

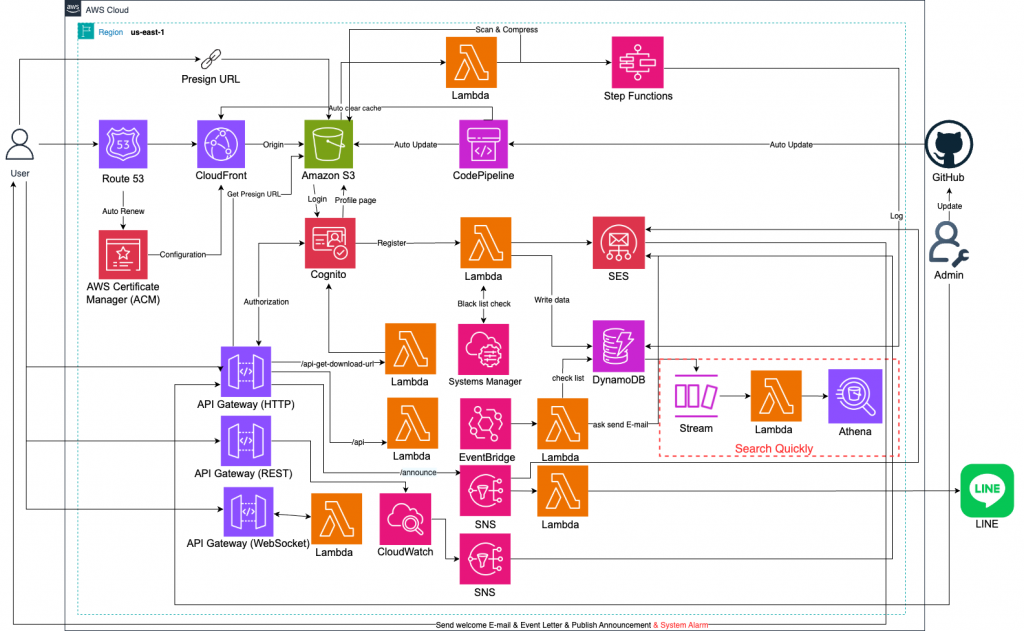
在會員系統或應用服務中,DynamoDB 通常扮演交易與即時讀寫的角色,但若需要進行歷史數據查詢、商業分析或批次報表,DynamoDB 並不適合直接使用。透過 DynamoDB Streams,我們可以即時捕捉資料變更,將其匯出到 S3 Data Lake,再利用 Athena 查詢,讓即時資料與分析需求兩者兼顧。
這個 Lab 解決了 DynamoDB 查詢受限的痛點。DynamoDB 適合 OLTP(即時交易處理),但在分析場景(OLAP)中,Scan 成本高且效能差。透過 Streams → Lambda → S3,資料會自動備份並轉換為查詢友好的格式(例如 Parquet/JSON/CSV),再透過 Athena SQL 查詢,建立一個低成本的分析環境,補足 DynamoDB 的不足。

NEW_AND_OLD_IMAGES)。進入「DynamoDB」頁面。
進入最初創建的資料表「userId」內。
進入 「匯出和串流 (Exports and streams)」 頁籤,並在「DynamoDB串流」選擇「編輯」。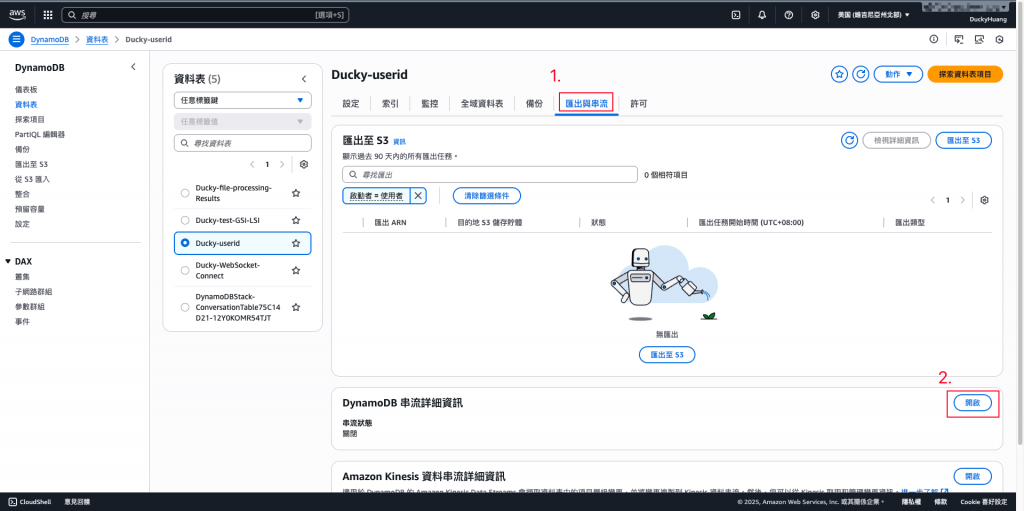
串流檢視類型 (Stream view type):選擇 NEW_AND_OLD_IMAGES (包含變更前後的完整資料),並點選「開啟串流」。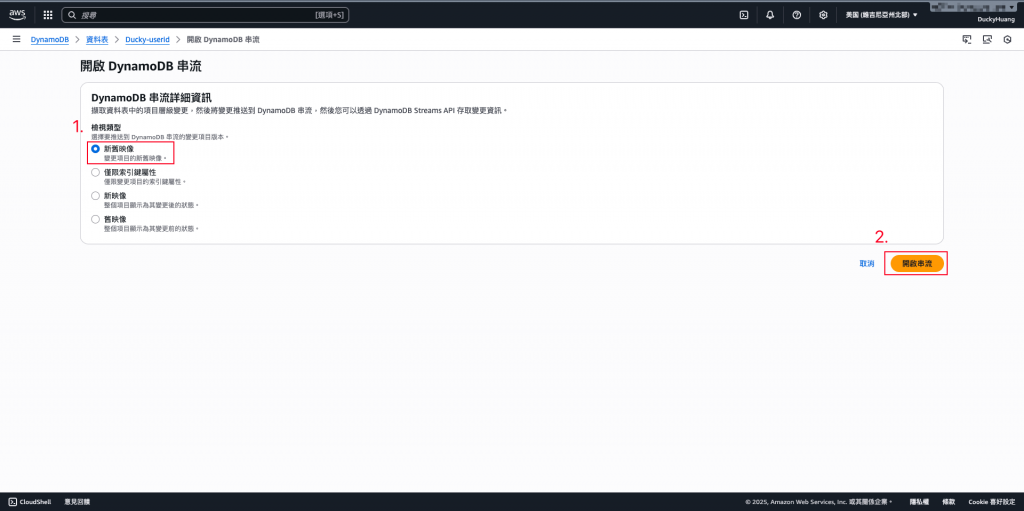
