
接下來我們將要討論 AI Observability 的其中一個很重要的主軸,那就是 Evaluation,有好的方法,我們才能讓我們的 AI Application 回應的質量進行穩定,並且也才能優化它。
Evaluation 主要做的就是評估你 AI Application 回應的好與不好
目前就我所知,判斷 AI 回應的好與不好的評分方式有以下三種 :
然後這三個東西目前在很多的 AI Platform 例如 Langsmith、Langfuse 都有支援,然後這系統我們會以 Langfuse 為主,因為免費。
然後這個評分方式理解完後,我們才能進行評分指標,但這個就後面幾篇。
Langfuse 是一個開源的 LLM Engineering Platform,把「可觀測性(tracing/metrics)」、「評估(evals)」、「提示詞管理(prompt management)」、「標註(annotations)」整合在同一套系統,協助團隊開發、監控、評估、除錯 AI Applcation。
整個 Langfuse 就是可以提供 AI Observability 的平台
架起來後就長的像這樣,之後在介紹它的其它功能,這篇我們要專注說 evaluation。
🤔 它的架構
然後當你將 Langfuse 建立起來後,它的整個架構如下圖 :
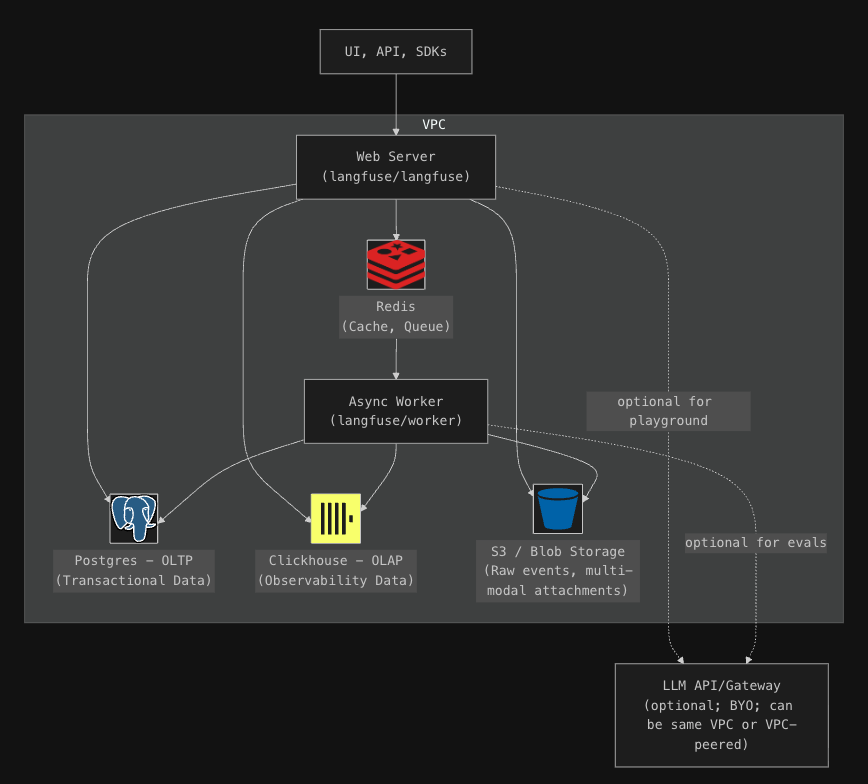
這裡簡單說一下每個在幹啥用的 :
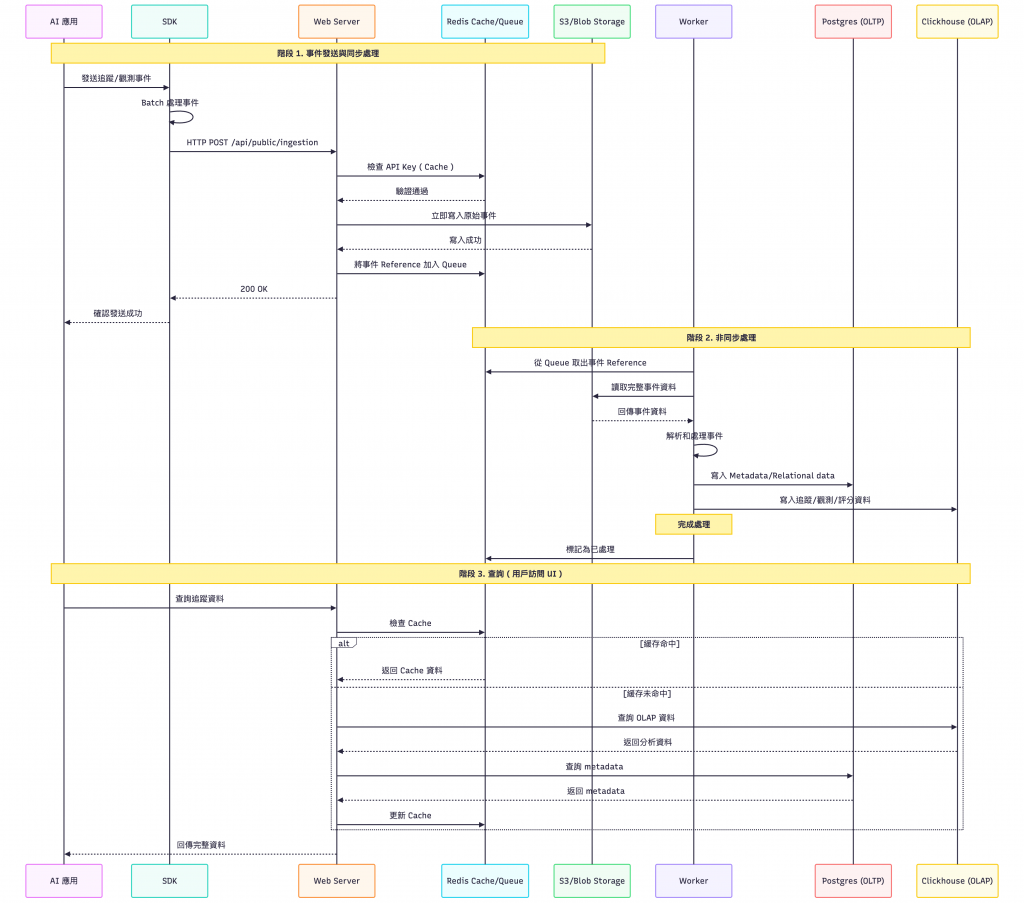
然後我們先來看看,當我們一個事件進來後整個流程,如下圖 :
我們先來看看事件進來的流程。
備註: 編號和圖不一樣,下面只是順序。
首先第一階段是送事件給 Langfuse 然後應用收到 OK。
再來是第二階段它這裡會將事件實際上的儲到資料庫中。
最後第三階段,這裡就是我們實際上在 Langfuse 的 Web 進行操作,基本上就是去這些資料庫來取得到資料,這個應該就不用說太多。
🤔 為什麼這個東西,會需要用到 4 個儲存類的服務呢 ~
Redis 應該是沒有毛病,他就是用來 Cache + Queue 使用,而 OLTP 是用來儲放一些需要放在關聯性資料庫且保證資料一致性的資料,而 OLAP 就比較是放一些不會變動的資料,例如 trace 之類的,因為這些之後要大量讀取與分析用。
至於它在這裡的定位,我自已覺得比較是為了在進行非同步時,作為第一層持久安全而存在的,也就是說以這個想法來看,那進入第二層持久 ( OLAP/OLTP ) 後應該是可以砍掉,但不確定,文件沒有說明很清楚。
