: '所有項目都有 GSI 鍵',
GSI大小: '100,000 items × 100 bytes = 10MB',
儲存成本: '$2.5/月'
},
稀疏索引: {
描述: '只有待審核項目有 GSI 鍵',
GSI大小: '5,000 items × 100 bytes = 0.5MB',
儲存成本: '$0.125/月',
省下: '95% 儲存成本'
},
查詢效能: {
密集索引: '需要 FilterExpression 過濾 95% 的資料',
稀疏索引: 'Query 直接回傳所需資料,無需過濾'
}
};
「更重要的是,」大師說,「稀疏索引的查詢更快——不需要 FilterExpression,直接 Query 就得到結果。」
洛基興奮起來:「所以對於『只需要查詢一部分資料』的場景,稀疏索引是最優解?」
「對,」大師點頭,「這是進階技巧。」
大師展示實作細節:
// 模式 1:寫入時動態設定 GSI 鍵
async function createDocument(userId, docName, reviewStatus) {
const item = {
PK: `USER#${userId}`,
SK: `DOCUMENT#${Date.now()}#${generateId()}`,
docName,
reviewStatus
};
// 只有待審核文件才設定 GSI 鍵
if (reviewStatus === 'PENDING') {
item.GSI_ReviewPK = 'REVIEW#PENDING';
item.GSI_ReviewSK = item.SK;
}
await docClient.put({ TableName: 'Platform', Item: item });
}
// 模式 2:狀態變更時維護 GSI 鍵
async function approveDocument(pk, sk) {
await docClient.update({
TableName: 'Platform',
Key: { PK: pk, SK: sk },
UpdateExpression:
'SET reviewStatus = :approved REMOVE GSI_ReviewPK, GSI_ReviewSK',
ExpressionAttributeValues: {
':approved': 'APPROVED'
}
});
// 移除 GSI 鍵 → 項目從 GSI 中消失
}
// 模式 3:查詢待審核文件
async function getPendingDocuments() {
return await docClient.query({
TableName: 'Platform',
IndexName: 'GSI-Review',
KeyConditionExpression: 'GSI_ReviewPK = :review',
ExpressionAttributeValues: {
':review': 'REVIEW#PENDING'
}
});
// 只查詢 GSI → 只掃描待審核文件,不掃描全表
}
洛基看著這個模式:「所以關鍵是在狀態變更時,動態新增或移除 GSI 鍵?」
「正確,」大師說,「這就是稀疏索引的維護策略。Hippo 請展示一下適用場景的比較圖。」
「馬上來!」Hippo立刻接話。
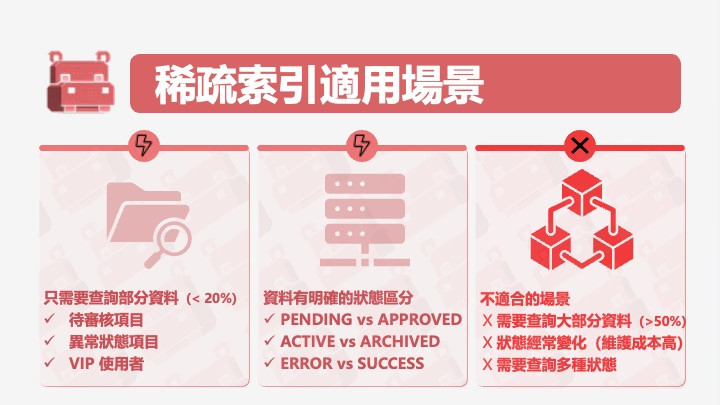
大師回到投影螢幕,展示完整設計:
// 最終索引策略
const indexStrategy = {
主表設計: {
說明: '支援 5 個核心查詢',
PK_patterns: ['USER#xxx', 'PROJECT#xxx', 'TASK#xxx'],
支援查詢: [1, 2, 3, 7]
},
LSI設計: {
LSI_CommentLikes: {
PK: 'TASK#xxx',
LSK: 'LIKES#nnnn#COMMENT#xxx',
支援查詢: [4],
原因: '同實體不同排序,資料量小',
資料量評估: '50 評論/任務 × 2KB × 2 (主表+LSI) = 200KB << 10GB'
}
},
GSI設計: {
GSI_ProjectStatus: {
PK: 'STATUS#ACTIVE#SY210-03', // 複合 PK 避免熱分區
SK: 'PROJECT#xxx',
支援查詢: [5],
投影: 'INCLUDE [projectName, createdDate]',
容量: '100 RCU, 50 WCU'
},
GSI_TaskPriority: {
PK: 'PRIORITY#HIGH#PROJECT#xxx', // 複合 PK
SK: 'TASK#xxx',
支援查詢: [6],
投影: 'INCLUDE [taskName, assignedTo, dueDate]',
容量: '80 RCU, 40 WCU'
},
GSI_PendingReview: {
PK: 'REVIEW#PENDING',
SK: 'DOCUMENT#xxx',
支援查詢: [8],
投影: 'KEYS_ONLY', // 最小投影
容量: '1 RCU, 1 WCU',
特性: '稀疏索引(只有 5% 項目)'
}
},
成本估算: {
主表: '100 RCU, 100 WCU = $15/月',
LSI: '共用主表容量 = $0',
GSI1: '100 RCU, 50 WCU = $11/月',
GSI2: '80 RCU, 40 WCU = $9/月',
GSI3: '1 RCU, 1 WCU = $0.15/月',
總計: '$35.15/月 (vs Scan 方案 $300+/月)'
},
設計原則總結: {
1: '主表優先最高頻查詢',
2: 'LSI 用於同實體排序 + 資料量可控',
3: 'GSI 低基數屬性用複合 PK',
4: '低頻大資料量查詢仍需 GSI',
5: '稀疏索引優化部分資料查詢',
6: '投影類型根據查詢需求選擇',
7: '成本估算驗證設計合理性'
}
};
洛基仔細看著這個完整設計,感覺所有片段都連接起來了。
「這就是索引策略的系統化思考,」大師說,「不是單點優化,而是整體平衡。」
大師繼續:「但設計不是一次性的。系統會成長,需求會變化。」
他展示演進策略:
索引演進的三階段:
階段 1:MVP(最小可行產品)
├─ 只建立絕對必要的索引
├─ 核心查詢:1, 2, 3 (主表支援)
├─ 次要查詢:暫時用 Scan 或應用層處理
└─ 觀察實際使用模式
階段 2:優化(基於監控數據)
├─ CloudWatch 分析:
│ - 哪些查詢 QPS 超出預期?