完成畫面。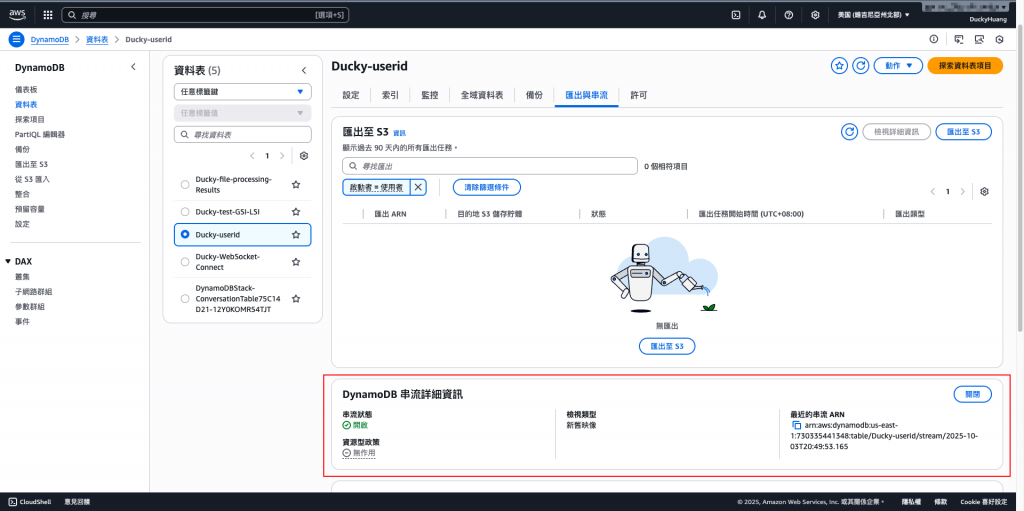
進入「Lambda」頁面。
創建一個新的函數。
輸入函數名稱,並選擇編撰語言。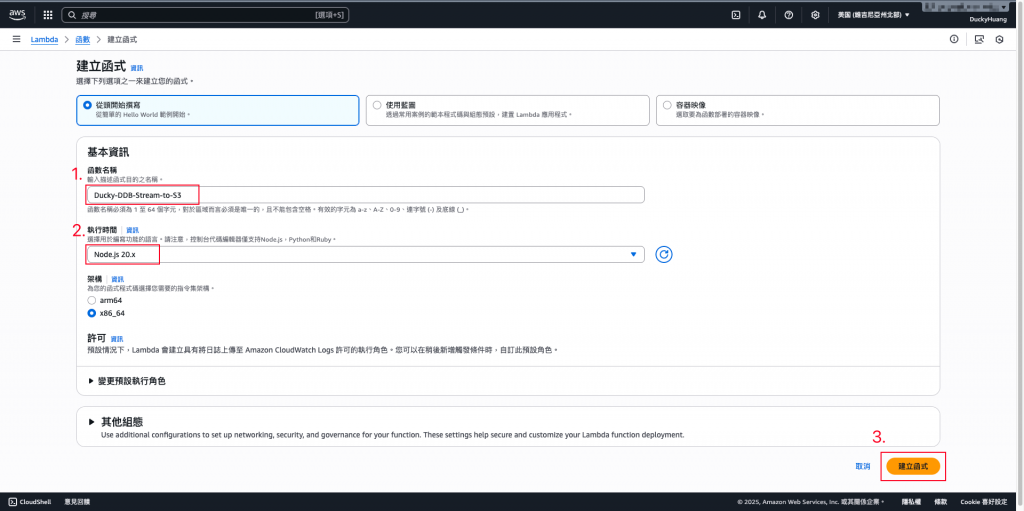
跳過建議畫面。
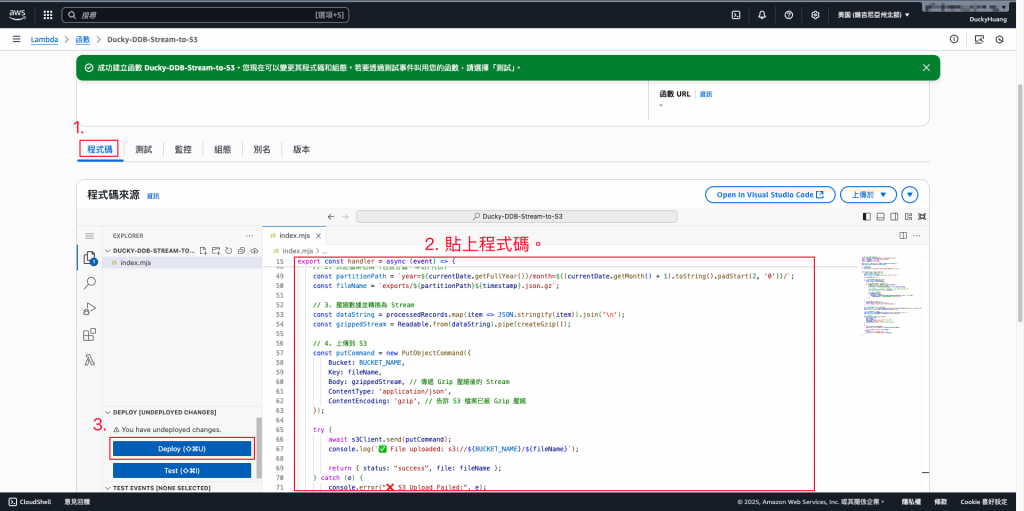
寫入程式碼,並部署。
範例程式碼
// index.mjs
import { S3Client, PutObjectCommand } from "@aws-sdk/client-s3";
import zlib from "zlib";
const s3 = new S3Client({ region: process.env.AWS_REGION });
const BUCKET_NAME = process.env.EXPORT_BUCKET;
function unmarshallDDB(ddbRecord) {
const json = {};
for (const key in ddbRecord) {
const val = ddbRecord[key];
if (val.S !== undefined) json[key] = val.S;
else if (val.N !== undefined) json[key] = Number(val.N);