🤔 Langfuse 有進行一些性能與可靠性的優化部份,我覺得思路可以學學
https://langfuse.com/self-hosting#optimized-for-performance-reliability-and-uptime
接下來我們針對上面三種 Evaluation 方式,來簡單看一下是如何用。
我這裡是用 docker-compose 來建立的實驗用的,參考官網這份文件。
https://github.com/langfuse/langfuse/blob/main/docker-compose.yml
備註: 正式環境一定不是這樣 ( 給新手 )
然後因為我是用 GCP ,所以我自已改成如下,而且上面官網的,很多東西不需要 :
version: "3.9"
services:
langfuse-worker:
image: docker.io/langfuse/langfuse-worker:3
restart: always
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
clickhouse:
condition: service_healthy
env_file: .env
ports:
- 127.0.0.1:3030:3030
volumes:
- ./secrets:/secrets:ro
langfuse-web:
image: docker.io/langfuse/langfuse:3
restart: always
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
clickhouse:
condition: service_healthy
ports:
- 3000:3000
volumes:
- ./secrets:/secrets:ro
env_file: .env
postgres:
image: postgres:15
environment:
POSTGRES_DB: langfuse
POSTGRES_DATABASE: langfuse
POSTGRES_USER: langfuse
POSTGRES_PASSWORD: test
volumes:
- ./docker-data/postgres:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U langfuse -d langfuse"]
