
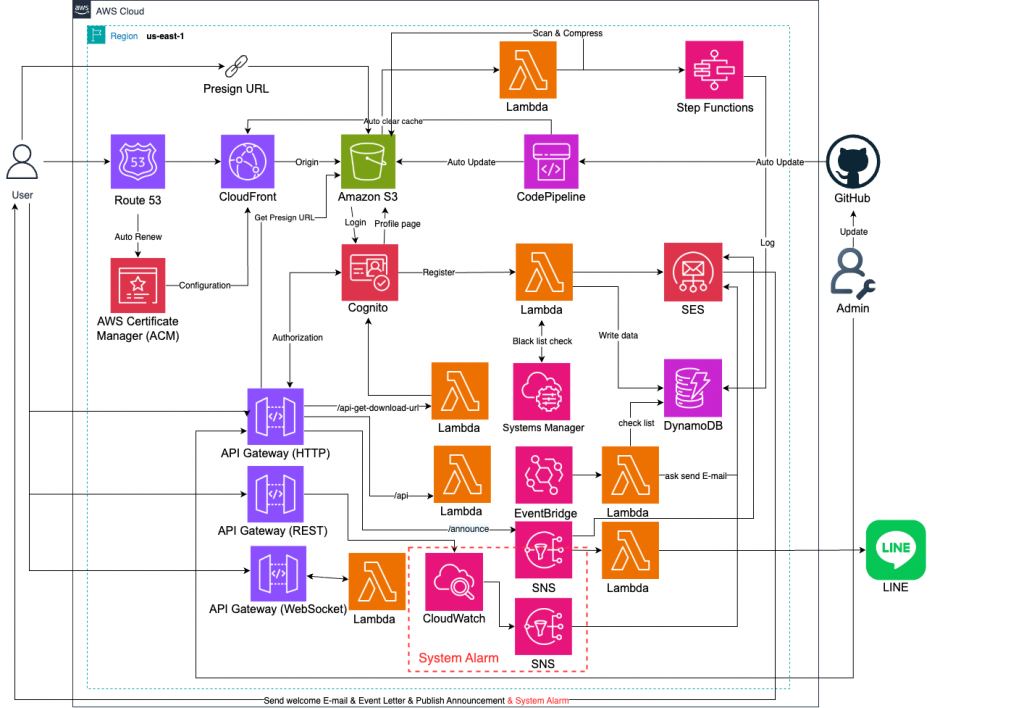
在 Serverless 架構下,應用程式雖然免除了傳統伺服器的維運負擔,但仍需持續監控健康狀態,否則使用者體驗會受到影響。當流量異常、API 錯誤率過高或延遲增加時,若能透過 CloudWatch Alarms 自動觸發通知,便能快速應對,降低業務中斷風險。
這個 Lab 的重點是 監測與告警。前面我們已建立會員系統、API Gateway、DynamoDB、S3 與 Cognito 等模組,而這些服務需要監控健康狀態。