前言:當 Google NotebookLM 很香,但公司法務站在你後面...
最近 Google 的 NotebookLM 爆紅,把 PDF 丟進去就能生成 Podcast 真的很神。但身為一名在竹科打滾多年的 R&D 工程師,我第一反應不是「好用」,而是「恐懼」。
試想一下,如果我把公司的新產品電路圖 (Schematics)、未公開的測試數據,甚至是客戶的 NDA 合約上傳到 Google 雲端... 下一秒可能就會接到法務部門的電話了。
但 AI 讀檔檢索 (RAG) 的效率真的太誘人。於是我就想:「有沒有可能在『完全斷網』的情況下,用自己的顯卡跑一套私有的 NotebookLM?」
答案是肯定的。這週末我用 Docker + Ollama (Llama 3) + LangChain,手搓了一套**「完全本地部署」**的 AI 知識庫。沒有資料會離開我的電腦,連網路線拔掉都能跑。
這篇文章分享我的架構思路,以及我在處理「複雜工業規格書」時踩到的坑(這才是最痛的)。
系統架構:為何選擇 Docker?
很多教學會教你用 pip install 直接在電腦裝 Python 環境。相信我,過了一個月你的環境變數絕對會炸掉,尤其當你需要同時跑 CUDA 和其他專案時。
所以我採用 Container 化 的部屬方式:
大腦 (LLM): Ollama (跑 Meta Llama 3 8B 模型,CP 值最高的選擇)
記憶 (Vector DB): ChromaDB (儲存向量化的知識)
手腳 (App): Python + LangChain (處理邏輯)
介面 (UI): Streamlit 或簡單的 Web UI
最關鍵的設計是 「Bind Mount (資料夾綁定)」。我把主機桌面的一個資料夾 My_Secret_Docs 直接映射進 Docker。
好處是: 我只要把 PDF 拖進這個資料夾,Docker 裡的 AI 就會自動讀取。我不需要寫複雜的上傳網頁,資料也永遠留在我的硬碟裡。
核心配置 (docker-compose.yml)
這是我精簡後的設定檔,一鍵 docker-compose up -d 就能把整套環境拉起來:
YAML
version: '3.8'
services:
#1. AI 模型服務 (Ollama)
ollama:
image: ollama/ollama:latest
ports:
- "11434:11434"
volumes:
- ./ollama_data:/root/.ollama # 模型存在本地,不用每次重抓
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu] # 記得把顯卡 Pass-through 進去
#2. 應用程式 (RAG Logic)
app_server:
build: .
volumes:
- ./My_Secret_Docs:/app/data # 魔法資料夾:檔案丟這裡
- ./chroma_db:/app/db # 向量資料庫持久化
environment:
- OLLAMA_URL=http://ollama:11434