interval: 10s
timeout: 5s
retries: 10
restart: unless-stopped
clickhouse:
image: clickhouse/clickhouse-server:24.8
environment:
CLICKHOUSE_DB: langfuse
CLICKHOUSE_USER: langfuse
CLICKHOUSE_PASSWORD: test
ulimits:
nofile:
soft: 262144
hard: 262144
volumes:
- ./docker-data/clickhouse:/var/lib/clickhouse
ports:
- "8123:8123"
- "9000:9000"
restart: always
healthcheck:
test: wget --no-verbose --tries=1 --spider http://localhost:8123/ping || exit 1
interval: 5s
timeout: 5s
retries: 10
start_period: 1s
redis:
image: redis:7
command: ["redis-server", "--requirepass", "test", "--appendonly", "yes"]
volumes:
- ./docker-data/redis:/data
ports:
- "6379:6379"
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 3s
timeout: 10s
retries: 10
restart: always
然後要用這份的話,有幾個東西要放對 :
# === 基本 ===
NEXTAUTH_URL=http://127.0.0.1:3000
NEXTAUTH_SECRET=abc
ENCRYPTION_KEY=0000000000000000000000000000000000000000000000000000000000000000
SALT=changeme
LANGFUSE_TELEMETRY_DISABLED=true
LANGFUSE_ENABLE_EXPERIMENTAL_FEATURES=true
# === Postgres ===
POSTGRES_PASSWORD=test