本篇將透過 CloudWatch Alarms 對 API 延遲、Lambda 錯誤率、DynamoDB 吞吐量 設定警報,並串接 SNS 發送通知,成為系統健康維護的基礎。
💡正常應設定5XX錯誤(伺服器端錯誤)為告警,因為4XX錯誤為用戶端錯誤,但本次基於「可測試」的原則,5XX錯誤為系統問題,此狀況在全託管的Serverless架構中通常不能體現,故這邊以4XX錯誤為範例來實作。
進入「SNS」頁面。
創建一個新的主題(Topic)。
選擇「標準」,命名並創建。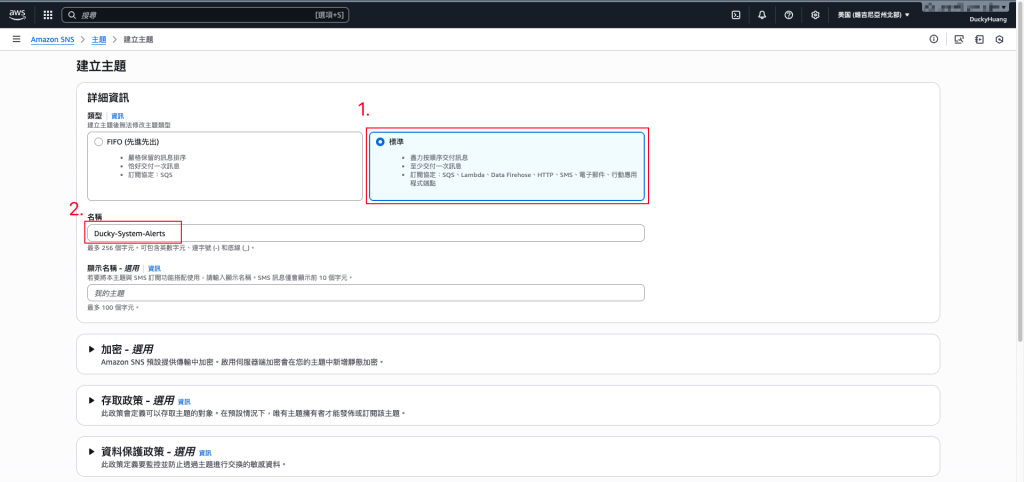