else if (val.BOOL !== undefined) json[key] = val.BOOL;
else if (val.NULL !== undefined) json[key] = null;
else if (val.M !== undefined) json[key] = unmarshallDDB(val.M);
else if (val.L !== undefined) json[key] = val.L.map(unmarshallDDB);
}
return json;
}
export const handler = async (event) => {
const now = new Date();
const timestamp = now.toISOString().replace(/[:.]/g, "-");
const records = [];
for (const record of event.Records) {
if (["INSERT", "MODIFY", "REMOVE"].includes(record.eventName)) {
const dataImage = record.dynamodb.NewImage || record.dynamodb.OldImage || {};
const parsed = unmarshallDDB(dataImage);
records.push({
event_name: record.eventName,
timestamp: record.dynamodb.ApproximateCreationDateTime,
user_id: parsed.userId,
email: parsed.email,
});
}
}
if (records.length === 0) {
console.log("No records to process.");
return { status: "no_data" };
}
// ✅ 每行一筆 JSON,而非整個 array
const ndjson = records.map((r) => JSON.stringify(r)).join("\n");
const compressed = zlib.gzipSync(ndjson);
const partitionPath = `year=${now.getUTCFullYear()}/month=${String(
now.getUTCMonth() + 1
).padStart(2, "0")}/`;
const fileName = `exports/${partitionPath}${timestamp}.json.gz`;
await s3.send(
new PutObjectCommand({
Bucket: BUCKET_NAME,
Key: fileName,
Body: compressed,
})
);
console.log(`✅ Uploaded NDJSON to s3://${BUCKET_NAME}/${fileName}`);