DATABASE_URL=postgresql://langfuse:test@postgres:5432/langfuse
# === ClickHouse(v3 需要) ===
CLICKHOUSE_CLUSTER_ENABLED=false
CLICKHOUSE_USER=langfuse
CLICKHOUSE_PASSWORD=test
CLICKHOUSE_URL=http://clickhouse:8123
CLICKHOUSE_MIGRATION_URL:clickhouse://test:test@clickhouse:9000/langfuse
# === Redis ===
REDIS_PASSWORD=test
REDIS_HOST=redis
REDIS_PORT=6379
REDIS_AUTH=test
# === GCP Bucket ===
LANGFUSE_USE_GOOGLE_CLOUD_STORAGE=true
LANGFUSE_S3_EVENT_UPLOAD_BUCKET=langfuse-mark
LANGFUSE_GOOGLE_CLOUD_STORAGE_CREDENTIALS=/secrets/credentials.json
LANGFUSE_S3_EVENT_UPLOAD_PREFIX=events/
然後就執行 docker-compose up 然後再等入到 127.0.0.1:3000 有看到登入畫面就對了。
https://langfuse.com/docs/evaluation/evaluation-methods/llm-as-a-judge
你的 AI 輸出 → 送給評審 LLM → 給分數/評價
🤔 Step 1. 建立 Evaluator,就是評估的機器人+評分方式
如果我們要用,那就先預設 LLM Model 如下圖,我們設定是 gpt-5-mini :
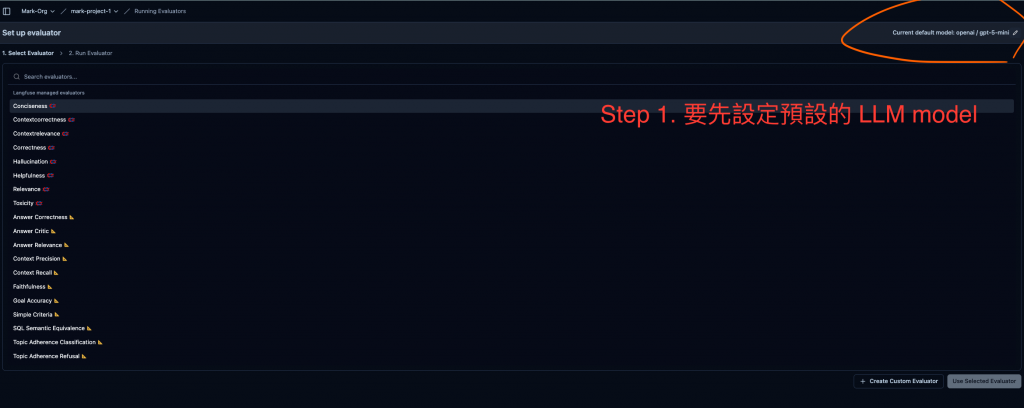
接下來我們有兩種選項可以用 Langfuse 提供的 evaluator 或是我們自訂的 evaluator ( 就是 prompt 我們自已想 )。
然後下圖那些看不太懂的單字,就是 Langfuse 提供的,那些單字下篇會說,它就是評估指標,我們這裡範例就先用自訂的。
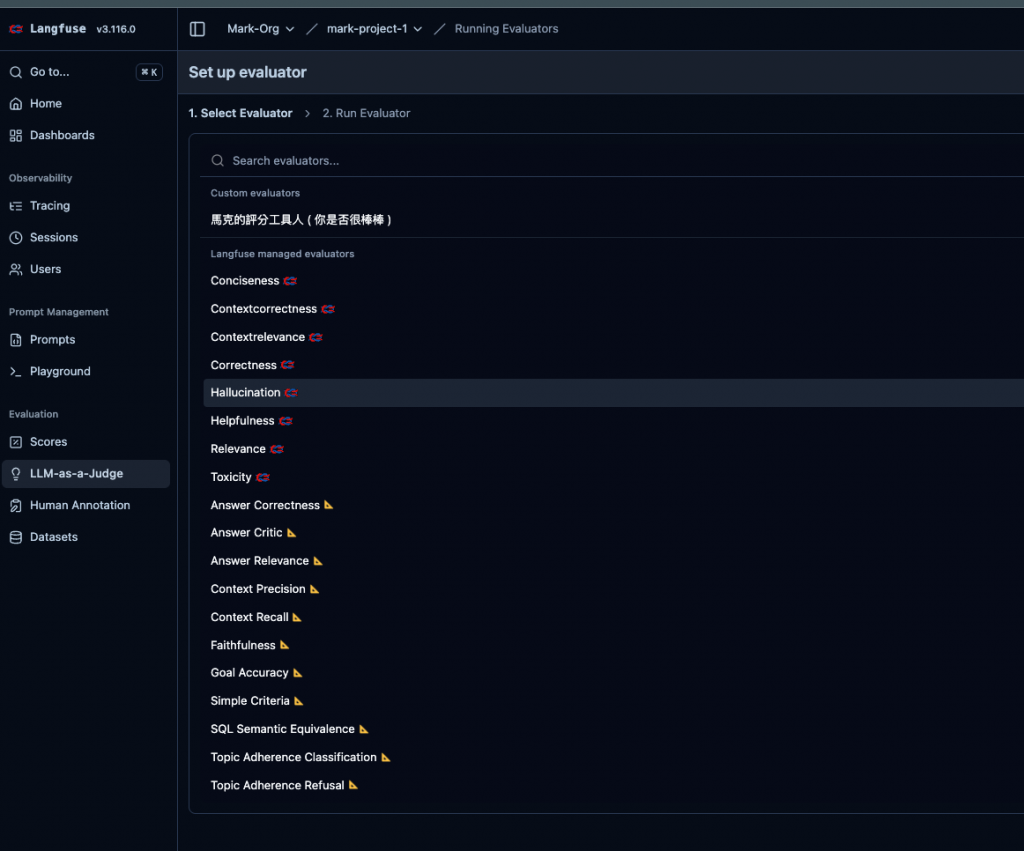
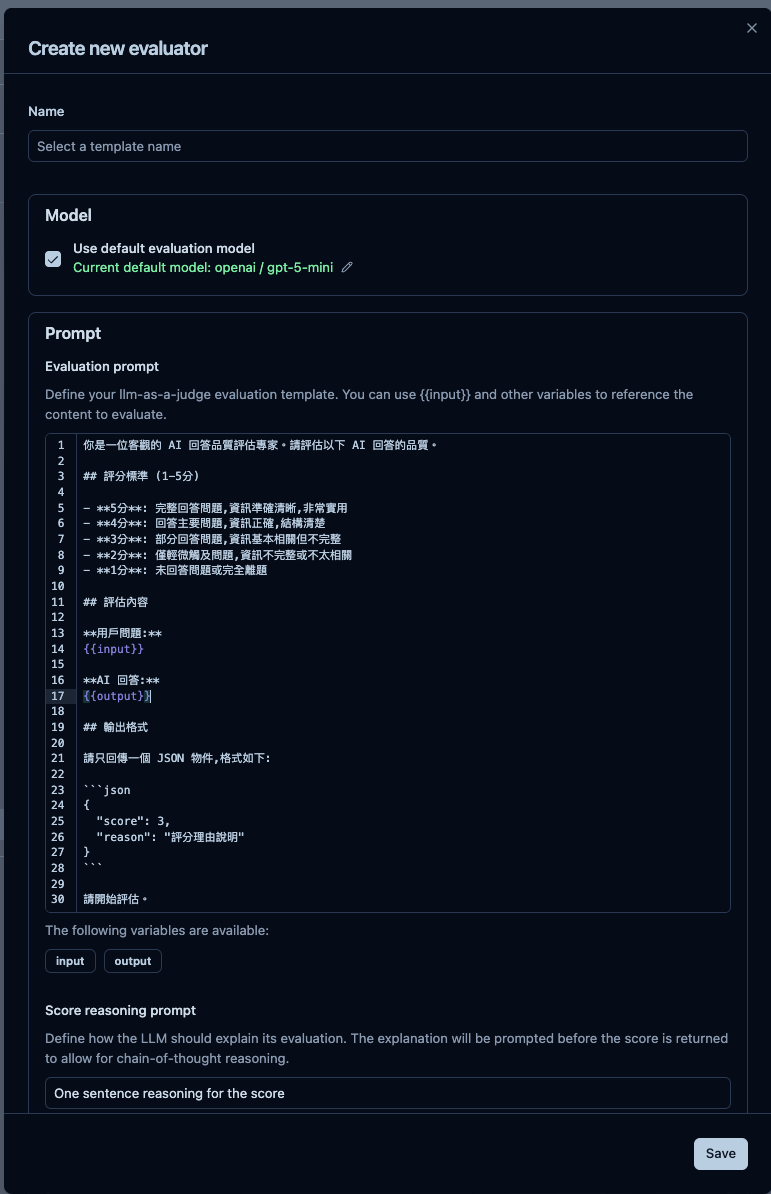