完成畫面。
新增訂閱。
選擇「電子郵箱」,並填入已經驗證過SES的E-mail。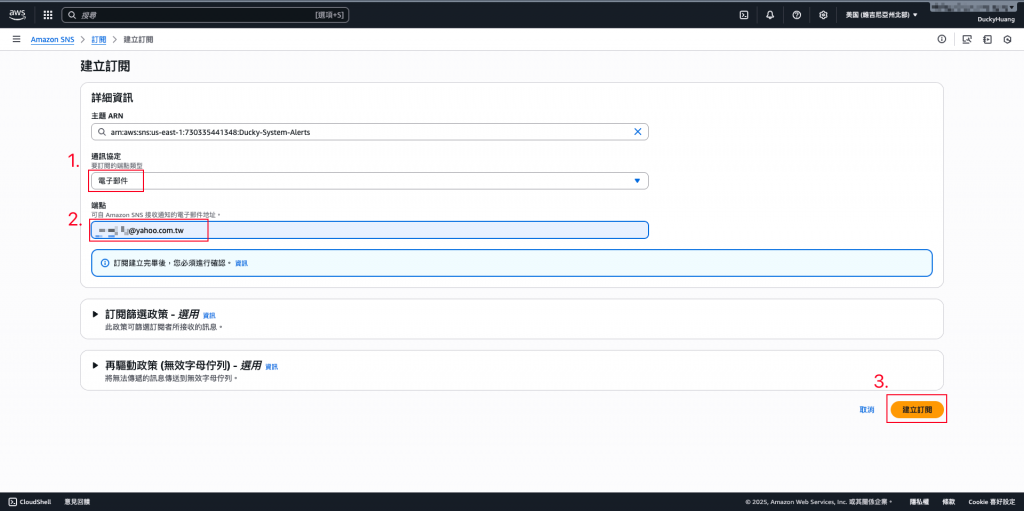
至信箱收取驗證信,並點擊連結做驗證。
點擊後,會出現驗證成功的畫面。
回到頁面,重新整理後,就會看到驗證已確認。
進入「CloudWatch」頁面。
創建「警示」。
選擇指標。
指標設定為「API Gateway」。
用名稱來選用API Gateway。
選擇指定的API Gateway的4xx錯誤碼。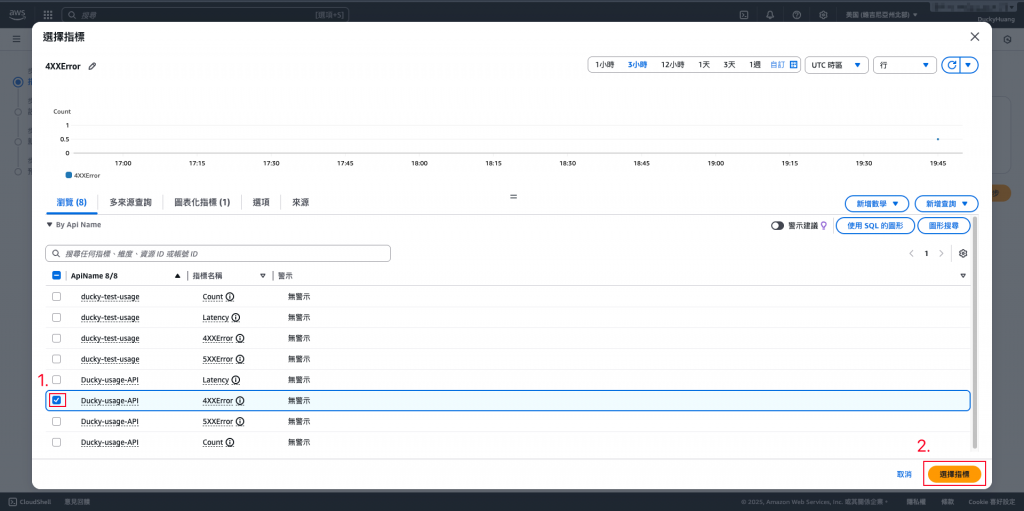