│ - 哪些 Scan 成本過高?
│ - 哪些查詢延遲過高?
├─ 根據數據決定:
│ - 新增 GSI_ProjectStatus (查詢 5 實際 QPS = 150)
│ - 新增 LSI_CommentLikes (查詢 4 實際 QPS = 80)
└─ 漸進式新增索引
階段 3:重構(需求重大變化)
├─ 檢視:
│ - 哪些索引使用率低?
│ - 哪些查詢模式改變了?
│ - 是否有更優的設計?
└─ 重構策略:
- 刪除未使用的 GSI
- 調整投影類型
- 考慮表分割或合併
洛基理解了:「所以不要一開始就建一堆索引,而是根據實際數據逐步優化。」
「對,」大師說,「這就是第23天提到的『始於精簡,隨需擴增』。」
大師展示監控面板:
// 關鍵監控指標
const monitoringMetrics = {
容量監控: {
指標: 'ConsumedReadCapacityUnits / ProvisionedReadCapacityUnits',
警報: '> 80% 持續 5 分鐘 → 考慮擴容',
目的: '避免 Throttling'
},
索引使用率: {
GSI1_QueryCount: '平均 120 QPS',
GSI2_QueryCount: '平均 85 QPS',
GSI3_QueryCount: '平均 0.006 QPS',
分析: 'GSI3 使用率極低但成本也極低,保留合理'
},
成本分析: {
主表成本: '$15/月',
GSI成本: '$20/月',
總成本: '$35/月',
vs預算: '符合預期'
},
效能分析: {
查詢延遲_P99: {
主表Query: '5ms',
GSI1_Query: '8ms',
GSI2_Query: '7ms',
評估: '符合 SLA (<50ms)'
}
},
異常檢測: {
ThrottlingCount: '0',
SystemErrors: '0',
UserErrors: '偶發 ValidationException (查詢參數錯誤)'
}
};
// 基於監控的決策
const monitoringDecisions = {
發現: 'GSI2 的 ConsumedWCU 持續 90%',
原因: '任務建立頻率高於預期',
行動: '擴容 GSI2 WCU: 40 → 60',
結果: 'Throttling 風險消除'
};
「監控不只是看數字,」大師說,「更重要的是根據數據做決策。」
洛基看著完整的設計方案,心中有種成就感。
他從一個不知道索引為何物的學習者,到現在能夠設計完整的索引策略——這三天的學習密度很高,但每一步都有意義。
大師問:「現在如果讓你總結索引設計的核心,你會怎麼說?」
洛基想了想:
「第一,索引的目的是優化查詢,但不是每個查詢都需要索引。要權衡頻率、資料量、成本。」
「第二,主表設計優先支援最核心的查詢,次要查詢用 GSI/LSI 補強。」
「第三,GSI 適用於新查詢維度,LSI 適用於同實體不同排序。LSI 限制多,預設選 GSI。」
「第四,低基數屬性要小心熱分區,用複合 PK 增加分散度。」
「第五,稀疏索引可以優化部分資料查詢,省成本也快。」
「第六,投影類型影響成本和效能,要根據實際查詢需求選擇。」
「第七,設計不是一次性的,要根據監控數據持續優化。」
大師滿意地點頭:「很完整。你已經建立起索引設計的思維框架了。」
洛基把筆記本闔上。
四天的索引學習,從理解「為什麼需要索引」開始,到 GSI 的成本權衡,再到 LSI 的特殊定位,最後整合成完整的設計決策樹。
他發現自己的思考方式在改變。
以前看到查詢需求,第一反應是「怎麼實現」。現在會先問「是否需要索引」「用什麼類型」「成本如何」「有沒有更好的方案」。
從單純的技術實現,到成本意識、到權衡思維、到演進策略。
大師走到窗邊:「索引設計告一段落。接下來幾天,我們會學習資料生命週期管理——TTL、Streams、備份還原。這些是讓系統長期穩定運行的關鍵。」
「TTL?」洛基問。
「Time To Live,資料過期自動刪除,」大師說,「你有想過資料該怎麼消失嗎?還是打算讓所有資料永久存在?」
洛基愣了一下。他確實沒想過這個問題。
「明天見,」大師說,「準備好面對一個成本災難的案例。」
洛基帶著新的疑問離開茶室。資料的生命週期...這又是一個他從未深入思考過的領域。
時間設定說明:故事中使用星際曆(SY210 = 西元2210年),程式碼範例為確保正確執行,使用對應的西元年份。