🤔 Step 2. 設定那些條件的 trace 會自動執行 ( 沒設好你就炸了 )
下面這個就是設定的地方,其中 filter 就是用來判斷那些要過這個 evaluator,這個在另一篇會說,因為這和指標與情境有關。
然後這裡先以 label 為範例,就是如果 trace 有這個 label ai-judge的,則進行 eval。
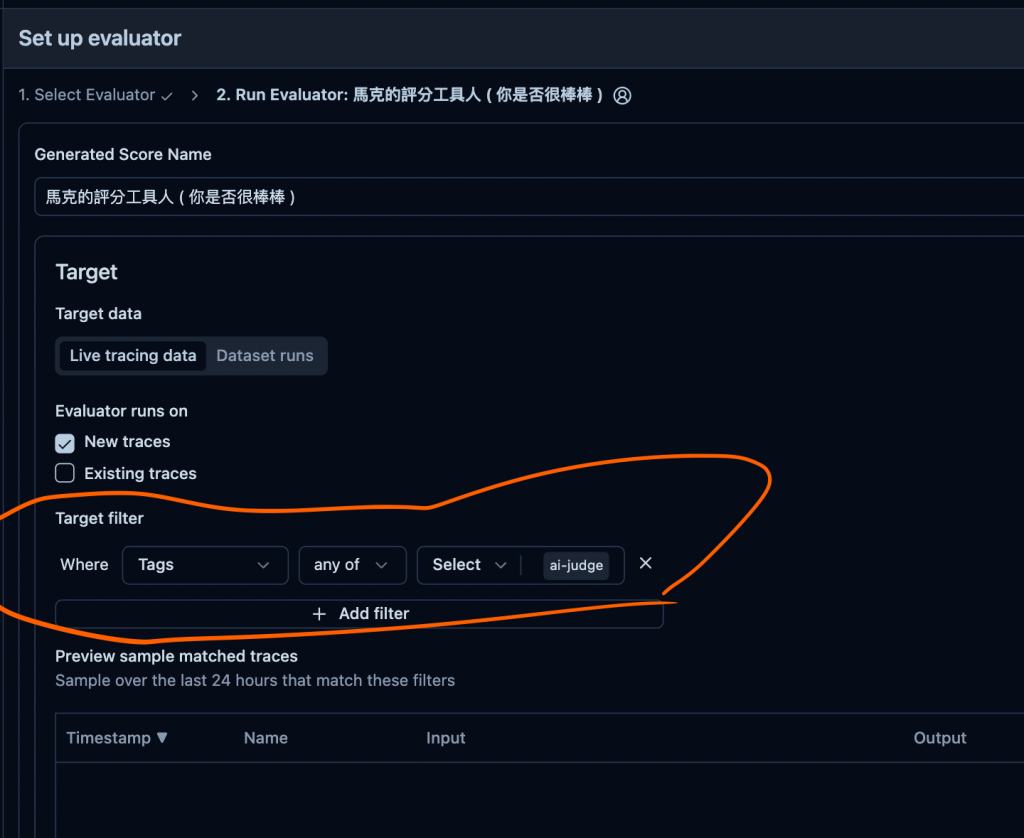
🤔 Step 3. 送個有 ai-judge 的 trace
import Langfuse from "langfuse";
import OpenAI from "openai";
process.env.LANGFUSE_SECRET_KEY = "sk-lf-55578317-fd2d-47de-9a09-ed2b3ace927a";
process.env.LANGFUSE_PUBLIC_KEY = "pk-lf-91fc647a-b184-44cd-a3c6-d293fdd7a346";
process.env.LANGFUSE_BASE_URL = "http://127.0.0.1:3000";
const langfuse = new Langfuse({
publicKey: process.env.LANGFUSE_PUBLIC_KEY,
secretKey: process.env.LANGFUSE_SECRET_KEY,
baseUrl: process.env.LANGFUSE_BASE_URL,
});
// ============================================
// 1. LLM-as-a-Judge 評分
// ============================================
async function llmAsJudgeScoring() {
// 步驟 1: 記錄你的 AI 應用的對話
const userQuery = "如何重設密碼?";
const aiResponse =
"請到設定頁面點選「忘記密碼」,系統會發送重設連結到您的信箱。";
const trace = langfuse.trace({
name: "這個是要叫 AI 評分的-3",
userId: "mark",
input: {
role: "user",
content: userQuery,
},
output: {
role: "assistant",
content: aiResponse,