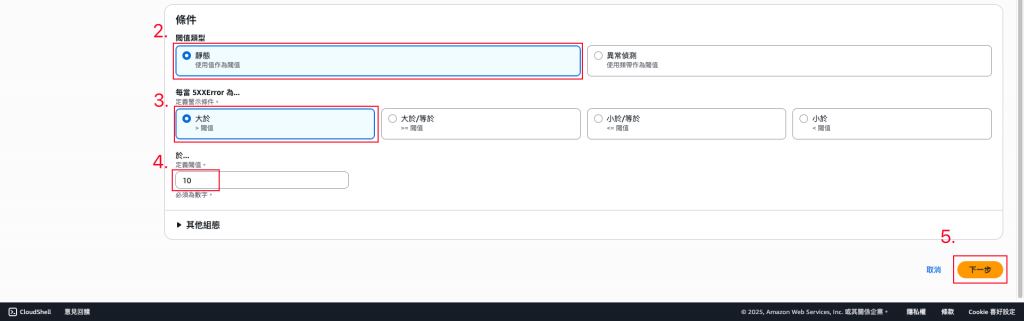
設定觸發警示的閥值。(此範例為:超過「10次/5分鐘」將被觸發)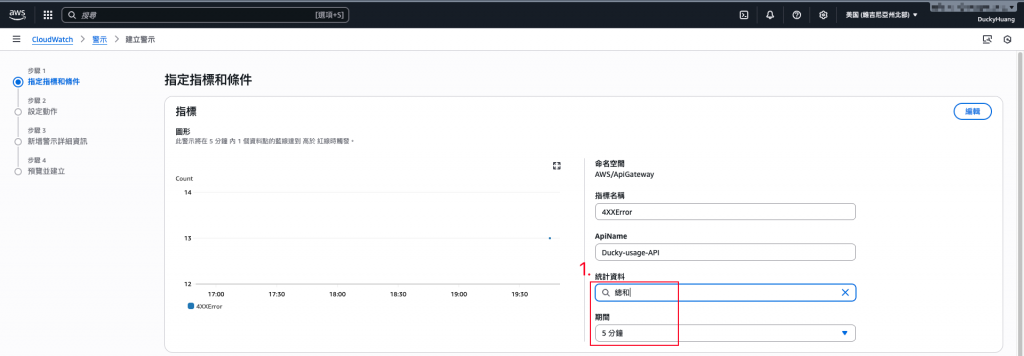
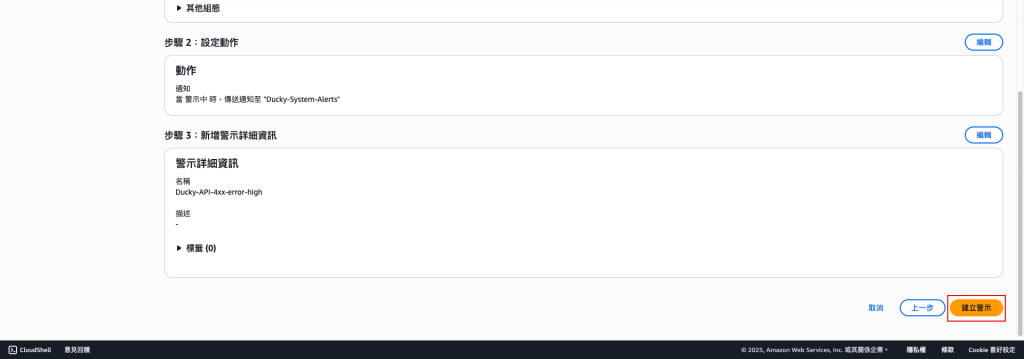
設定觸發後的動作為指定的SNS主題(Topic)。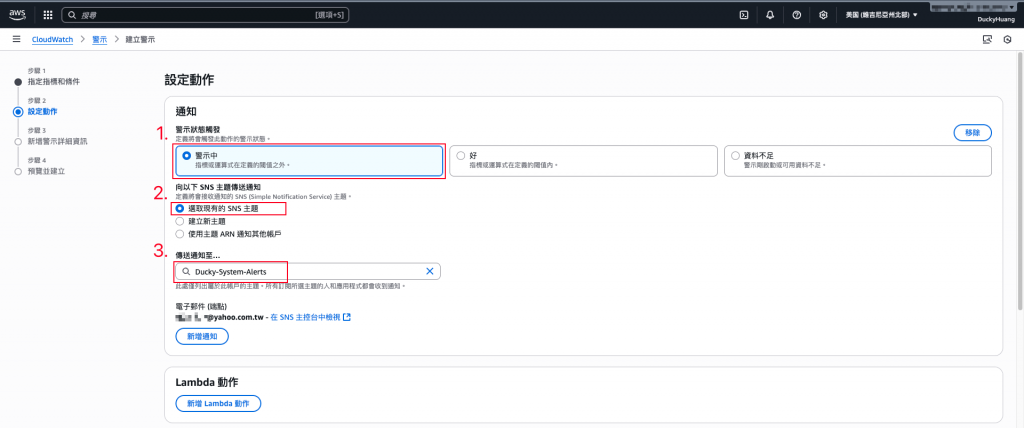
設定名稱。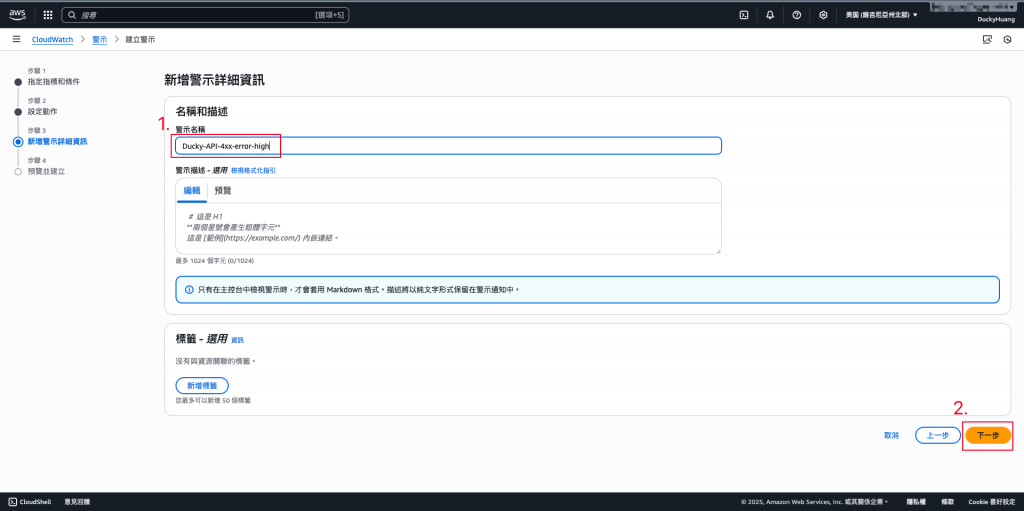