depends_on:
- ollama
實戰踩坑:AI 不是萬能的,它看不懂「工業型錄」
把環境架起來只是第一步(大概花 30 分鐘)。真正的挑戰是:資料清洗 (Data Cleaning)。
我在測試時餵了一份工業級的 風速計 (Anemometer) 規格書。結果發生了兩個災難:
「重量」誤判: 我問 AI 這顆感測器多重?它回答 3kg。但我看本體明明才 0.25kg。
原因: AI 讀到了型錄最後一頁的「選購配件表 (Accessories)」,把那根重死人的鐵支架 (Traverse) 當成了感測器本體。
「精度」讀不到: 另一顆感測器的精度是用「紅綠熱力圖」呈現的複雜表格。AI 直接兩手一攤說「文件中未提及」。
我的解法:工程師的手段
這就是為什麼我們不能只依賴「通用的」AI 工具。針對這種專業文件,我做了兩件事:
Prompt Engineering (提示詞工程): 我在 System Prompt 裡加了一條「防呆規則」:
規則加上一些必要條件,AI 馬上變聰明,回答:「感測器重量約 0.25kg(註:3kg 為選配支架重量)。」
Data Augmentation (手動資料增強): 對於那個讀不到的熱力圖,我沒有在那邊硬修 OCR。我直接寫了一個 specs.txt 純文字檔,把關鍵規格列出來,跟 PDF 一起丟進資料夾。 RAG 系統會優先檢索文字檔,瞬間解決了「看不懂圖片」的問題。
成果展示
現在,我的工作流變得很簡單: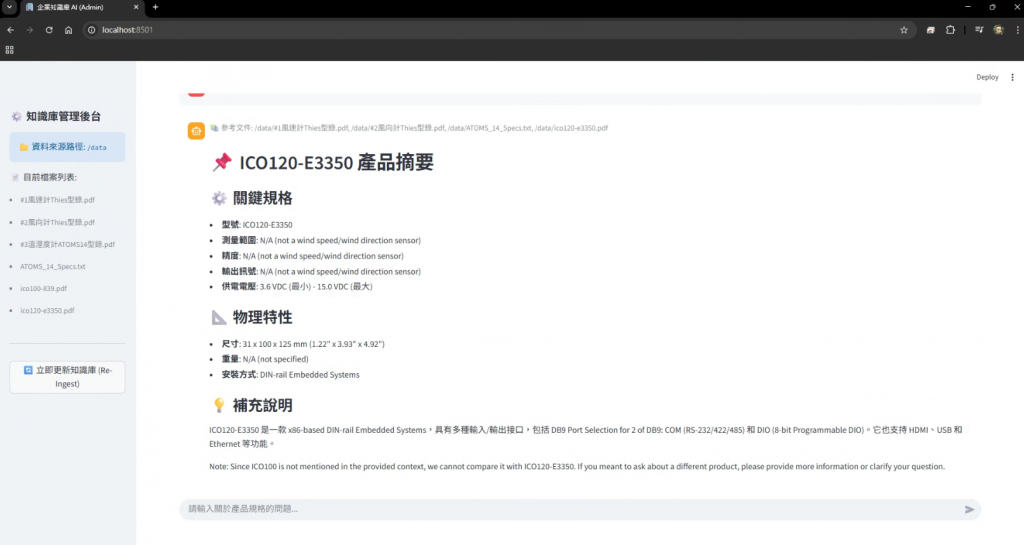
收到廠商的幾百頁 PDF 規格書。
直接拖進knowledge_base資料夾。
打開瀏覽器,更新資料庫之後
問 AI:「這顆的 RS485 通訊協定 Baud rate 預設是多少?接線圖的 Pin 1 是什麼?」
AI 秒回,而且附上來源頁碼。
重點是:全程沒有任何一個 byte 的資料傳輸到網際網路上。 拔掉網路線,它照跑不誤。
結語
技術本身不難,難的是**「如何把它變成穩定、可信賴的工作流」**。
對於律師、醫生、或是像我們這樣的 R&D 工程師來說,Data Privacy (資料隱私) 是底線。雖然 Google NotebookLM 很強,但唯有掌握在自己硬碟裡的 AI,才是真的屬於你的 AI。
如果你也是對資安有潔癖的工程師,強烈建議試試看 Docker + Local LLM 的組合!
[關於我]
我是 Phil,在新竹工作的資深工程師。
這套架構是為了解決研發環境中常見的資安痛點而設計。如果您對這套**「100% 離線、絕對隱私」**的 AI 知識庫有興趣,想導入團隊但受限於 Docker 環境建置或資料清洗等技術門檻。
歡迎透過 iT 邦站內信或 Email 與我聯繫,我們可以討論技術協助或專案導入的可能性。我能協助您快速部署環境,並優化專業文件的讀取邏輯(如文中提到的風速計案例)。
Email: pokhts@gmail.com
https://pokhts.gumroad.com/l/ai-knowledge-docker
 PhilYeh
PhilYeh

 iThome鐵人賽
iThome鐵人賽