return { status: "success", file: fileName };
};
進入「組態」分頁,設定環境變數,EXPORT_BUCKET:bucket name。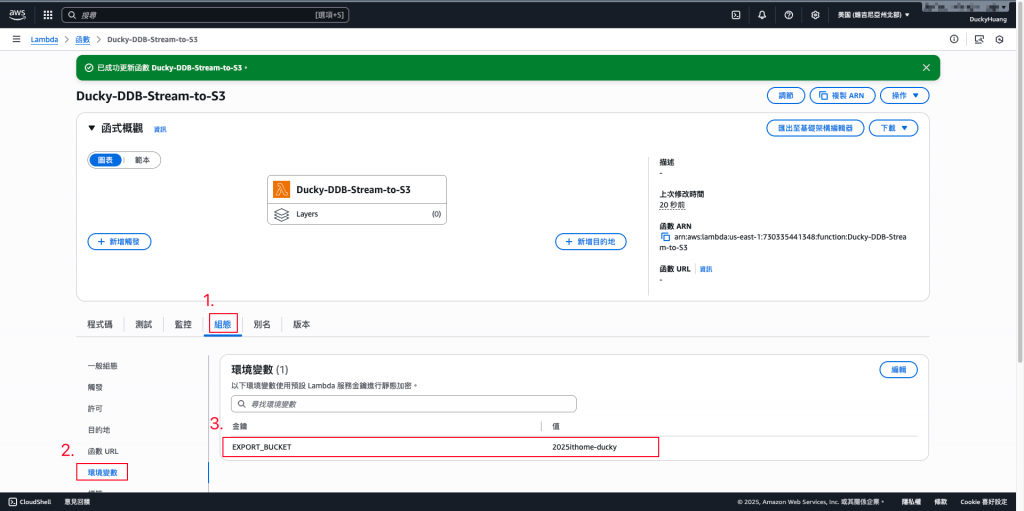
進入「IAM 」頁面。
進入IAM role的頁面,點選該Lambda自動創建的IAM role。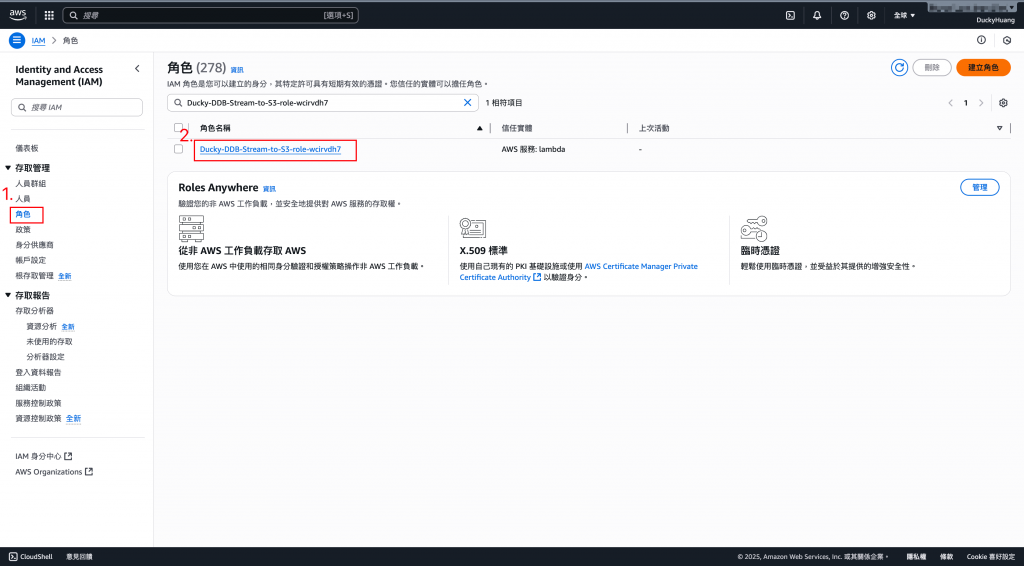
新增「許可政策」。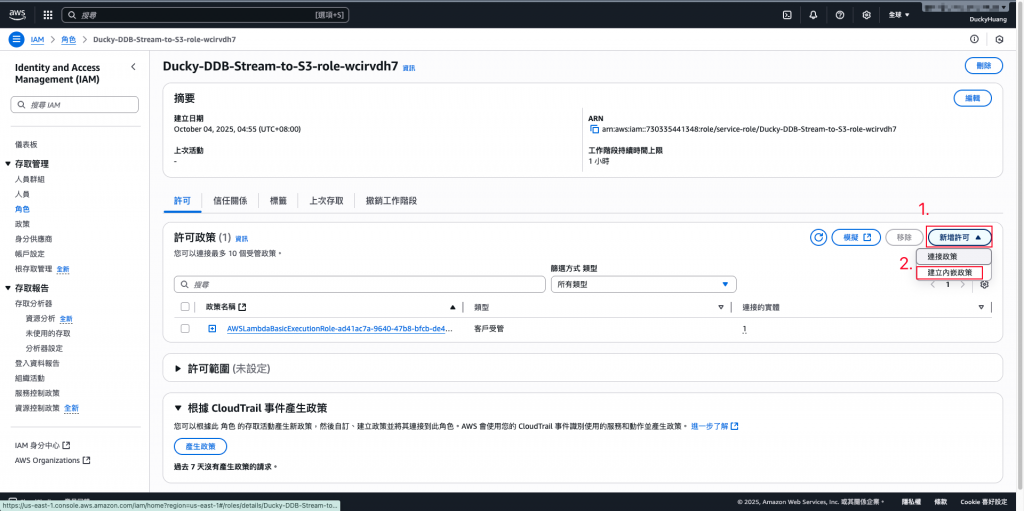
增加以下權限,授權資源為「所有資源」。
logs:CreateLogStream
logs:CreateLogGroup
logs:PutLogEvents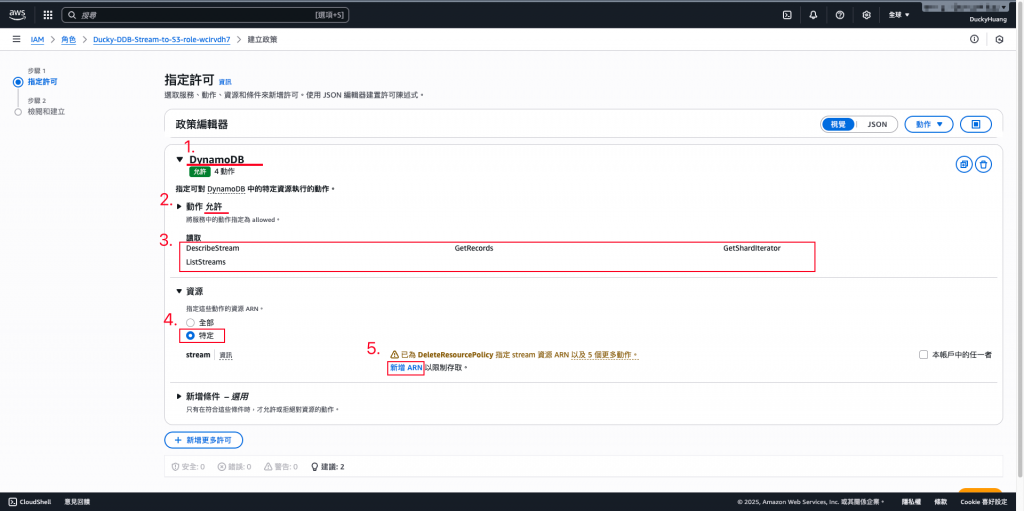
增加以下權限,授權資源為「指定資源(DynamoDB、S3 bucket)」。
s3:PutObject
s3:PutObjectAcl
dynamodb:GetShardIterator
dynamodb:DescribeStream
dynamodb:GetRecords
dynamodb:ListStreams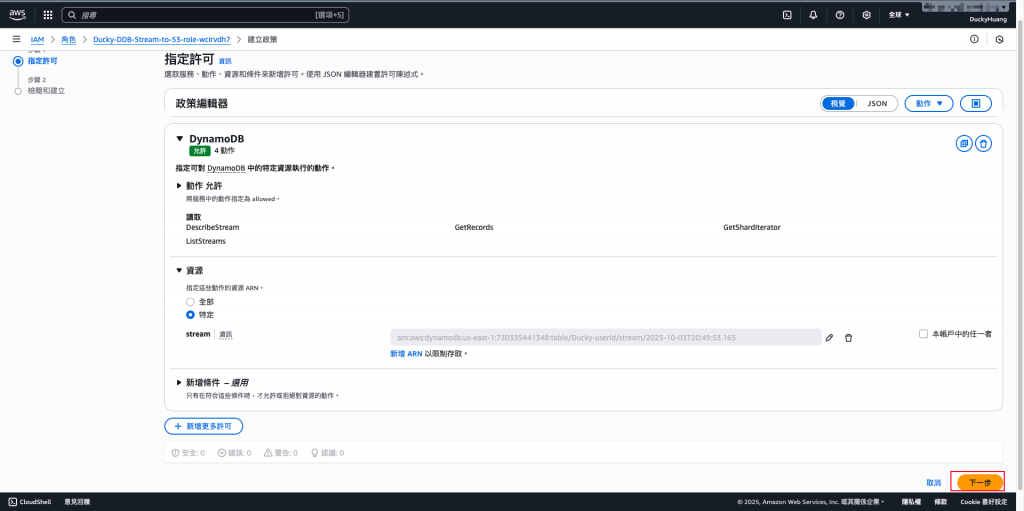
授權資源為「指定資源(DynamoDB」。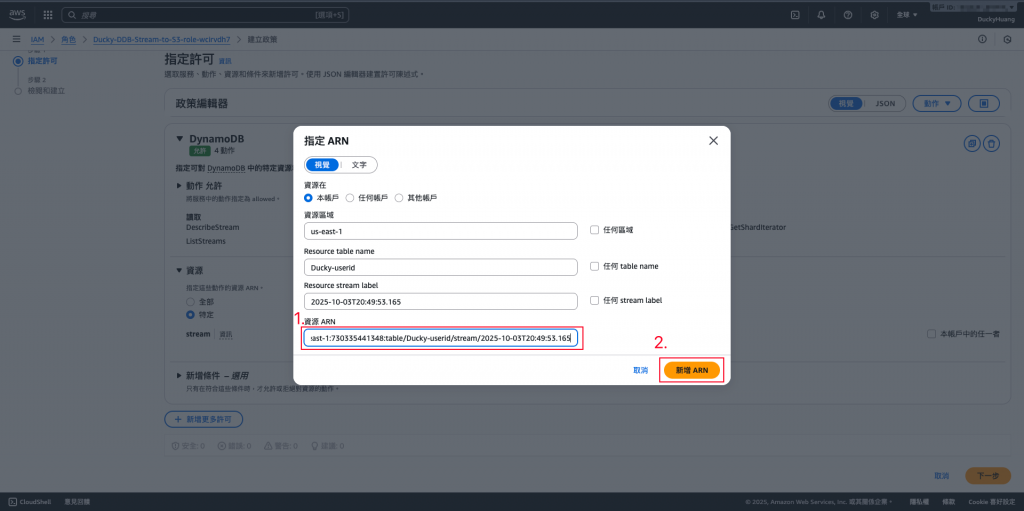