確認創建。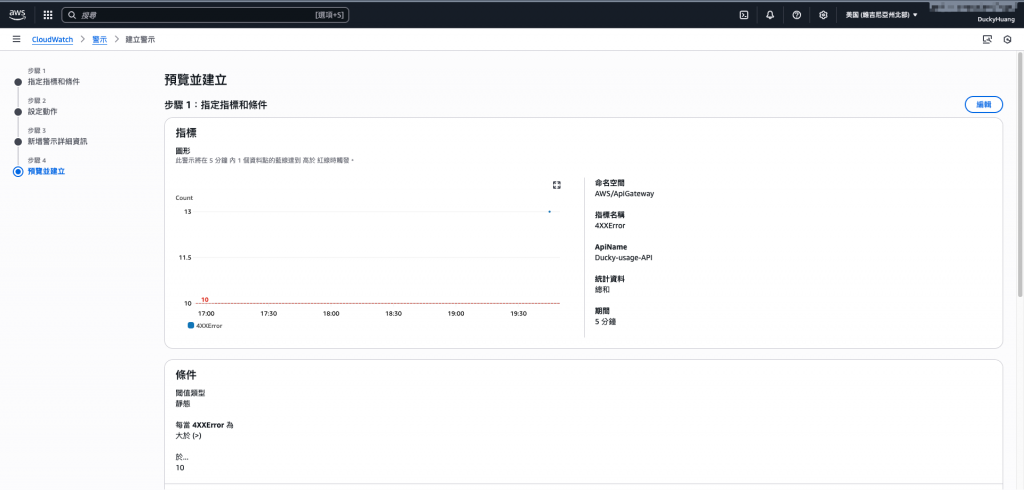
完成畫面。
發送4xx錯誤。
API URL在哪裡?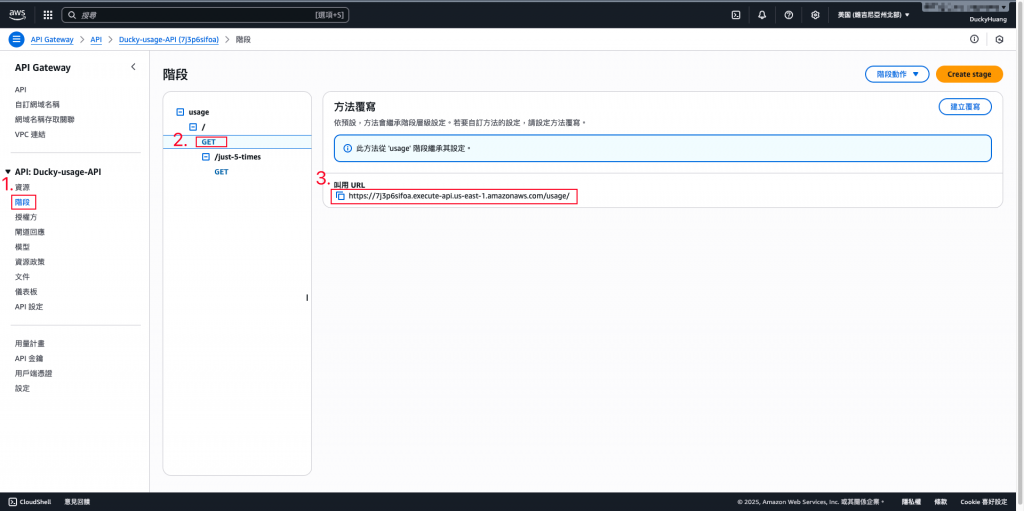
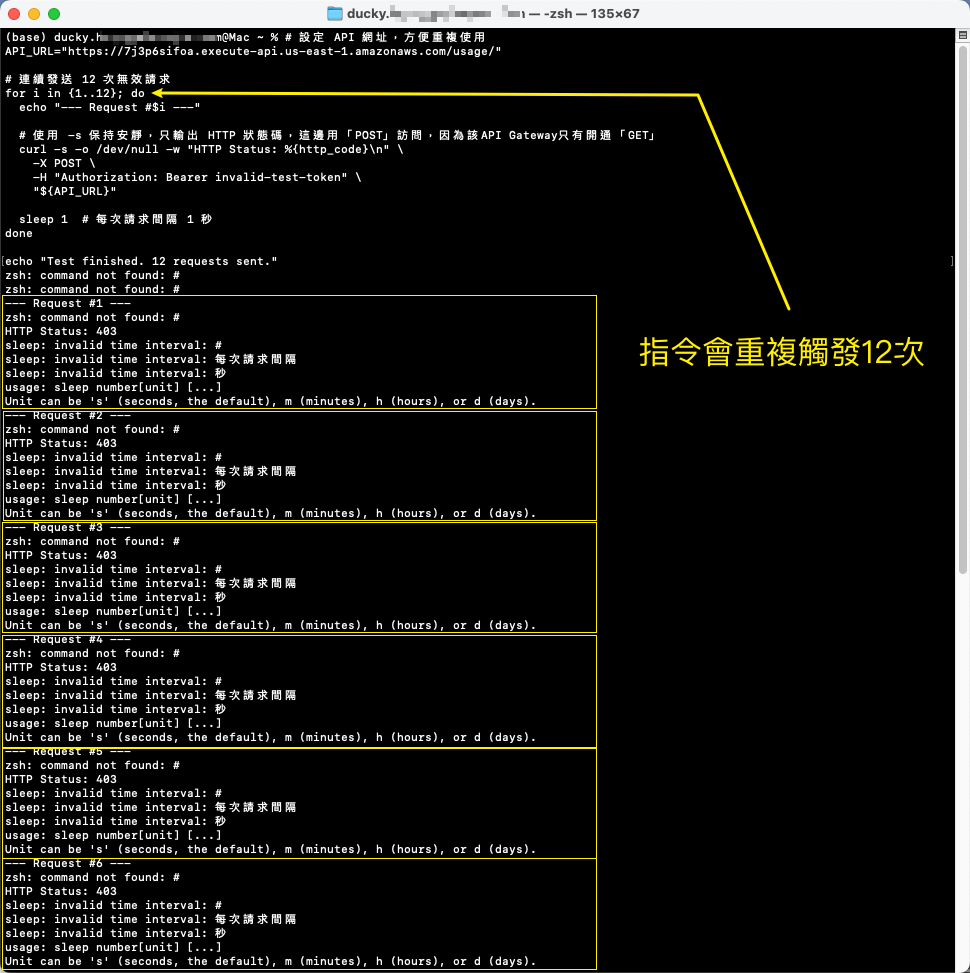
範例指令:
# 設定 API 網址,方便重複使用
API_URL="<API_URL>"
# 連續發送 12 次無效請求
for i in {1..12}; do
echo "--- Request #$i ---"
# 使用 -s 保持安靜,只輸出 HTTP 狀態碼,這邊用「POST」訪問,因為該API Gateway只有開通「GET」
curl -s -o /dev/null -w "HTTP Status: %{http_code}\n" \
-X POST \
-H "Authorization: Bearer invalid-test-token" \
"${API_URL}"
sleep 1 # 每次請求間隔 1 秒
done
echo "Test finished. 12 requests sent."