},
tags: ["ai-judge"],
});
const generation = trace.generation({
name: "ai-response",
model: "gpt-5-mini",
input: [{ role: "user", content: userQuery }],
output: aiResponse,
});
await langfuse.flushAsync();
console.log("✅ LLM-as-a-Judge 評分完成");
}
(async () => {
await llmAsJudgeScoring();
})();
然後結果如下,LLM 真是嚴格。
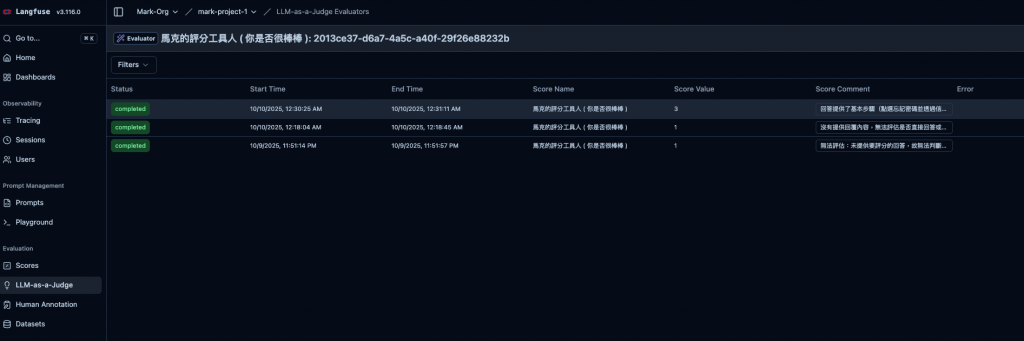
AI 輸出 → 顯示在 Langfuse UI → 人類評審者打分
下面這一段就只是產生 Trace 送到 Langfuse。
import { Langfuse } from "langfuse";
// 2. Human Annotation (人工標註)
// ============================================
async function humanAnnotationSetup() {
const langfuse = new Langfuse({
publicKey: process.env.LANGFUSE_PUBLIC_KEY,
secretKey: process.env.LANGFUSE_SECRET_KEY,
baseUrl: process.env.LANGFUSE_BASE_URL,
});
// 步驟 1: 記錄需要人工評審的對話
const trace = langfuse.trace({
name: "需要人工標註的對話",
userId: "mark",
metadata: {
needsReview: true, // 標記需要人工審核
priority: "high",
},
input: {
role: "user",
content: "我的帳單有誤,想要退款並取消訂閱",
},
output: {
role: "assistant",
content: "我了解您的困擾。關於退款,我們需要先確認您的訂單編號。取消訂閱可以在帳戶設定中操作。",
},
});
// 這個是假設你的LLM回答
trace.generation({
name: "ai-response",