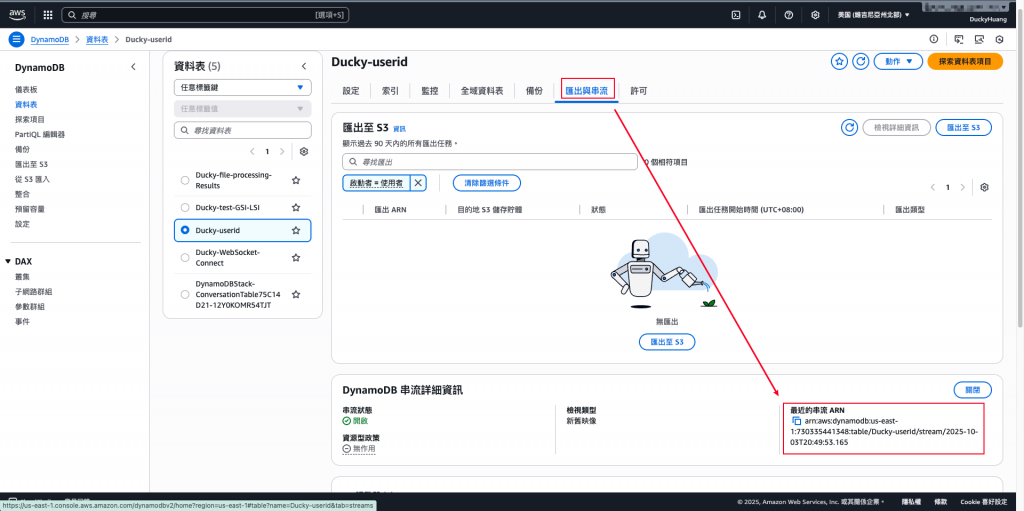
設定「許可政策」名稱。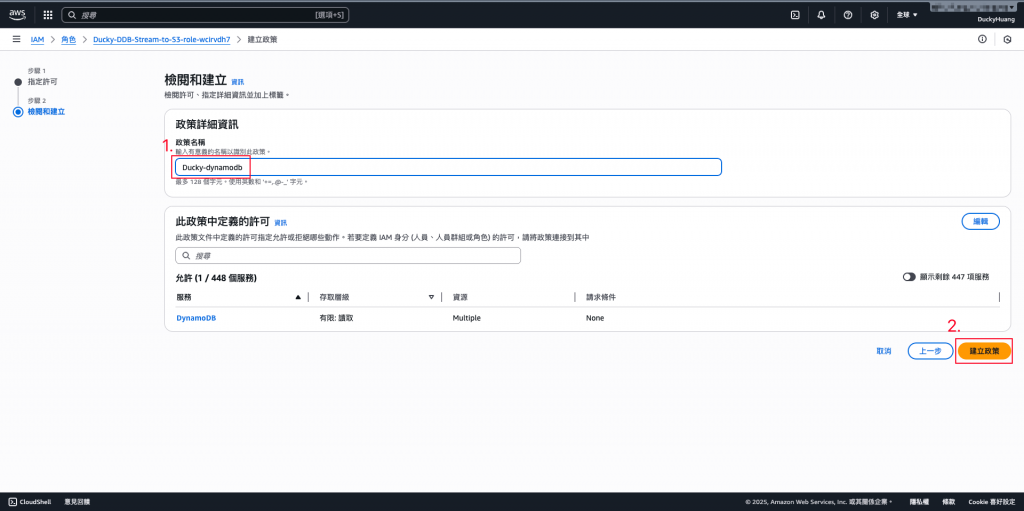
完成畫面。
進入「DynamoDB」後,進入「匯出與串流」頁面,新增一個「觸發器」。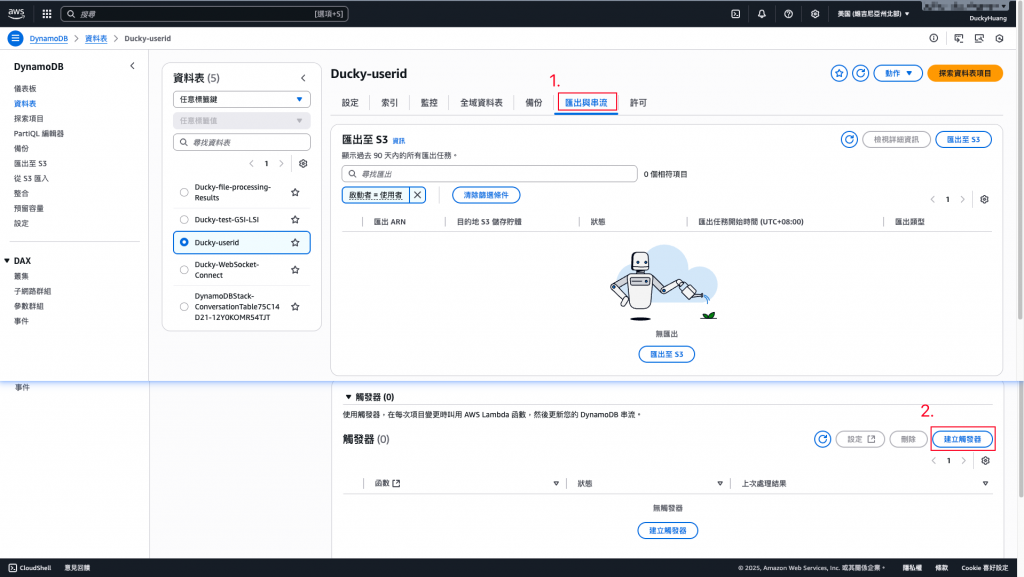
串接觸發器為前面建立的Lambda函數。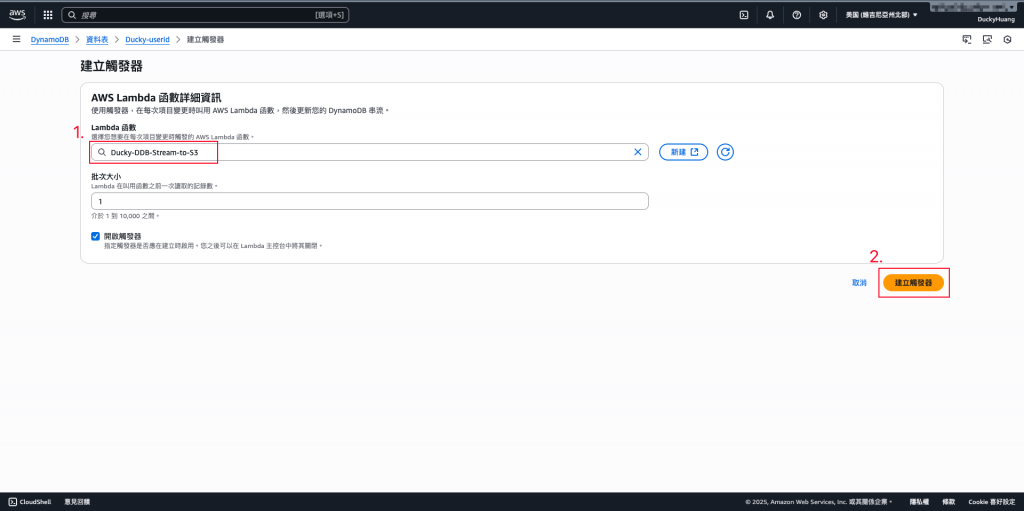
串接完成畫面。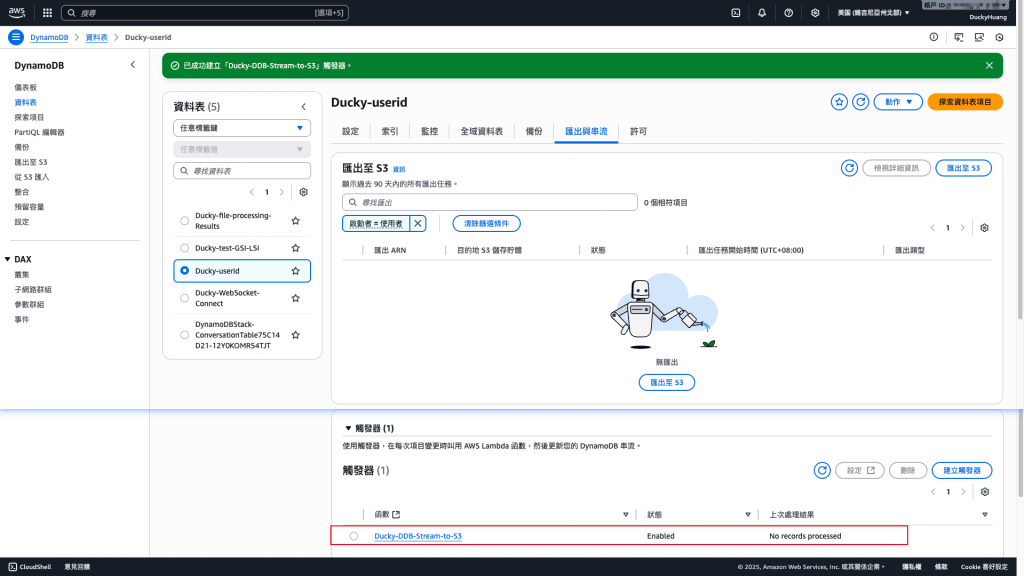
進入「Amazon Athena」頁面。
進入「設定」頁面。
貼上要查詢的S3檔案路徑。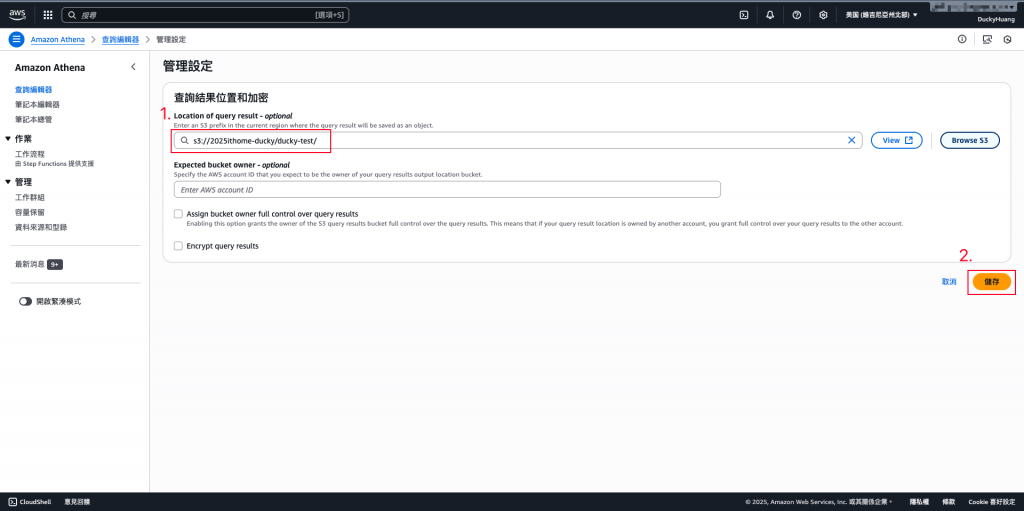
用SQL語法建立資料庫。
程式碼範例
CREATE DATABASE IF NOT EXISTS analytics_db;
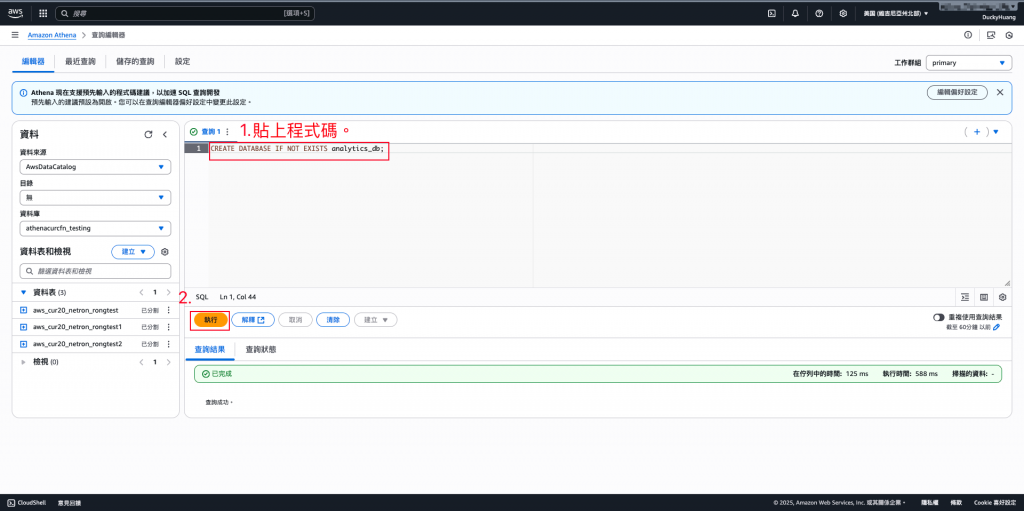
完成畫面。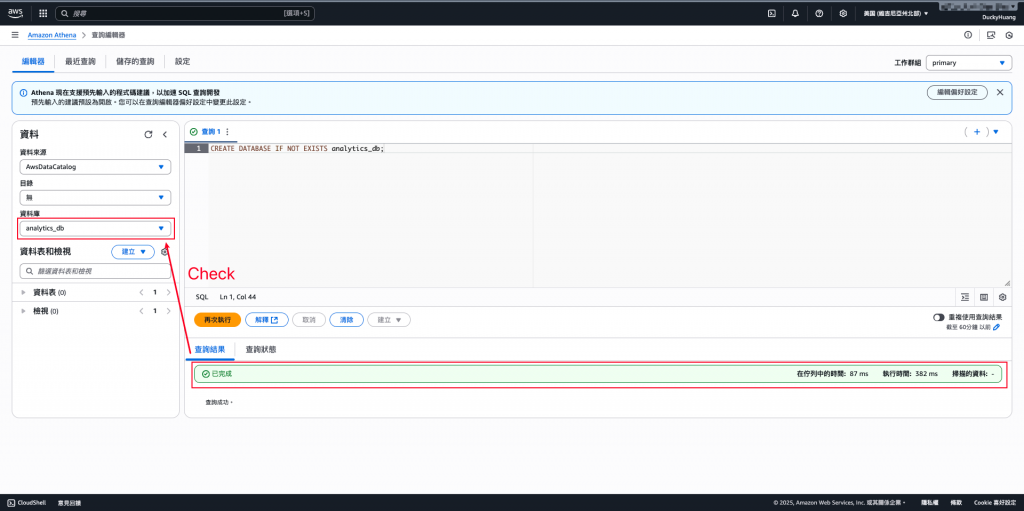
建立外部資料表 (External Table):SQL
CREATE EXTERNAL TABLE IF NOT EXISTS analytics_db.dynamodb_users (
`event_name` string,