確認CloudWatch上,「警示」是否有被觸發。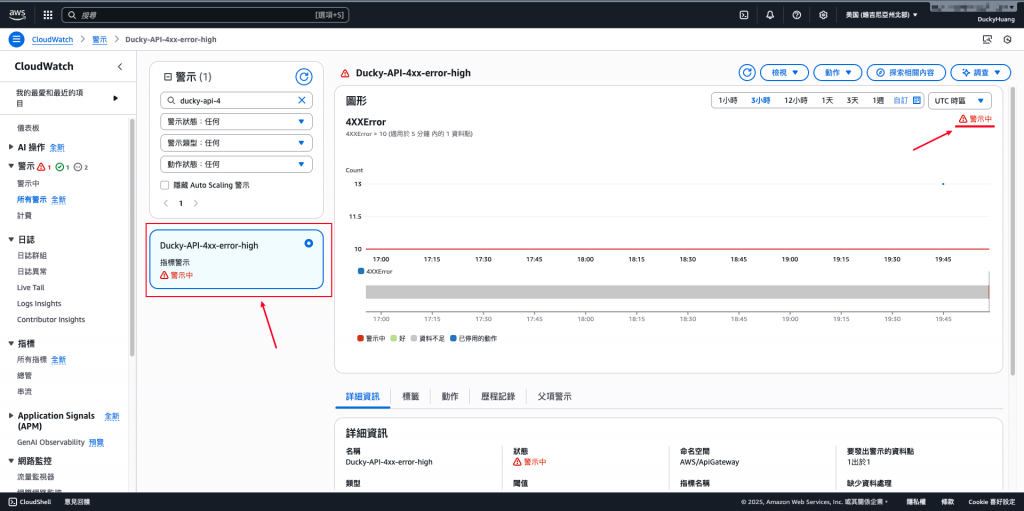
確認CloudWatch中,「警示中」的項目。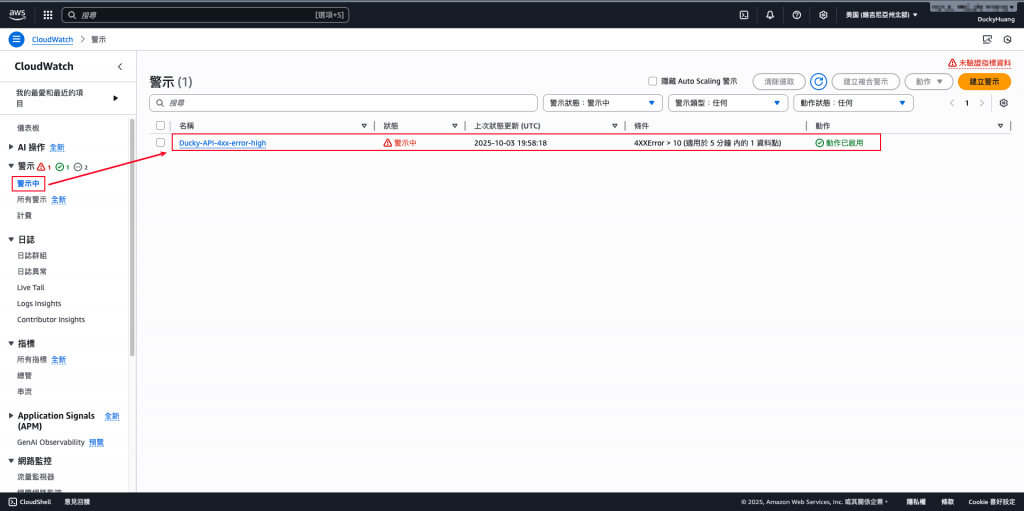
收到SNS的告警信件。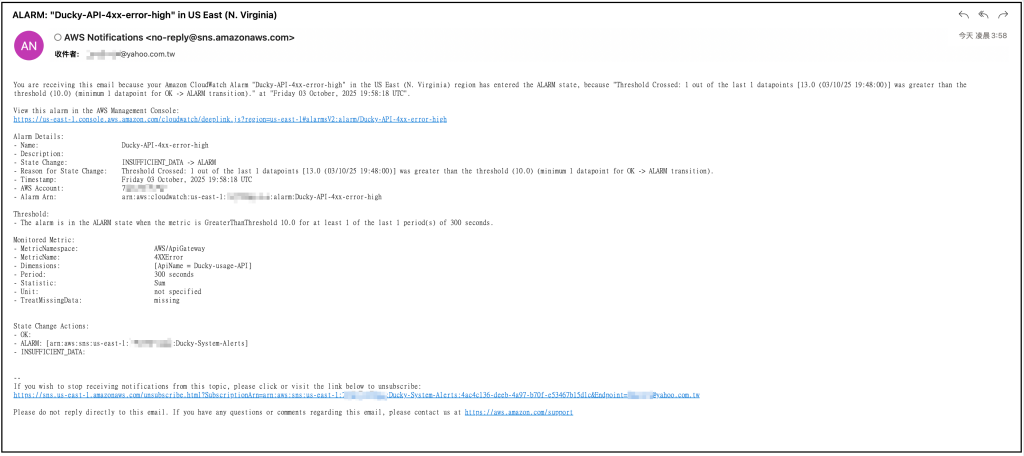
點選刪除告警。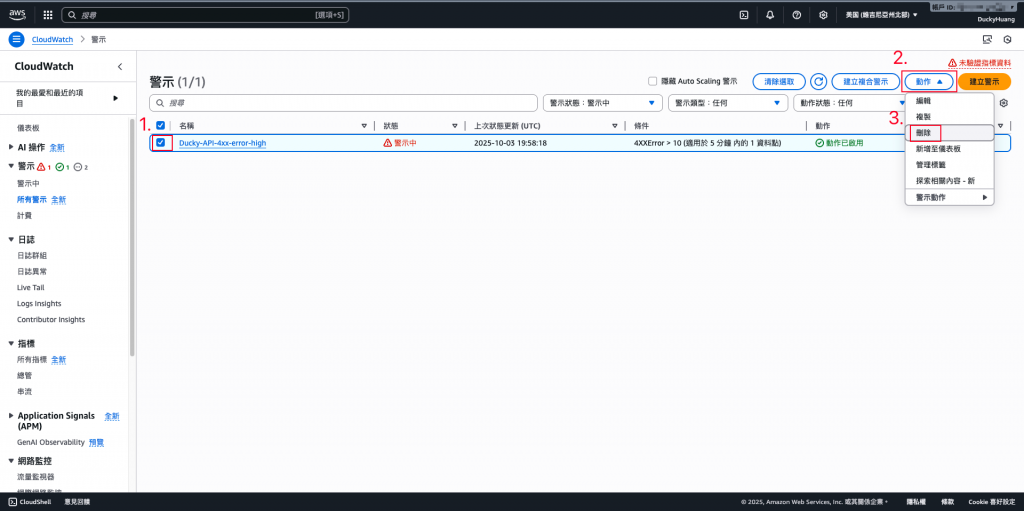
