使用 Hugging Face 的 llava-instruct-150k 作為範例(圖像-指令對)
from datasets import load_dataset
raw_datasets = load_dataset("HuggingFaceH4/llava-instruct-mix-vsft")
raw_datasets
(輸出結果,llava-instruct-150k資料集的格式:每一筆資料主要包含兩個欄位:image 和 messages)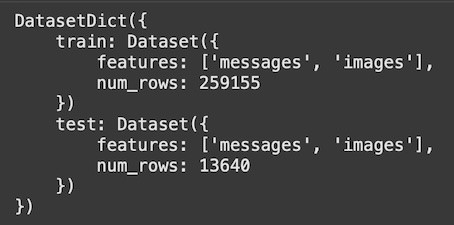
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]
# 練習用,只隨機選取一小部分資料做測試
small_train_dataset = train_dataset.shuffle(seed=42).select(range(int(len(train_dataset)*0.1)))
small_eval_dataset = eval_dataset.shuffle(seed=42).select(range(int(len(eval_dataset)*0.1)))
檢視資料內容
example = small_train_dataset[10]
images = example["images"]
images[0]

messages = example['messages']
messages
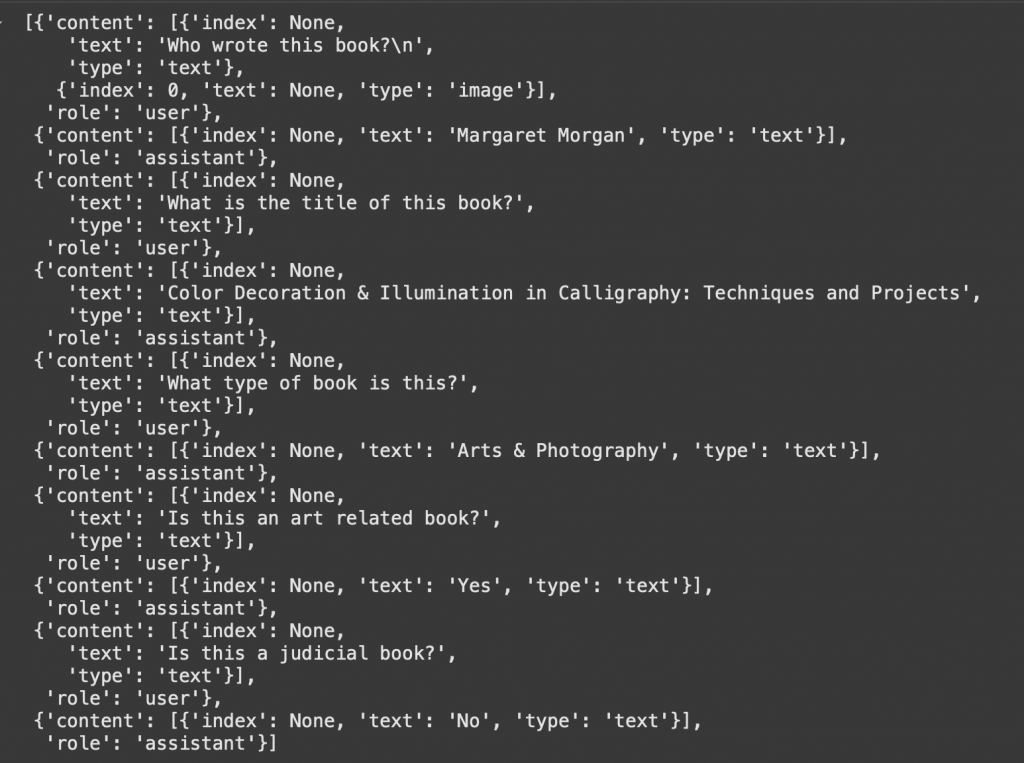
格式說明:資料集以 JSON-like 結構儲存,每筆樣本為一個字典,包含兩個主要欄位:images 與 messages
LLaVA 的對話格式需要符合特定的模板
修正:
格式 "USER: \n{question}\nASSISTANT: {answer}"
這個是LLaVA推理提示模板,但是微調訓練時不是這個格式!


 iThome鐵人賽
iThome鐵人賽