`timestamp` bigint,
`userId` string,
`email` string
)
PARTITIONED BY (
`year` string,
`month` string
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.null.format' = 'null'
)
LOCATION 's3://<your_bucket_name>/<path>/'
TBLPROPERTIES (
'compressionType' = 'gzip',
'classification' = 'json'
);
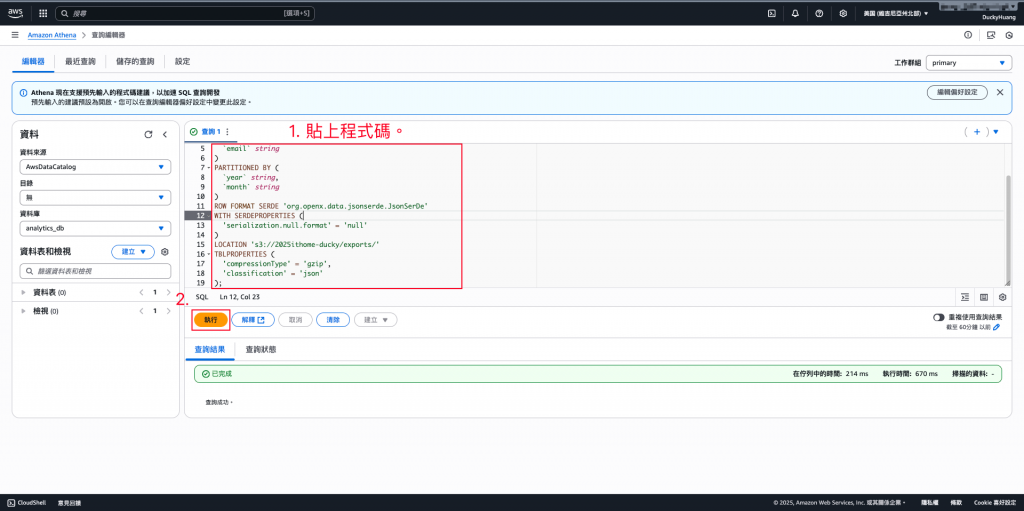
完成創建。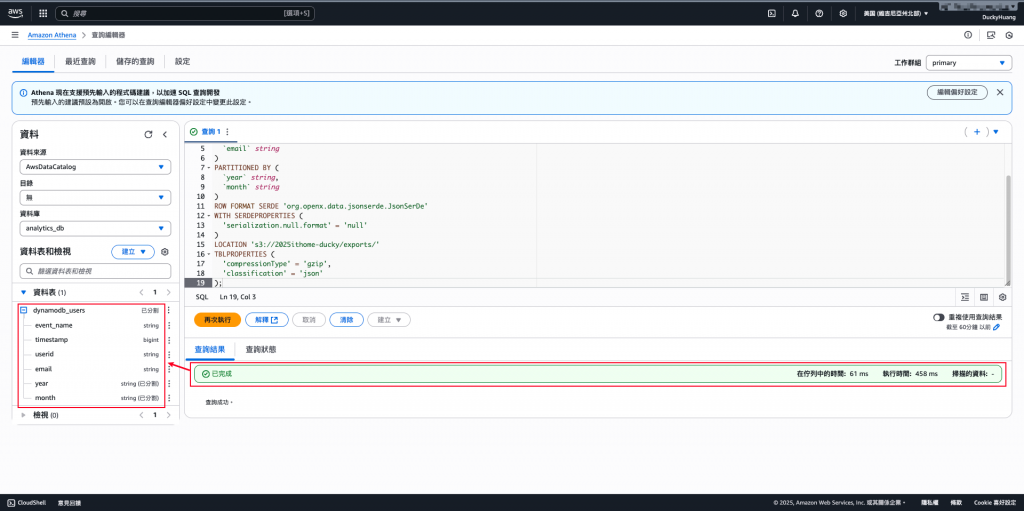
💡在 DynamoDB Console 中,手動對 Users 表格插入、修改或刪除一筆資料。
進入DynamoDB的「探索項目」頁面,透過之前的頁面複製一筆新的資料。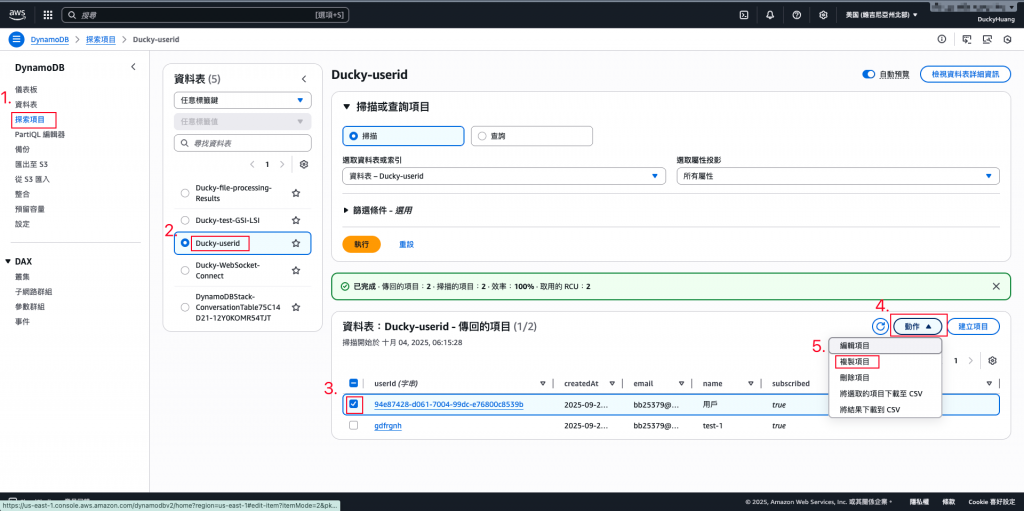
輸入要新增的測user資料。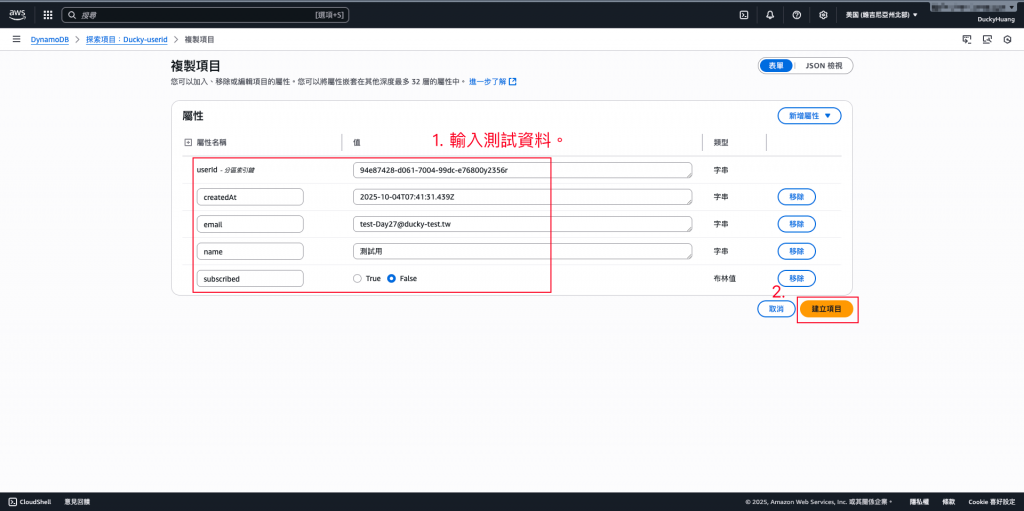
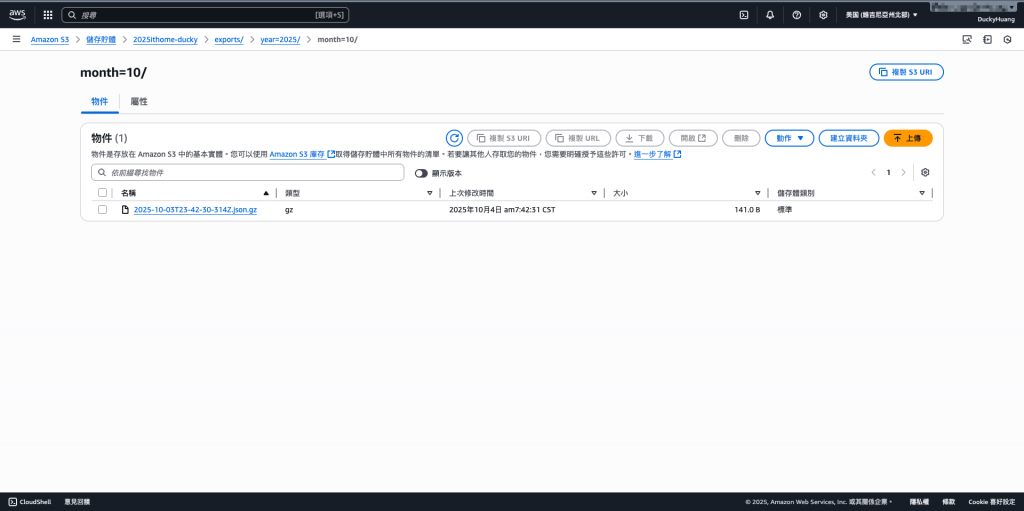