model: "gpt-5-mini",
});
await langfuse.flushAsync();
// 注意: 人工評分是在 Langfuse UI 中進行,不需要程式碼
// 評分後,可以透過 API 查詢評分結果
}
(async () => {
await humanAnnotationSetup();
})();
其中有個地方可以注意一下 langfuse.trace 與 trace.generation 這兩個分別執行建立後的結果就會如下圖畫線的地方,綠字的是 langfuse.trace 的內容,而紅字則為 trace.generation :
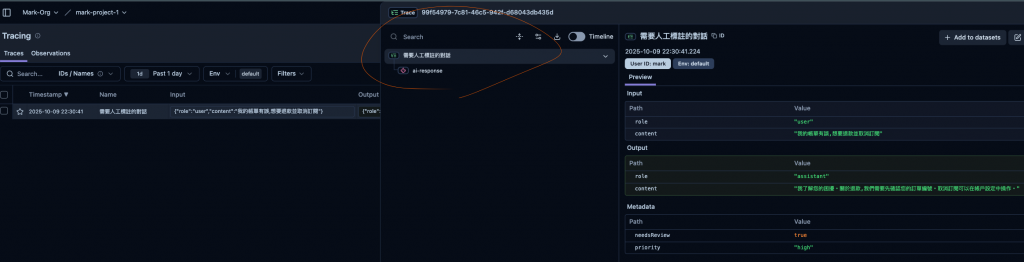
然後接下來我們就來人工評份
我們會將剛剛產生的 trace 送到這個待評份的 Queue 中 ( 需要馬克大人判斷是否正確 ),順到說一下這個 Queue 也先手動建立。
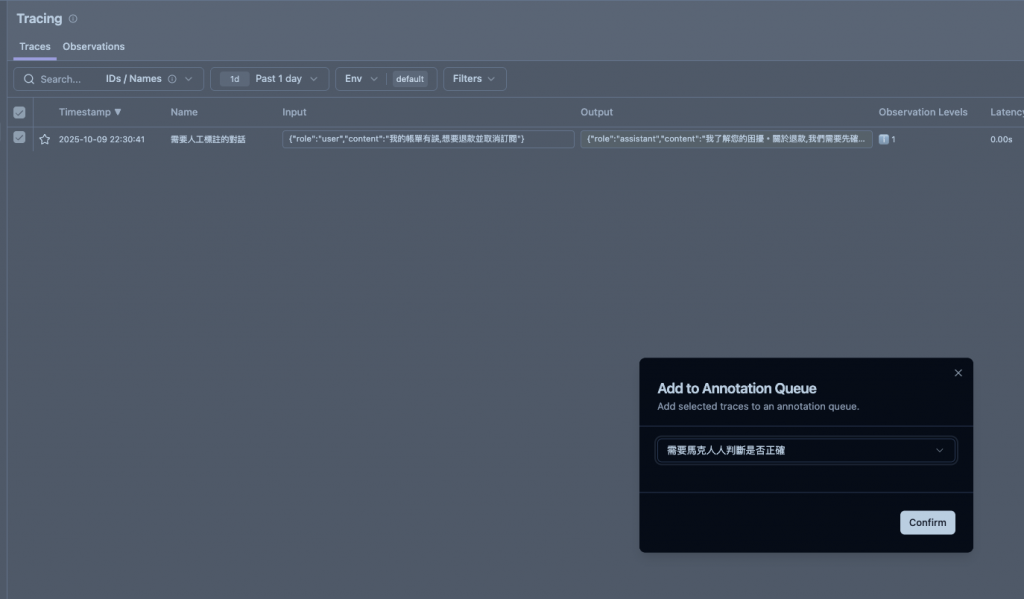
然後在進 Queue 中看到這個 trace 就可以進行評份了。
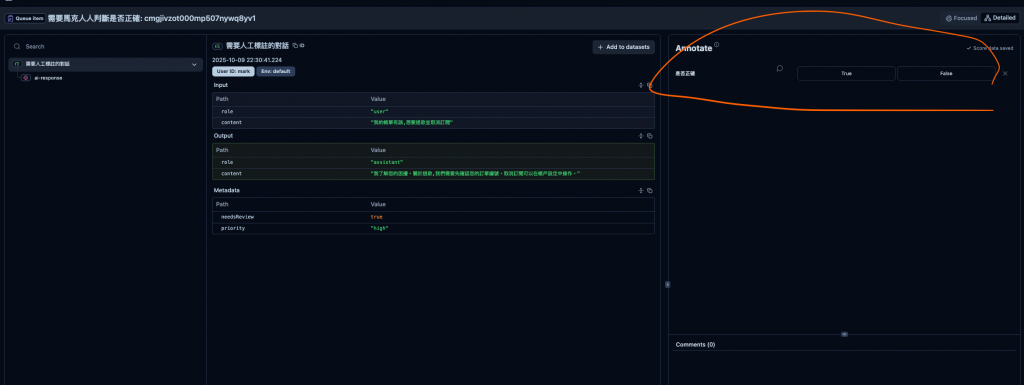
AI 輸出 -> 你在你的程式碼寫個 Score ( 評分方法 -> 在同步至 Langfuse
https://langfuse.com/docs/evaluation/evaluation-methods/custom-scores
下面為我們的範例程式碼,我們就是用一些方法來判斷 AI 的回應,例如我們下面就直接判斷他有沒有包含價格/元之類的關鍵字 ( 這是範例 ),然後再將它同到 Langfuse。
import { Langfuse } from "langfuse";
// ============================================
// 3. 透過 API/SDK 自訂評分
// ============================================
async function customAPIScoring() {
const langfuse = new Langfuse({
publicKey: process.env.LANGFUSE_PUBLIC_KEY,
secretKey: process.env.LANGFUSE_SECRET_KEY,
baseUrl: process.env.LANGFUSE_BASE_URL,