確認刪除。(刪除後會是「整個『警示』被刪除」,不是僅刪除「警示中」狀態)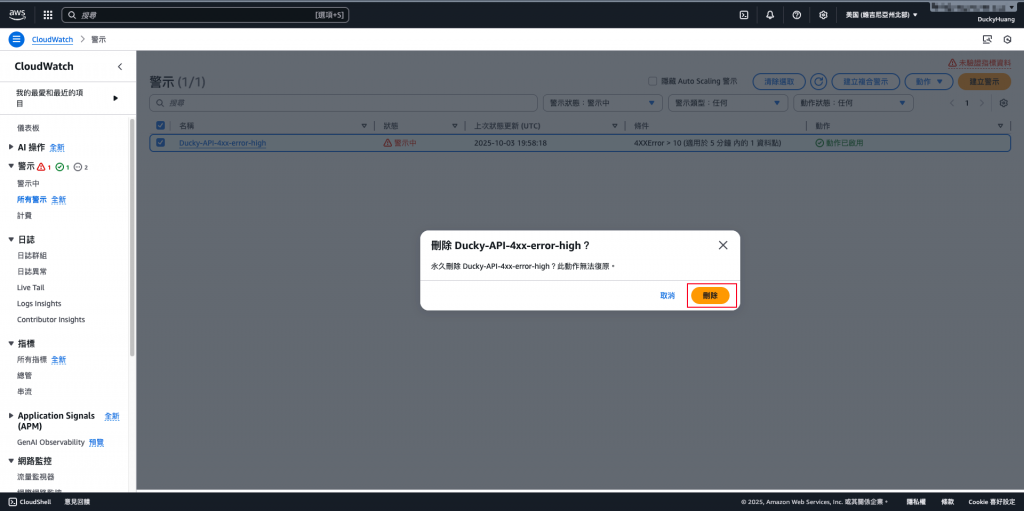
今天的 Lab 展示了如何透過 CloudWatch Metrics + Alarms + SNS 建立自動化的健康監測機制。這讓整個 Serverless 架構具備「自我監控」能力,不僅能及時通知問題,也能透過自動修復流程降低故障影響。未來可以進一步結合 CloudWatch Synthetics 模擬使用者行為,打造更完整的可觀測性方案。