dynamodb-export-data-2025-lab,確認 exports/year=YYYY/month=MM/ 路徑下是否有 .json.gz 檔案出現。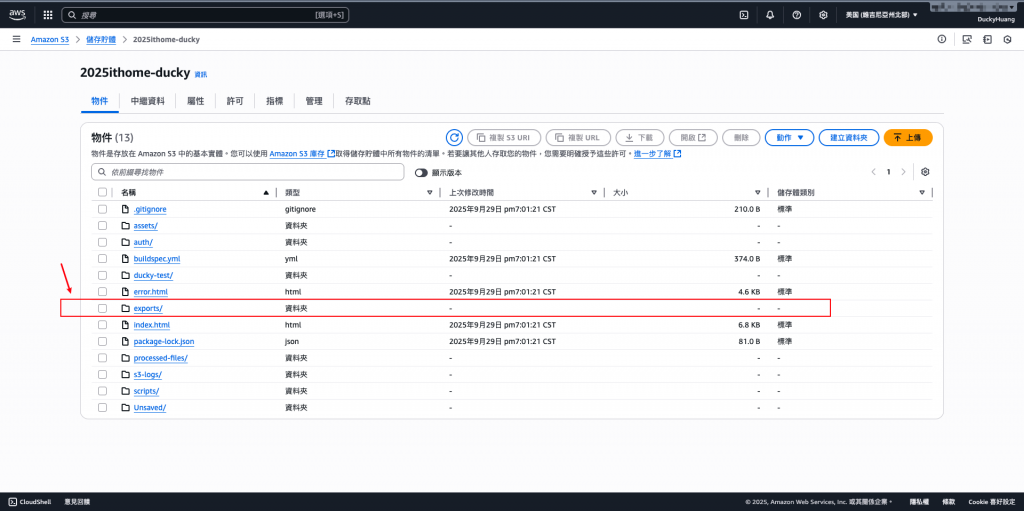
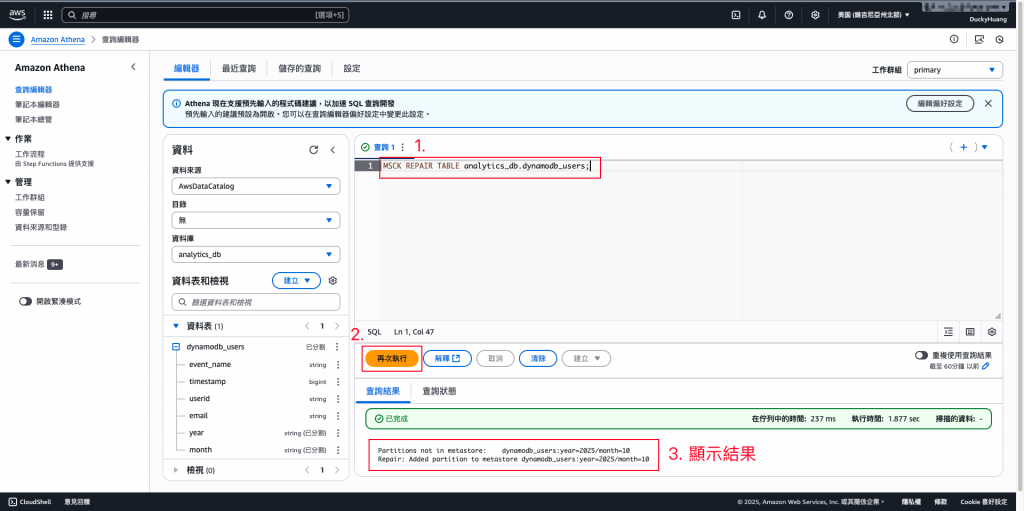
在 Athena 中,執行以下查詢來載入分區:SQL
MSCK REPAIR TABLE analytics_db.dynamodb_users;
執行查詢:SQL,驗證查詢結果中是否包含您剛才在 DynamoDB 中新增或修改的數據。
SELECT event_name, user_id, email, timestamp
FROM analytics_db.dynamodb_users
WHERE year='2025' AND month='10'
LIMIT 10;
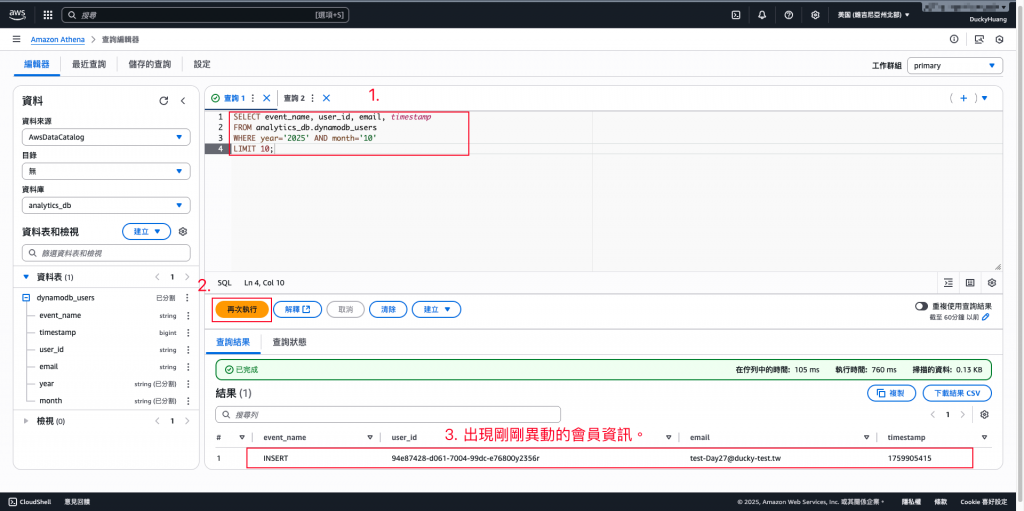
刪除資料表:
DROP TABLE analytics_db.dynamodb_users;
刪除資料庫:
DROP DATABASE IF EXISTS analytics_db;
今天的 Lab 展示了如何透過 DynamoDB Streams → Lambda → S3 → Athena,將 DynamoDB 中的交易資料遷移到 Data Lake,並利用 SQL 進行分析。這樣的架構解決了 DynamoDB 在分析上的限制,同時維持即時資料的一致性,讓應用不僅能支撐高流量,也能提供完整的數據洞察。