});
const userQuery = "推薦我一台適合打遊戲的筆電";
const aiResponse = `我推薦以下筆電:
1. ASUS ROG Strix G15 - NT$45,000
2. MSI Katana 15 - NT$38,000
配備 RTX 4060 顯卡,16GB RAM`;
const trace = langfuse.trace({
name: "product-recommendation",
userId: "mark",
input: {
role: "user",
content: userQuery,
},
output: {
role: "assistant",
content: aiResponse,
},
});
const generation = trace.generation({
name: "recommendation",
model: "gpt-5-mini",
input: [{ role: "user", content: userQuery }],
output: aiResponse,
});
// 步驟 2: 自訂評分邏輯 - 檢查是否包含價格資訊
function customEvaluate(response: string): boolean {
return /NT\$|元|價格/.test(response);
}
const score = customEvaluate(aiResponse);
// 步驟 3: 記錄評分到 Langfuse
langfuse.score({
traceId: trace.id,
name: "has-pricing",
value: score ? 1 : 0,
dataType: "BOOLEAN",
comment: "檢查是否包含價格資訊",
});
await langfuse.flushAsync();
console.log("✅ 自訂評分完成,分數:", score);
}
(async () => {
await customAPIScoring();
})();
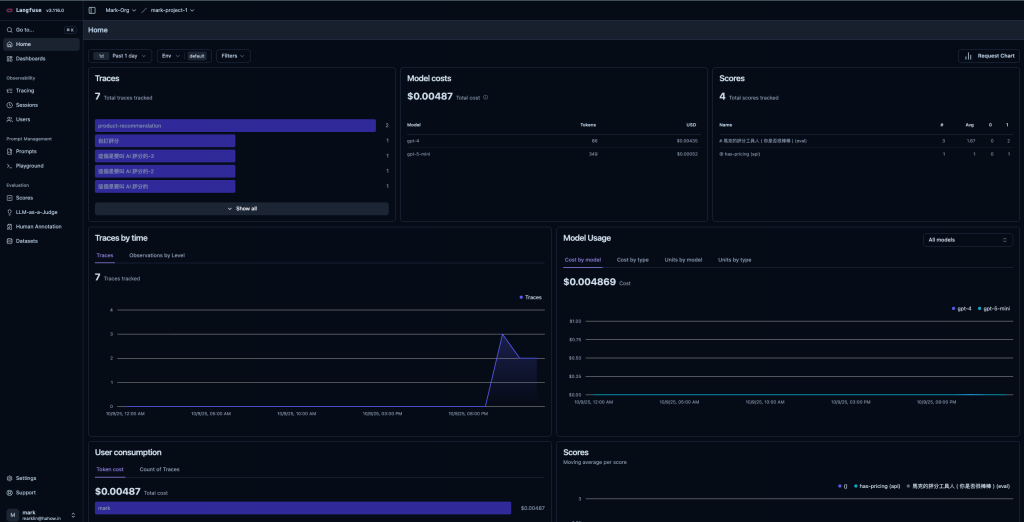
在 Langfuse 看到的結果如下圖。

注意,它只提到以下三種 dataType
這篇文章我們學會了如何評估 AI Application 的方式,然後有以下三種 :
並且也知道如何透過 langfuse 來實現它,接下來我們將會來說明評估指標的東西。
